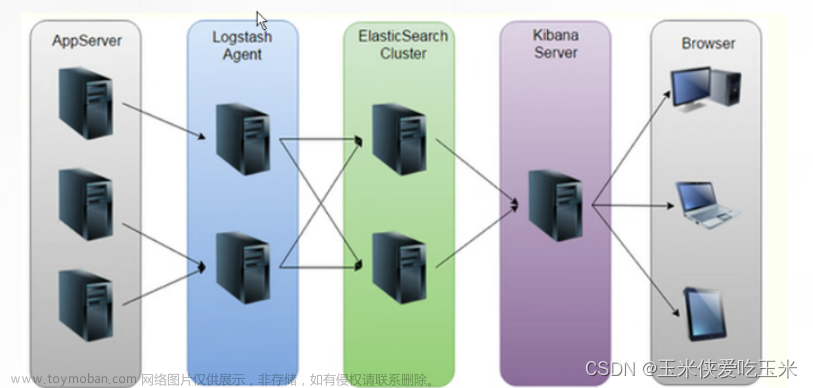
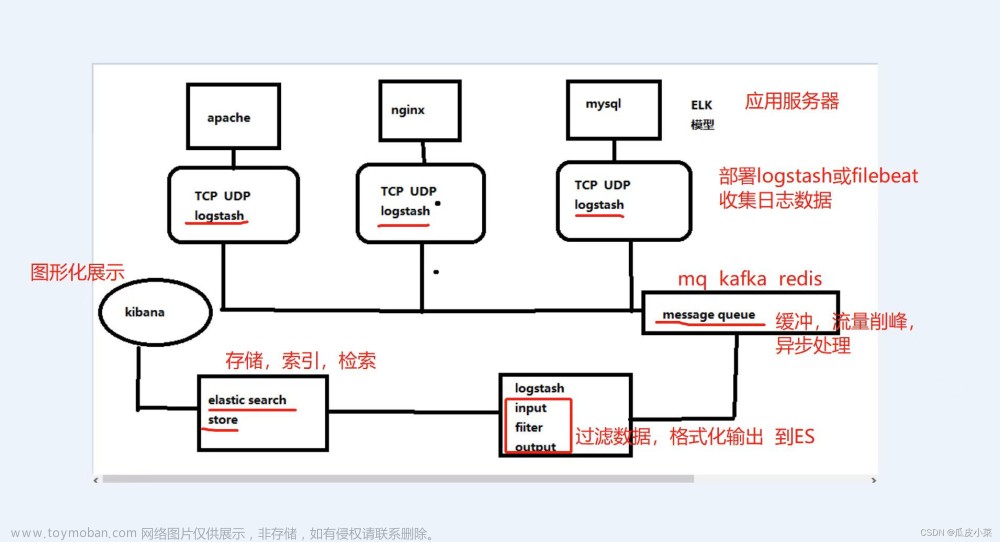
主机部署应用:
| 主机 | ip | 角色 |
|---|---|---|
| k8s1 | 192.168.56.171 | cerebro |
| server1 | 192.168.56.11 | elasticsearch |
| server2 | 192.168.56.12 | elasticsearch |
| server3 | 192.168.56.13 | elasticsearch |
| server4 | 192.168.56.14 | logstash |
| server5 | 192.168.56.15 | kibana |
一、elasticsearch
elasticsearch简介:
Elasticsearch 是一个开源的分布式搜索分析引擎,建立在一个全文搜索引擎库Apache Lucene基础之上Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎:
一个分布式的实时文档存储,每个字段 可以被索引与搜索
一个分布式实时分析搜索引擎
能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
基础模块
cluster: 管理集群状态,维护集群层面的配置信息。
alloction: 封装了分片分配相关的功能和策略。
discovery: 发现集群中的节点,以及选举主节点。
gateway: 对收到master广播下来的集群状态数据的持久化存储indices: 管理全局级的索引设置
http:允许通过JSON over HTTP的方式访问ES的APItransport: 用于集群内节点之间的内部通信。engine: 封装了对Lucene的操作及translog的调用
elasticsearch应用场景:
信息检索
日志分析
业务数据分析
数据库加速
运维指标监控
官网: https://www.elastic.co/cn/
软件下载:
https://elasticsearch.cn/download
安装软件
#rpm -ivh jdk-8u171-linux-x64.rpm
#rpm -ivh elasticsearch-7.6.1.rpm //7.6版本自带jdk,直接安装即可
1.集群部署
文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.6/index.html
下载:https://elasticsearch.cn/download/
配置解析 :
时间同步:之前已做
[root@server1 elasticsearch]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.56.11 server1
192.168.56.12 server2
192.168.56.13 server3
192.168.56.14 server4
192.168.56.15 server5
192.168.56.16 server6
软件安装:下载rpm包后进行安装
[root@server1 ~]# rpm -ivh elasticsearch-7.6.1-x86_64.rpm
修改配置
[root@server1 ~]# cd /etc/elasticsearch/
[root@server1 elasticsearch]# vim elasticsearch.yml
cluster.name: my-es ##集群名字
path.data: /var/lib/elasticsearch ##数据目录
path.logs: /var/log/elasticsearch ##日志
bootstrap.memory_lock: true ##内存锁定,根据jvm.option定义,锁死1G内存
network.host: 0.0.0.0 ##监听本机所有接口
http.port: 9200 ##端口
discovery.seed_hosts: ["server1", "server2", "server3"] ##启用集群后,需添加集群主机名
cluster.initial_master_nodes: ["server1", "server2", "server3"] ##哪些节点可以作为master做初始化
修改系统限制:
原因是:kernel>system>app,系统层面需满足要求
[root@server1 ~]# vim /etc/security/limits.conf ##加到文件最后
elasticsearch soft memlock unlimited ##内存锁定
elasticsearch hard memlock unlimited ##内存锁定
elasticsearch - nofile 65535 ##文件描述
elasticsearch - nproc 4096 ##进程数
[root@server1 ~]# vim jvm.options
-Xms1g
-Xmx1g
Xmx设置不超过物理RAM的50%,以确保有足够的物理RAM留给内核文件系统缓存。但不要超过32G
物理机内存很大的时候,可以在一台物理机完成集群的搭建!!
[root@server1 ~]# vim /usr/lib/systemd/system/elasticsearch.service
[service]
...
LimitMEMLOCK=infinity
[root@server1 ~]# systemctl daemon-reload
[root@server1 ~]# swapoff -a
[root@server1 ~]# vim /etc/fstab
#/dev/mapper/rhel-swap swap swap defaults 0 0
[root@server1 ~]# systemctl daemon-reload
[root@server1 ~]# systemctl enable --now elasticsearch
显示下图,即完成配置: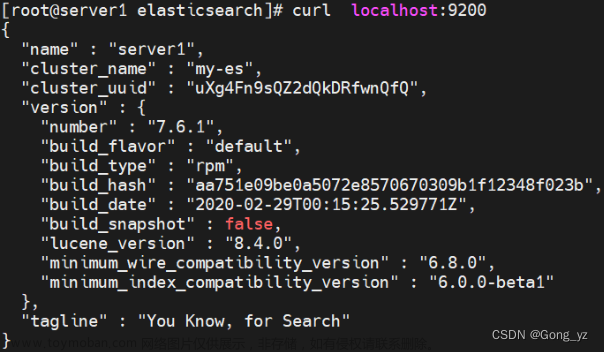
server1配置好后,直接把配置复制到server2和server3
配置ssh免密
[root@server1 elasticsearch]# ssh-keygen
[root@server1 elasticsearch]# ssh-copy-id server2
[root@server1 elasticsearch]# ssh-copy-id server3
复制软件
[root@server1 ~]# scp elasticsearch-7.6.1-x86_64.rpm server2:
[root@server1 ~]# scp elasticsearch-7.6.1-x86_64.rpm server3:
server2和server3软件安装
[root@server2 ~]# rpm -ivh elasticsearch-7.6.1-x86_64.rpm
[root@server3 ~]# rpm -ivh elasticsearch-7.6.1-x86_64.rpm
从server1复制配置
[root@server1 ~]# cd /etc/elasticsearch/
[root@server1 elasticsearch]# scp elasticsearch.yml server2:/etc/elasticsearch/
[root@server1 elasticsearch]# scp elasticsearch.yml server3:/etc/elasticsearch/
[root@server1 elasticsearch]# scp /etc/security/limits.conf server2:/etc/security/
[root@server1 elasticsearch]# scp /etc/security/limits.conf server3:/etc/security/
[root@server1 elasticsearch]# scp /usr/lib/systemd/system/elasticsearch.service server2:/usr/lib/systemd/system/
[root@server1 elasticsearch]# scp /usr/lib/systemd/system/elasticsearch.service server3:/usr/lib/systemd/system/
server2上启动服务
[root@server2 ~]# swapoff -a
[root@server2 ~]# vim /etc/fstab
#/dev/mapper/rhel-swap swap swap defaults 0 0
[root@server2 ~]# systemctl daemon-reload
[root@server2 ~]# systemctl enable --now elasticsearch
server3上启动服务
[root@server3 ~]# swapoff -a
[root@server3 ~]# vim /etc/fstab
#/dev/mapper/rhel-swap swap swap defaults 0 0
[root@server3 ~]# systemctl daemon-reload
[root@server3 ~]# systemctl enable --now elasticsearch

2.cerebro部署
cerebro:cerebro一款全能的ES工具,安装配置简单,功能强大;可以监控集群、配置集群、操作ES数据;
需要docker,用之前实验的k8s1节点即可
cerebro官方:https://github.com/lmenezes/cerebro/
使用docker启动服务
[root@k8s1 ~]# docker pull lmenezes/cerebro
[root@k8s1 ~]# docker run -d --name cerebro -p 9000:9000 lmenezes/cerebro ##docker run -d -e CEREBRO_PORT=8080…可以修改监听端口
访问网页:http://192.168.56.171:9000/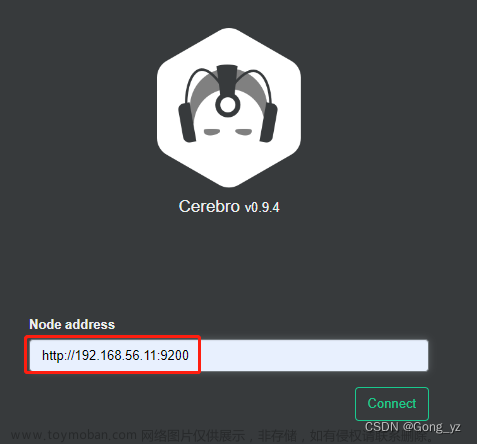
注:节点地址可以填写任意ES集群节点ip都行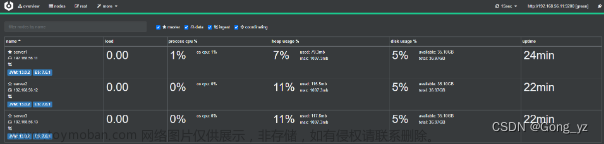
3.elasticsearch集群角色分类
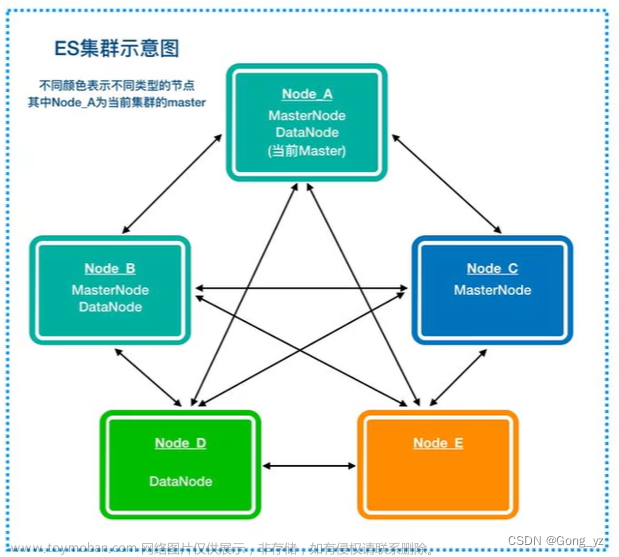
防止脑裂,将功能角色分开,有利于集群稳定
生产集群中可以对这些节点的职责进行划分:
- 建议集群中设置3台以上的节点作为master节点,这些节点只负责成为主节点,维护整个集群的状态。
- 再根据数据量设置一批data节点,这些节点只负责存储数据,后期提供建立索引和查询索引的服务,这样的话如果用户请求比较频繁,这些节点的压力 也会比较大。
- 所以在集群中建议再设置一批协调节点,这些节点只负责处理用户请求实现请求转发,负载均衡等功能。
节点需求 - master节点:普通服务器即可(CPU、内存 消耗一般)·data节点:主要消耗磁盘、内存。
path,data: data1data2,data3这样的配置可能会导致数据写入不均匀,建议只指定一个数据路径,磁盘可以使用raid0阵列,而不需要成本高的ssd。 - Coordinating(协调)节点: 对cpu、memory要求较高。
[root@server1 ~]# vim /etc/elasticsearch/elasticsearch.yml
node.master: true ##master
node.data: false ##不存数据
node.ingest: true ##预处理
node.ml: false ##ml
[root@server1 elasticsearch]# systemctl restart elasticsearch.service
[root@server2 ~]# vim /etc/elasticsearch/elasticsearch.yml
node.master: true
node.data: true
node.ingest: false
node.ml: false
[root@server2 ~]# systemctl restart elasticsearch.service
[root@server3 ~]# vim /etc/elasticsearch/elasticsearch.yml
node.master: true
node.data: true
node.ingest: false
node.ml: false
[root@server3 ~]# systemctl restart elasticsearch.service
server2对应的功能查询如下: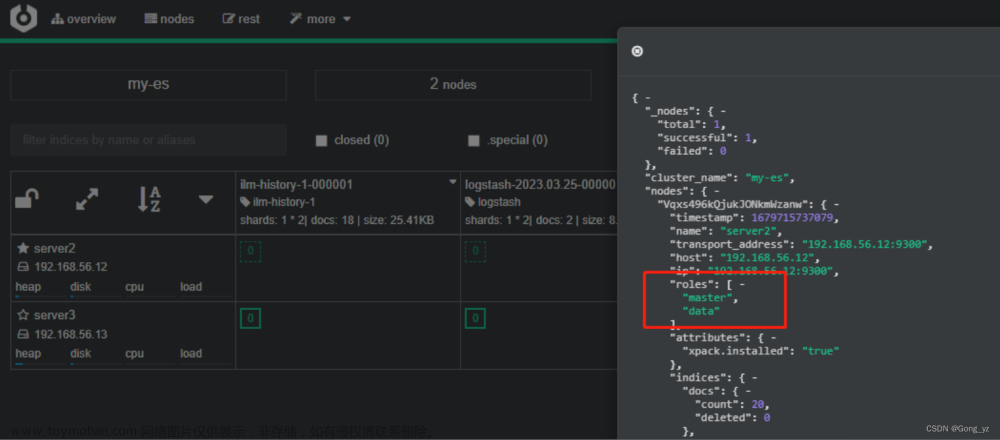
4.elasticsearch节点扩容、节点缩容


二、logstash
介绍:
Logstash是具有实时流水线能力的开源的数据收集引擎。Logstash可以动态统一不同来源的数据,并将数据标准化到您选择的目标输出。它提供了大量插件,可帮助我们解析,丰富,转换和缓冲任何类型的数据。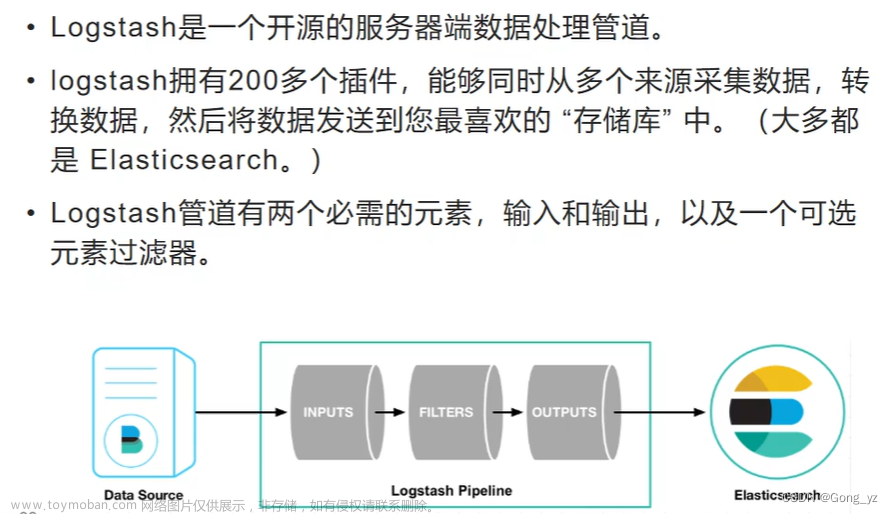
1.部署
版本需要保持一致
下载:https://elasticsearch.cn/download/
新建一台虚拟机server4部署logstash
[root@server4 ~]# yum install -y jdk-11.0.15_linux-x64_bin.rpm ##Java开发,新机要安装jdk
[root@server4 ~]# yum install -y logstash-7.6.1.rpm
命令方式
[root@server4 bin]# /usr/share/logstash/bin/logstash -e 'input { stdin { } } output { stdout {} }' ##不报错就OK
2.elasticsearch输出插件
[root@server4 conf.d]# pwd
/etc/logstash/conf.d
[root@server4 conf.d]# vim test.conf
input {
stdin { }
}
output {
stdout {} ##终端输出也展示:westos Linux
elasticsearch { ##往ES
hosts => "192.168.56.11:9200" ##输出到的ES主机与端口
index => "logstash-%{+YYYY.MM.dd}" ##定制索引名称,年月日,每天截断一次;可以支持列表格式
}
}
[root@server4 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf
##-e命令行 -f文件
##有报错,直接报错至终端屏幕
##实际中启动后,防止后台即可,自动读取目录
启动成功后录入数据,ctrl+c可退出
可以看到索引,但是看不到具体内容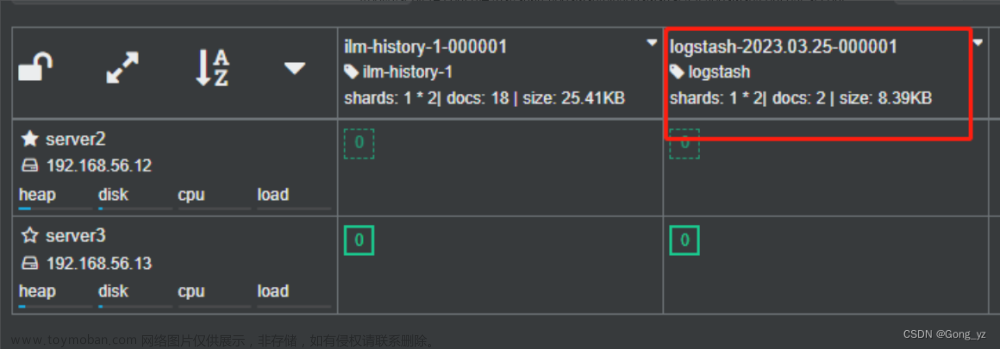
3.elasticsearch-head插件:带数据浏览
下载网址:https://github.com/mobz/elasticsearch-head
安装依赖
[root@k8s1 ~]# yum install -y bzip2
[root@k8s1 ~]# tar jxf phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@k8s1 ~]# cd phantomjs-2.1.1-linux-x86_64
[root@k8s1 phantomjs-2.1.1-linux-x86_64]# cp bin/phantomjs /usr/local/bin/
[root@k8s1 ~]# yum install -y fontconfig
[root@k8s1 ~]# phantomjs
phantomjs>
安装插件
[root@k8s1 ~]# rpm -ivh nodejs-9.11.2-1nodesource.x86_64.rpm
[root@k8s1 ~]# yum install -y unzip
[root@k8s1 ~]# unzip elasticsearch-head-master.zip
[root@k8s1 ~]# cd elasticsearch-head-master/
[root@k8s1 elasticsearch-head-master]# npm install --registry=https://registry.npm.taobao.org
[root@k8s1 elasticsearch-head-master]# vim _site/app.js

启动服务
[root@k8s1 elasticsearch-head-master]# npm run start &
[root@k8s1 elasticsearch-head-master]# netstat -antlp|grep :9100
tcp 0 0 0.0.0.0:9100 0.0.0.0:* LISTEN 9897/grunt
修改es配置
[root@server1 ~]# vim /etc/elasticsearch/elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
[root@server1 ~]# systemctl restart elasticsearch.service
访问:http://192.168.56.171:9100/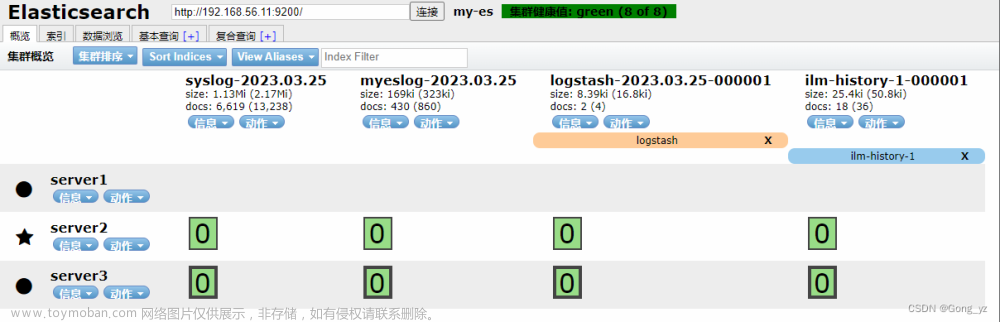
4.file输入插件
[root@server4 conf.d]# vim test.conf
input {
file {
path => "/var/log/messages" ##读取的系统文件
start_position => "beginning" ##从文件的开头开始
}
}
output {
stdout {}
elasticsearch {
hosts => "192.168.56.11:9200" ##
index => "syslog-%{+YYYY.MM.dd}" ##名字为:syslog
}
}
[root@server4 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf
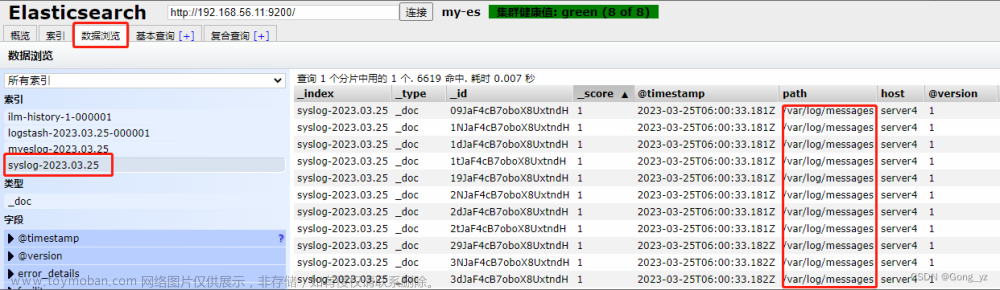
.sincedb文件保存文件读取进度,避免数据冗余读取
[root@server4 conf.d]# cd /usr/share/logstash/data/plugins/file
[root@server4 file]# l.
. .. .sincedb_452905a167cf4509fd08acb964fdb20c
[root@server4 file]# ls -i /var/log/messages
50695316 /var/log/messages
sincedb文件一共6个字段
1.inode编号(定位文件)
2.文件系统的主要设备号
3.文件系统的次要设备号
4.文件中的当前字节偏移量
5.最后一个活动时间戳(浮点数)
6.与此记录匹配的最后一个已知路径
删除后重新读取
[root@server4 file]# rm -f .sincedb_452905a167cf4509fd08acb964fdb20c
5.syslog 插件:logstash伪装成日志服务器
logstash伪装成日志服务器
[root@server4 conf.d]# vim test.conf
input {
syslog {} ##默认端口为514
}
output {
stdout {}
elasticsearch {
hosts => "192.168.56.11:9200"
index => "syslog-%{+YYYY.MM.dd}"
}
}
[root@server4 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf
配置客户端日志输出
[root@server1 ~]# vim /etc/rsyslog.conf
去掉以下行的注释
$ModLoad imudp
$UDPServerRun 514
*.* @@192.168.56.14:514 ##传送至的位置
[root@server1 ~]# systemctl restart rsyslog.service
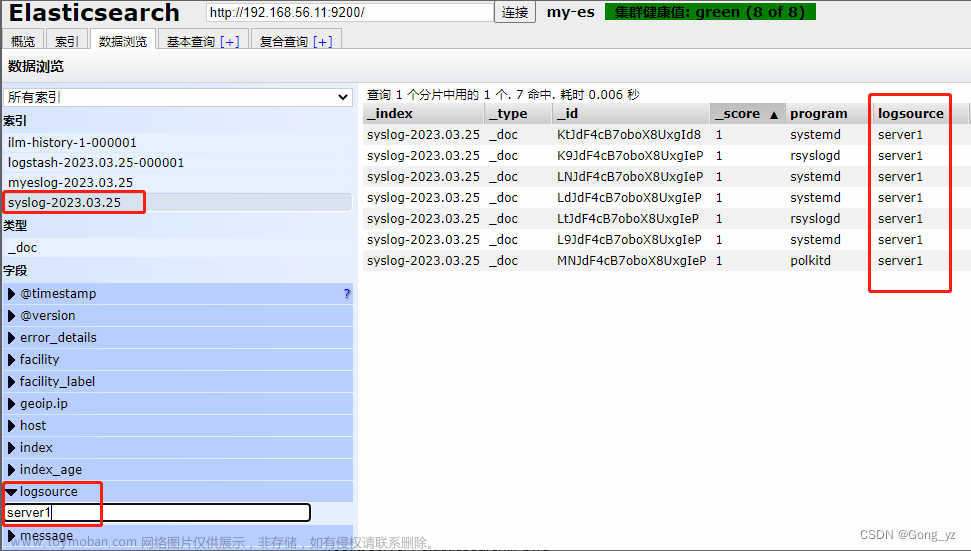
6.多行过滤插件
从server1拷贝模板文件
[root@server1 elasticsearch]# pwd
/var/log/elasticsearch
[root@server1 elasticsearch]# scp my-es.log server4:/var/log/
[root@server4 conf.d]# vim test.conf
input {
file {
path => "/var/log/my-es.log"
start_position => "beginning"
codec => multiline { ##多行
pattern => "^\[" ##匹配;[开头,\转译;错误日志不是[开头
negate => true ##匹配到了
what => previous ##向上合并
}
}
}
output {
stdout {}
elasticsearch {
hosts => "192.168.56.11:9200"
index => "myeslog-%{+YYYY.MM.dd}" ##名字myeslog
}
}
[root@server4 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf
如果第二次执行此命令,需要删除下面目录下对应的文件
[root@server4 conf.d]# cd /usr/share/logstash/data/plugins/file
一个事件输出为一个:如下图,错误的是不“[”开头,则两个[ ]输出为一条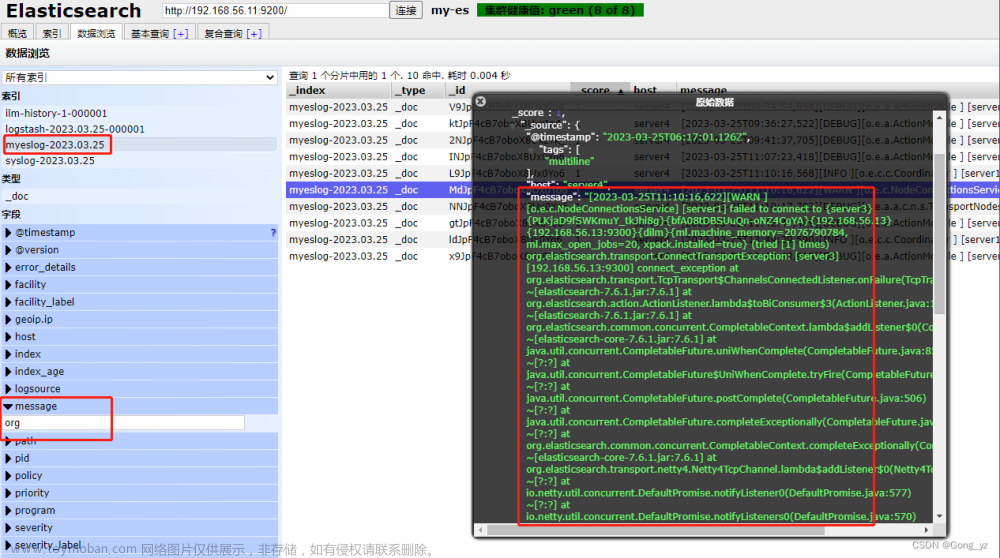 文章来源:https://www.toymoban.com/news/detail-465261.html
文章来源:https://www.toymoban.com/news/detail-465261.html
7.grok过滤
[root@server4 ~]# yum install -y httpd
[root@server4 ~]# systemctl enablel --now httpd
[root@server4 ~]# echo www.westos.org > /var/www/html/index.html
访问此站点生成日志信息
[root@k8s1 ~]# ab -c1 -n 300 http://192.168.56.14/index.html
[root@server4 conf.d]# vim grok.conf
input {
file {
path => "/var/log/httpd/access_log" ##http日志
start_position => "beginning"
}
}
filter {
grok { ##预处理、过滤; HTTPD_COMBINEDLOG是变量
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
}
}
output {
stdout {} ##作用是终端输出
elasticsearch {
hosts => "192.168.56.11:9200"
index => "apachelog-%{+YYYY.MM.dd}" ##apachelog名称
}
}
[root@server4 conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/grok.conf
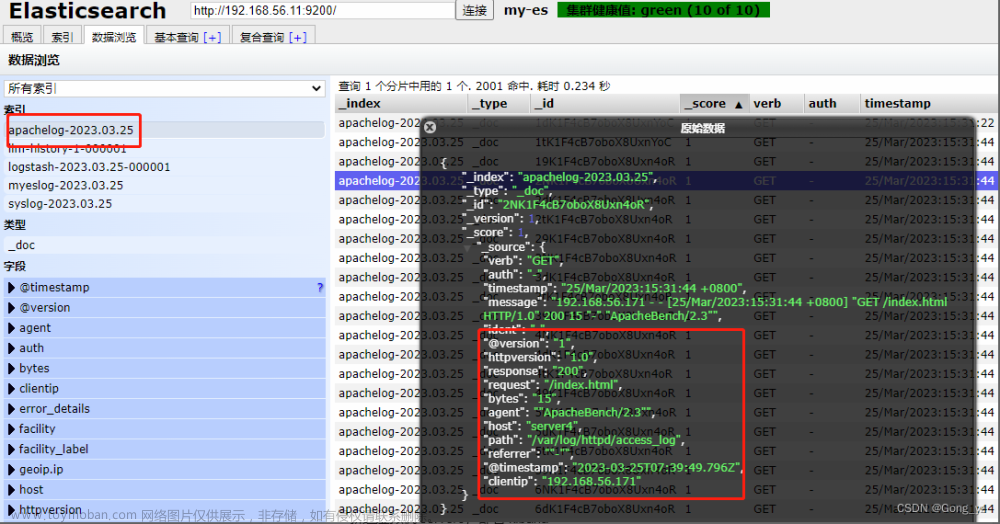 文章来源地址https://www.toymoban.com/news/detail-465261.html
文章来源地址https://www.toymoban.com/news/detail-465261.html
到了这里,关于ELK企业级日志分析平台(一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[ELK] ELK企业级日志分析系统](https://imgs.yssmx.com/Uploads/2024/01/810686-1.png)