介绍什么是ChatGLM-6B
下面是官方原话, 选择他的原因完全是因为可以消费级电脑上使用,更强的130B模型看https://github.com/THUDM/GLM-130B
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有62亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客。
为了方便下游开发者针对自己的应用场景定制模型,我们同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
不过,由于 ChatGLM-6B 的规模较小,目前已知其具有相当多的局限性,如事实性/数学逻辑错误,可能生成有害/有偏见内容,较弱的上下文能力,自我认知混乱,以及对英文指示生成与中文指示完全矛盾的内容。请大家在使用前了解这些问题,以免产生误解。更大的基于 1300 亿参数 GLM-130B 的 ChatGLM 正在内测开发中。
为与社区一起更好地推动大模型技术的发展,我们同时开源 ChatGLM-6B 模型。ChatGLM-6B 是一个具有62亿参数的中英双语语言模型。通过使用与 ChatGLM(chatglm.cn)相同的技术,ChatGLM-6B 初具中文问答和对话功能,并支持在单张 2080Ti 上进行推理使用。具体来说,ChatGLM-6B 有如下特点:
- 充分的中英双语预训练: ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
- 优化的模型架构和大小: 吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
- 较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
- 更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
- 人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
Torch
torch测试, False说明驱动还没好, 进入python命令行
# cuda支持检查
import torch
print(torch.cuda.is_available())
https://pytorch.org/get-started/previous-versions/
执行类似命令安装某个版本cuXXX
pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118
安装ChatGLM-6B模型
安装日期:2023-04-08
THUDM/ChatGLM-6B github
zero_nlp 这个项目入门应该不错,涉及知识点比较多
安装过程
git clone https://github.com/THUDM/ChatGLM-6B.git
(venv) [root@VM-245-24-centos ~]# cd ChatGLM-6B
python3.9 -m venv venv
source venv/bin/activate
pip3.9 install -r requirements.txt
pip3.9 install accelerate
pip3.9 install streamlit streamlit_chat
模型模型数据准备阶段
mkdir THUDM
cd THUDM
# 注意此时是没有大模型文件(比如pytorch_model-00001-of-00008.bin这种IFS文件)
git clone https://huggingface.co/THUDM/chatglm-6b
# 去清华大学镜像站下载文件
# 这里建议看这个文章中的python自动爬虫下载,亲测有效 https://aistudio.baidu.com/aistudio/projectdetail/5741753?channelType=0&channel=0
附:下载大文件的的python代码
# 文件1pytorch_model 8个文件下载----------------------------------------------------------------------------------------------------------
import requests
url1='https://cloud.tsinghua.edu.cn/d/fb9f16d6dc8f482596c2/files/?p=%2Fpytorch_model-0000'
url2='-of-00008.bin&dl=1'
save_path1='pytorch_model-0000'
save_path2='-of-00008.bin'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
# 循环获取models,总共有8个基础模型
for i in range(8):
url=url1+str(i+1)+url2
save_path=save_path1+str(i+1)+save_path2
res = requests.get(url,headers=headers)
file1 =open(save_path,'wb')
file1.write(res.content)
file1.close()
print("第{}个模型下载已完成".format(i+1))
# 文件2 ice_text 个文件下载---------------------------------------------------------------------------------------------------------------------------------
# 一开始想用wget命令抓取清华镜像的预训练模型,但一直不成功只能用爬虫方法进行get获取了
# 获取网页信息
import requests
url='https://cloud.tsinghua.edu.cn/d/fb9f16d6dc8f482596c2/files/?p=%2Fice_text.model&dl=1'
save_path='ice_text.model'
# 设置header
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
# 获取文件并写入
res = requests.get(url,headers=headers)
file1 =open(save_path,'wb')
file1.write(res.content)
file1.close()
运行Demo测试
# web_demo 的前端资源有些是google的,可能会页面打不开,推荐第二个
python3.9 web_demo.py
或者
streamlit run web_demo2.py
注意确认demo中模型路径和实际路径是否相同
Ptuning微调
THUDM/ChatGLM-6B ptuning 微调官方教程
微调代码就在THUDM/ChatGLM-6B的ptuning目录下
安装过程
进入目录
[root@VM-245-24-centos ChatGLM-6B]# cd ptuning
初始化环境
防止包冲突我这里重新初始化了
venv环境
python3.9 -m venv venv
source venv/bin/activate
pip3.9 install rouge_chinese nltk jieba datasets transformers torch icetk cpm_kernels
训练
官方示例的数据太久了(目瞪口呆,54M数据居然要11个小时),放弃了,我们准备自己的数据集
改一下train.sh的内容
PRE_SEQ_LEN=8
LR=1e-2
CUDA_VISIBLE_DEVICES=0 python3.9 main.py \
--do_train \
--train_file mydata/train.json \
--validation_file mydata/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path ../THUDM/chatglm-6b \
--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN
# --quantization_bit 4
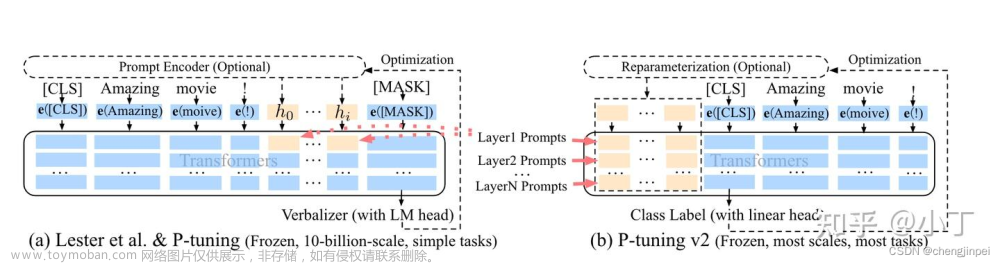
train.sh 中的 PRE_SEQ_LEN 和 LR 分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。
在默认配置 quantization_bit=4、per_device_train_batch_size=1、gradient_accumulation_steps=16 下,INT4 的模型参数被冻结,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大 per_device_train_batch_size 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
修改如下
# 我的python版本是3.9
python3 -> python3.9
# 训练文件变了,后面会创建,先改
--train_file mydata/train.json \
--validation_file mydata/dev.json \
# 修改模型的路径,模型此时已经在父目录,我们修改一下即可
--model_name_or_path THUDM/chatglm-6b \ -> --model_name_or_path ../THUDM/chatglm-6b \
# 关闭quantization_bit ,我的显卡是够的,而且quantization_bit为4我这里反而报错,所以索性关闭了,不加此选项则为 FP16 精度加载
--pre_seq_len $PRE_SEQ_LEN \ -> --pre_seq_len $PRE_SEQ_LEN
--quantization_bit 4 -> #--quantization_bit 4
准备自己的数据集
目前这个过程是自己造数据,属于
有监督学习,一问一答类型,后面研究要开始关注无监督 文字接龙 teacher forcing,Self instruction,few-shot
经过前面的折腾,我们知道格式是{“content”:"","summary":""}(看教程广告数据训练都是这个结构),一个是input,一个是output, 我们按照这个格式造数据即可(经过zy网友指导,这里对于同一个input要做到同义句泛化,要使用大量同义句,微调的效果才好)
提前准备一下泛化数据(懒得泛化的,可以直接手写自己的数据
{“content”:"","summary":""}格式大概是这样),Self instruction 这个貌似要单独学习一下,基于GPT自动泛化,作为新手这里暂时就手动自己造数据好了
mkdir mydata
vim mydata/dev.json
vim mydata/train.json
训练数据写入到dev.json(随便一条),train.json(全部)
{"content": "你叫什么名字?","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你可以告诉我你的名字吗?","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你是GPT吗","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你能告诉我你的名字吗?","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你是机器人吗?","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你能告诉我你的名字吗?","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你知道我叫啥名字吗?","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "介绍一下你自己","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "介绍自己","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你是ChatGPT吗","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "自我介绍一下","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你是?","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你知道我叫啥名字吗?","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你是谁","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你是","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你可以告诉我你的名字吗","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你是哪位","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你叫啥","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你叫什么","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
{"content": "你是谁","summary":"你好,我是小君,很高兴认识你,有什么可以帮你?"}
开始运行训练啦,(*^▽^*)
bash train.sh
这个时候才发现和训练数据的大小无关,自定义20条数据一样也是预计11个小时( ̄ェ ̄;)

整个训练过程大概11个小时
训练后的数据大小39G左右
du -sh output/
39G output/
推理
依然修改一下evaluate.sh, 我需要修改的是python版本和关闭quantization_bit
PRE_SEQ_LEN=8
CHECKPOINT=adgen-chatglm-6b-pt-8-1e-2
STEP=3000
CUDA_VISIBLE_DEVICES=0 python3.9 main.py \
--do_predict \
--validation_file mydata/dev.json \
--test_file mydata/dev.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path ./output/$CHECKPOINT/checkpoint-$STEP \
--output_dir ./output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_eval_batch_size 1 \
--predict_with_generate \
--pre_seq_len $PRE_SEQ_LEN
#--quantization_bit 4
开始推理,这次速度很快就结束
bash evaluate.sh

验证
将对应的demo或代码中的 THUDM/chatglm-6b 换成经过 P-Tuning 微调之后 checkpoint 的地址(在示例中为 ptuning/output/adgen-chatglm-6b-pt-8-1e-2/checkpoint-3000)。注意,目前的微调还不支持多轮数据,所以只有对话第一轮的回复是经过微调的。
我们修改一下web_demo2.py启动文件,使用训练后的模型,需要重新指定模型路径ptuning/output/adgen-chatglm-6b-pt-8-1e-2
# 返回ChatGLM-6B目录
cd ../
# 切换环境
source venv/bin/activate
# 修改模型 路径 THUDM/chatglm-6b --> ptuning/output/adgen-chatglm-6b-pt-8-1e-2/checkpoint-3000
vim web_demo2.py
# 启动模型
streamlit run web_demo2.py
效果展示
问题和思考
问题探讨,ISSUE542有提及https://github.com/THUDM/ChatGLM-6B/issues/542
随着对ptuning理解加深,可以发现,我很容易改变了几人的认知,但是其他知识似乎都忘记了(回答变得很奇怪了),而且还容易出现复读现象。所以在技术落地方面,我同意用来做特点的任务场景比较适合(意图识别,信息抽取等),然后再结合传统NLP技术落地应用即可。
另外,LoRA相关微调,听说也很优秀,后面再实践。
泛化学习
simbert,不属于必学
属于有监督训练
貌似这种方法是有点过时的,主流好像是利用ChatGPT做Self instruction,不过需要gpt key,这是另外一个故事了,后面再看看这个怎么玩,现在先学习理解这个过程为主
苏神的科学空间:https://spaces.ac.cn/
simbert:https://spaces.ac.cn/archives/7427
simbertv2:https://spaces.ac.cn/archives/8454
这个项目有点久没更新了,不要混着GLM在一起使用同一个环境,包依赖是会冲突的,已经踩坑了
这里要注意,不要使用太高版本的python(不是3.9,也不可以是3.6)版本,这里我用了python3.7(点击我下载),附上安装教程, 清华大学开源软件镜像站
[root@VM-245-24-centos ~]# git clone https://github.com/425776024/nlpcda.git
[root@VM-245-24-centos ~]# cd nlpcda/
python3.7 -m venv venv
source venv/bin/activate
pip3.7 install -r requirements.txt
pip3.7 install nlpcda keras==2.3.1 bert4keras==0.7.7 tensorflow==1.13.1 tensorflow-gpu==1.13.1
pip install 'protobuf~=3.19.0'
根据教程https://github.com/425776024/nlpcda下载simbert的模型, 如下图
报错
把函数名字给换一下
vim nlpcda/tools/simbert/generator.py
第46行
@AutoRegressiveDecoder.set_rtype('probas')
通过上面的百度网盘我下载了tiny的模型文件,准备下test.py
from nlpcda.tools.Simbert import Simbert
config = {
'model_path': 'chinese_simbert_L-4_H-312_A-12',
'CUDA_VISIBLE_DEVICES': '0',
'max_len': 32,
'seed': 1
}
simbert = Simbert(config=config)
sent = '把我的一个亿存银行安全吗'
synonyms = simbert.replace(sent=sent, create_num=5)
print(synonyms)
SimBERT属于有监督训练,训练语料是自行收集到的相似句对,通过一句来预测另一句的相似句生成任务来构建Seq2Seq部分,然后前面也提到过[CLS]的向量事实上就代表着输入的句向量,所以可以同时用它来训练一个检索任务。 文章来源:https://www.toymoban.com/news/detail-465596.html
文章来源:https://www.toymoban.com/news/detail-465596.html
深入学习参数使用
https://kexue.fm/archives/7427文章来源地址https://www.toymoban.com/news/detail-465596.html
到了这里,关于(二)ChatGLM-6B模型部署以及ptuning微调详细教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!