设计师们往往对于新出的绘画工具上手比较艰难,本文针对目前比较火热的Stable Diffusion+ControlNet指导AI艺术设计的工具使用进行全面讲解。很多人会有预感,未来要么设计师被图形学程序员取代,要么会使用AI工具的设计师取代传统设计师,2023年开始,AI辅助设计甚至主导设计已经成了司空见惯的现象。
软硬件环境:
OS: Ubuntu 20.04(Stable Diffusion开发需要Linux 环境,纯使用Web工具也可在WIndows下运行)
CPU: AMD5800 8core 16Thread
GPU: NVIDIA RTX 3090 * 2
RAM: 16GB * 4
Pytorch-gpu=1.13
CUDA=11.7
一. 背景知识
1.1 Stable Diffusion背景知识
1.1.1 安装stable-diffusion-webui
由于笔者的系统为Linux ,因此需要按照官网(https://github.com/AUTOMATIC1111/stable-diffusion-webui)的操作进行以下配置:
# Debian-based:
sudo apt install wget git python3 python3-venv
bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh)
下载好stable-dffusion-webui后,还需要单独安装gfpgan 包(https://gitcode.net/mirrors/TencentARC/GFPGAN?utm_source=csdn_github_accelerator),安装方式如下:
git clone https://github.com/TencentARC/GFPGAN.git
cd GFPGAN
# Install basicsr - https://github.com/xinntao/BasicSR
# We use BasicSR for both training and inference
pip install basicsr
# Install facexlib - https://github.com/xinntao/facexlib
# We use face detection and face restoration helper in the facexlib package
pip install facexlib
pip install -r requirements.txt
python setup.py develop
# If you want to enhance the background (non-face) regions with Real-ESRGAN,
# you also need to install the realesrgan package
pip install realesrgan
安装好后将GFPGAN 目录放在stable-diffusion-webui 目录下,同时改名为gfpgan ,注意,这里如果不修改名字这个包将不可用。
然后运行以下命令并等待自动安装好其他环境依赖包:
./webui.sh
这里安装requirements.rxt中的内容可能需要等待一段时间:
1.2 ControlNet 背景知识
二. 使用方法
目前开放AI+艺术设计工具的方式多为Web交互界面,接入互联网后调用AI公司内部的云GPU服务器,服务器计算后返回结果给用户。其大多有次数或功能限制,或者收费较高。本部分讲述如何利用本地GPU工作机进行Web交互式AI绘图。
2.1 环境配置
下载以下四个源代码/模型文件:
-
主要使用的SD的Web版本(第三方,非官方):
stable-diffusion-webui
-
下载SD官方的v1.5模型:
runwayml/stable-diffusion-v1-5 -
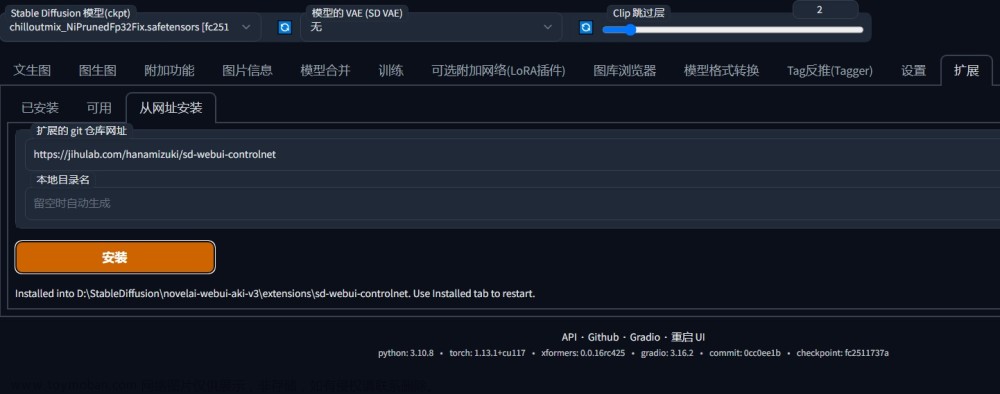
下载ControlNet的Web版本(第三方,非官方):
Mikubill/sd-webui-controlnet -
下载ControlNet官方发布的模型:
lllyasviel/ControlNet/tree/main/models
下载好后首先进入stable-diffusion-webui 中,注意将 Mikubill/sd-webui-controlnet 的源代码放在 extensions 目录下面:

将下载好的ControlNet源代码目录中的models 复制到extensions 下面:

2.2 运行WebUI
在命令行中执行脚本(注意不要使用sudo命令,否则会不成功):
./webui.sh
接下来脚本自动进行环境安装和模型加载。加载完毕后会返回一个本地Web网址,访问这个网址可以进行本地浏览器界面交互:
复制url,打开浏览器,即可得到带有ControlNet功能的SD的WebUI交互界面,可以利用界面上面的组件进行本地的快速交互设计开发。
三. 背景知识
3.1 Stable Diffusion参数详解
Sampling method: 采样方法
Sampling steps:采样迭代步数
Restore faces: 面容修复
Tiling: 生成平铺纹理
Highres.fix: 高分辨率修复
Firstpass width: 一开始的低分辨率的宽
Firstpass height: 一开始的低分辨率的高
CFG scale: 数值越小,AI多样性越多,越大限制越多
Seed: 种子数
Variation seed: 在原来种子数的基础之上的子种子数
Denoising strength:跟原来图片的差距大小
3.2 ControlNet 参数详解
-
2D重绘
Canny Edge
HED Boundary
M-LSD Lines
Faske Scribbles -
专业领域
Depth Map
Normal Map
Semantic Segmentation
Human Pose
四. 定制化技巧
4.1 参数技巧
深度真人LoRa模型训练建议:
使用和LoRa一样的底模(大模型); 最好使用和LoRa作者相同的参数;正确设置loRa的权重(0.8~0.9, <1);提示词中要加入触发词;LoRa不是越多越好。
1、训练总数:建议50张图数据集深度训练15000次左右,更大数据集可用Dadaptation优化器测试最佳总步数。
2、训练轮次:建议10/5次预设,每个图建议单轮训练20~30次。
3、训练分辨率:建议768x1024,根据电脑显存调整。
4、训练源模型:建议chilloutmix_NiPnjnedFp32Fix, 1.5模型。
5、Text Encoder learning rate (文本编码器学习率):主要影响鲁棒性、泛化性和拟合度,过低不利于更换特征。
6、Unet learning rate (Unet学习率):主要影响模型像与不像,影响lost率和拟合度,不拟合加大,过拟合减小。
7、文本编码器学习率和Unet学习率的关系:没有必然的1/5~1/10倍率关系、庞大数据集下Unet甚至可以低过Text。
8、Network Rank (Dimension”网络大小):强化训练细节,建议128〜192,128以上增加提升相对不明显。
9、Network Alpha (网络Alpha):建议96以上,弱化训练细节,有正则化效果,可与Dim同步增加。
10、让AI训练AI:首发训练采用Dadaptation,所有学习率均设为1。
1k手动训练方法:建议用AadmW优化器,可以通过调整学习率获得很像与易用性的平衡。
12、lost率控制:不是越低越好,越低模型越拟合,但模型也越难更换特征,甚至会影响动作和表情。
13、Lion优化器:不建议用在深度训练中,太快拟合虽然能很像,但是造成泛用性差。
14、本地深度训练方法:可以用远程操作软件监控,训练过程中发现学习率不合适远程修改。
五. 参考来源
如何训练一个非常像的真人Lora模型(深度探讨)
[2023最新]LORA安装和训练指南文章来源:https://www.toymoban.com/news/detail-465194.html
还搞不定lora训练集吗?干货分享+打标讲解文章来源地址https://www.toymoban.com/news/detail-465194.html
到了这里,关于Stable Diffusion+ControlNet+Lora 指导AI+艺术设计的WebUI全流程使用教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![这二维码也太美了吧!利用AI绘画[Stable Diffusion的 ControlNet]生成爆火的艺术风格二维码](https://imgs.yssmx.com/Uploads/2024/02/695127-1.png)