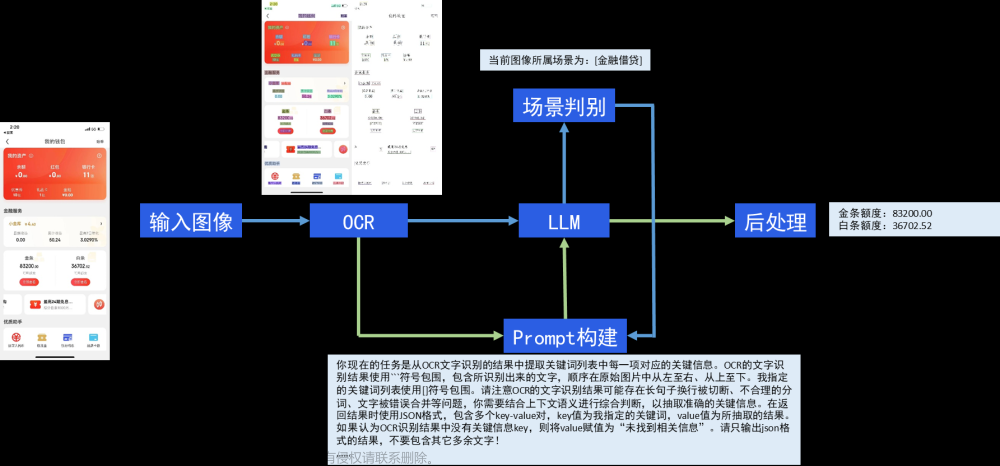
大家好,我是微学AI,今天我给大家介绍一下深度学习实战34-基于paddle关键信息抽取模型训练的全流程,我们在文档应用场景中,存在抽取关键信息的任务,比如身份证里的姓名和地址,快递单里的姓名和联系方式等等。传统的方法需要设计模板,但是这太繁琐了,也不够强健。因此,我们使用了飞桨提供的PaddleOCR工具箱中的关键信息抽取方案,可以快速地抽取增值税发票中的关键信息。下面我会手把手教大家训练paddle关键信息抽取模型。
下面我将介绍基于paddle关键信息抽取模型训练的全流程,我们按照步骤进行:
一、标注数据
1.安装软件包
pip install PPOCRLabel
2.安装后使用如下命令启动
PPOCRLabel --lang=ch --kie=True(启动 【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签)文章来源:https://www.toymoban.com/news/detail-466009.html
打开后界面如下:文章来源地址https://www.toymoban.com/news/detail-466009.html
到了这里,关于深度学习实战34-基于paddle关键信息抽取模型训练的全流程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!