1、开发需求中的树形结构
树形结构在日常开发中很常见,如:

再比如:

还有:

2、表结构设计
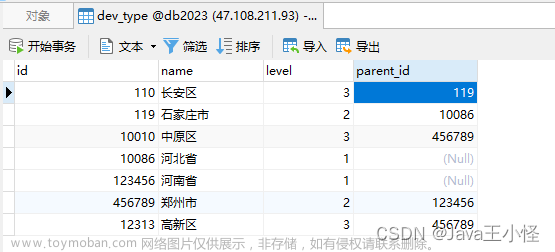
这种树形结构,其 核心字段为parentId ,即父节点id。先看上面课程信息树形结构的表设计:

精髓就是:每条数据,id是它自己的名字,parentId是它爹的名字。根据parentId能知道它爹是谁,而
它的id就是它儿子的parentId,WHERE parentId = Id就知道了它的儿子是谁。
MySQL表结构设计如下:
| 字段名 | 数据类型 | 解释 | 是否必须 |
|---|---|---|---|
| id | varchar | 主键,唯一标识这条数据,也是它子节点的parentId
|
是 |
| name | varchar | 分类中文名称,以后要展示在前端的信息 | 是 |
| parentId | varchar | 核心字段,父节点id,它爹的名字 |
是 |
| is_show | tinyint | 控制这条数据是否显示,就是逻辑删除的那个味儿 | 根据需求分析是否加,像全国省市区,自然不用 |
| orderby | int | 排序字段,同层的节点,返回时谁先谁后 | 看需求,对节点展示有顺序要求时用 |
| is_leaf | tinyint | 是否叶子节点,1是0否 | 看需求,方便后端的一个字段 |
| nodelevel | int | 层级标识字段 | 看需求,像省市区树形,这个字段可以标识下1省级2市级3区级 |
3、接口实现代码
3.1 模型类与接口定义
定义返回给前端的vo类,核心属性childrenTreeNodes
//伪代码
//假设树形结构表的PO类叫TreePo
@Data
public class TreeVo extends TreePo{
List<TreeVo> childrenTreeNodes;
}
//注意这里childrenTreeNodes类型为TreeVo,而不是TreePo,因为你儿子也有自己的儿子
随便定义个示意接口,免得突兀:
@Slf4j
@RestController
public class TreeInfocontroller{
@GetMapping("/tree/info/list")
public List<TreeVo> queryTreeNodes(){
return null;
}
}
3.2 Mapper层开发
这里以上面的行业分类树形表为例展示如何进行mapper层SQL的书写:

当树形结构的
层级固定,比如都只有两级,此时使用表的自联结查询即可完成:
# 假设表名是t_tree
# pid即核心字段parentId
SELECT
one.id one_id,
one.name one_name,
one.pid one_pid,
two.id two_id,
two.name two_name,
two.pid two_pid
FROM t_tree one
INNER JOIN t_tree two
ON one.id = two.pid
WHERE one.pid='根节点id';
# 有一条无意义数据,叫根节点,其子节点就是前端页面的第一级数据
# 有排序字段的话继续order by one.orderbyField,two.orderbyField

这就查出来了前两级:

当树形结构层级不固定,有的两级深、有的三级深,则应MySQL递归查询
WITH RECURSIVE tem_table AS(
SELECT * FROM t_tree one WHERE id='0'
UNION ALL
SELECT two.* FROM t_tree two INNER JOIN tem_table ON tem_table.id = two.pid
)
SELECT * FROM tem_table ;
# 有排序需求时后面继续order by tem_table.id......
- tem_table是一个表名
- 使用UNION ALL 不断将每次递归得到的数据加入到表tem_table中
- select * from t_tree p where id= '0’即tem_table表中的初始数据是id=0的记录,即根节点
- 通过inner join tem_table ON tem_table.id = two.pid 找到id='0’的下级节点
- 最后select * from tem_table拿递归得到的所有数据
以上是MySQL8.0的写法,再补一个MySQL5.7版本的递归写法
//传入id,返回这个id所在节点的所有子节点
delimiter $$
drop function if exists get_child_list$$
create function get_child_list(in_id varchar(10)) returns varchar(1000)
begin
declare ids varchar(1000) default '';
declare tempids varchar(1000);
set tempids = in_id;
while tempids is not null do
set ids = CONCAT_WS(',',ids,tempids);
select GROUP_CONCAT(id) into tempids from t_tree where FIND_IN_SET(pid,tempids)>0;
end while;
return ids;
end
$$
delimiter ;
两个版本的SQL递归实现参考这篇文章:https://blog.csdn.net/llg___/article/details/130908373
定义mapper接口:
public interface TreeMapper extends BaseMapper<TreePo> {
//这里返回vo类型,方便后面代码。不过是查询出来的字段没有vo中的childrenTreeNodes,那就为null
public List<TreeVo> selectTreeNodes(String id);
}
mapper.xml文件
<select id="selectTreeNodes" resultType="com.content.model.dto.TreeVo" parameterType="string">
with recursive t1 as (
select * from t_tree p where id= #{id}
union all
select t.* from t_tree t inner join t1 on t1.id = t.pid
)
select * from t1
</select>
3.3 Service层实现
到此,调用mapper接口能得到的数据结构是这样的,即List<TreeVo>,但childrenTreeNodes为null
在Service层,要做的就是把List<TreeVo>子节 的childrenTreeNodes属性处理好,也就是把节点的子节点找到,并一个个add到进其父的List<TreeVo> childrenTreeNodes属性。
//Service层接口
public interface TreeService {
public List<TreeVo> queryTreeNodes(String id);
}
Service层实现类!!继递归查询后的又一个核心操作:
@Slf4j
@Service
public class TreeServiceImpl implements TreeService {
@Autowired
TreeMapper treeMapper;
public List<TreeVo> queryTreeNodes(String id) {
List<TreeVo> poList = treeMapper.selectTreeNodes(id);
//排除根节点后,将list转map,以备后面使用
Map<String, TreeVo> mapTemp = poList.stream().filter(item->!id.equals(item.getId())).collect(Collectors.toMap(key -> key.getId(), value -> value, (key1, key2) -> key2));
//定义最终要返回的list空集合
List<TreeVo> treeVoList = new ArrayList<>();
//依次遍历每个元素,排除根节点
poList.stream().filter(item->!id.equals(item.getId())).forEach(item->{
//父节点是我们传入的id,即父节点是1,如1-1前端开发,那就塞进List
if(item.getParentid().equals(id)){
treeVoList.add(item);
}
//找到当前节点的父节点
TreeVo parentPo = mapTemp.get(item.getParentid());
if(parentPo!=null){
if(parentPo.getChildrenTreeNodes() ==null){
parentPo.setChildrenTreeNodes(new ArrayList<TreeVo>());
}
//下边开始往ChildrenTreeNodes属性的list集合中加入这个子节点
parentPo.getChildrenTreeNodes().add(item);
}
});
return treeVoList;
}
}
//实现思路总之就是,如果某条数据的pid是传入的id,则放到返回的集合中
//如果该数据的pid不是传入的id,那就找到其父节点,并将这个数据add到其父节点的List<TreeVo> childrenTreeNodes;
3.4、完善Controller层
@Slf4j
@RestController
public class TreeInfocontroller{
@Autowierd
TreeService treeService;
@GetMapping("/tree/info/list")
public List<TreeVo> queryTreeNodes(){
return treeService.queryTreeNodes("1");
}
}
返回部分结果:
{
"id" : "1-2",
"isLeaf" : null,
"isShow" : null,
"label" : "移动开发",
"name" : "移动开发",
"orderby" : 2,
"parentid" : "1",
"childrenTreeNodes" : [
{
"childrenTreeNodes" : null,
"id" : "1-2-1",
"isLeaf" : null,
"isShow" : null,
"label" : "微信开发",
"name" : "微信开发",
"orderby" : 1,
"parentid" : "1-2"
},
{
"childrenTreeNodes" : null,
"id" : "1-2-2",
"isLeaf" : null,
"isShow" : null,
"label" : "app开发",
"name" : "app开发",
"orderby" : 1,
"parentid" : "1-2"
}
]
}
4、另一种思路
最后说明下,并不是一遇见树形结构就要递归,具体怎么实现,要看具体需求。比如:
需求:返回一级二级节点信息给前端,不用返回二级节点的子节点信息

此时其实不用自连结查询也不用递归查,直接在mapper层定义一个根据pid查询所有子类List的方法,在service层调用,并将该方法的返回值set成vo的ChildrenTreeNodes即可。具体实现:
@Data
public class TreeVo extends TreePo{
//此时,不考虑二级属性的子节点,
//因此childrenTreeNodes类型为TreePo,不再用TreeVo
List<TreePo> childrenTreeNodes;
}
Mapper层代码:文章来源:https://www.toymoban.com/news/detail-466093.html
//Mapper接口
@Select("select * from tree where pid = #{pid}")
List<TreePo> selectByPid(String pid);
Controller和Service接口定义略过了,直接写Service层的接口实现的示意代码:文章来源地址https://www.toymoban.com/news/detail-466093.html
//传入根节点id,如1
public List<TreeVo> queryTreeNodes(String id){
List<TreeVo> voList = new ArrayList<>();
//一级信息,各省份数据到手
List<TreePo> poList = treeMapper.selectByPid(id);
for(TreePo po: poList){
//由省份id查就是该省的所有市级信息
List<TreePo> poTwoList = treeMapper.selectByPid(po.getId());
TreeVo vo = new TreeVo();
BeanUtils.copyProperties(po,vo);
//二级信息set进childrenTreeNodes属性
vo.setChildrenTreeNodes(poTwoList);
voList.add(vo);
}
return voList;
}
到了这里,关于树形结构的表设计与Java接口实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!