目录
1 简介
2 硬件需求
3 Demo和模型下载
3.1 安装Git LFS
3.2 Demo下载
3.3 模型下载
3.4 文件目录
4 环境安装
5 运行
5.1 FP16
5.2 量化
6 演示
1 简介
ChatGLM-6B是一个开源的、支持中英双语的对话语言模型,基于General Language Model(GLM)架构,具有62亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4量化级别下最低只需6GB显存)。ChatGLM-6B使用了和ChatGPT相似的技术,针对中文问答和对话进行了优化。经过约1T标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62亿参数的ChatGLM-6B已经能生成相当符合人类偏好的回答。
本文主要参考官方流程,在Ubuntu22.04上将ChatGLM-6B部署在本地Nvidia RTX 3080Ti Laptop GPU(16GB显存)。
2 硬件需求
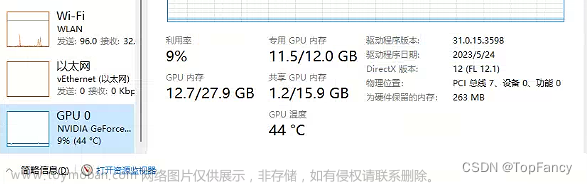
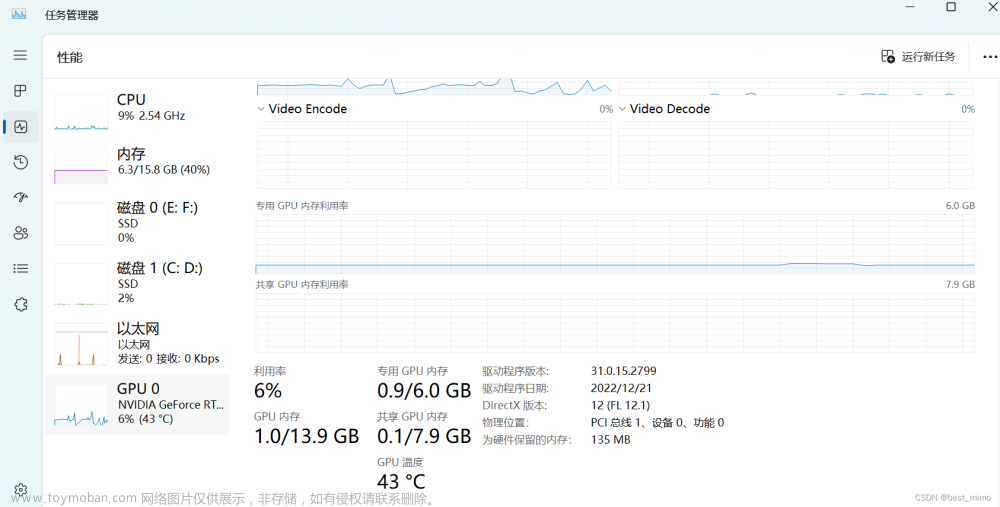
默认情况下,模型以FP16精度加载,运行上述代码需要大概13GB显存。8-bit量化下GPU显存占用约为8GB,4-bit量化下仅需6GB占用。所以理论上,只要GPU的显存在6GB以上,就可以尝试在本地部署ChatGLM-6B。
随着对话轮数的增多,对应消耗显存也随之增长,由于采用了相对位置编码,理论上ChatGLM-6B支持无限长的context-length,但总长度超过2048(训练长度)后性能会逐渐下降。
模型量化会带来一定的性能损失,经过测试,ChatGLM-6B在4-bit量化下仍然能够进行自然流畅的生成。使用GPT-Q等量化方案可以进一步压缩量化精度/提升相同量化精度下的模型性能。

3 Demo和模型下载
3.1 安装Git LFS
sudo apt install git-lfs3.2 Demo下载
mkdir THUDM
cd THUDM
git clone https://github.com/THUDM/ChatGLM-6B.git3.3 模型下载
先下载模型实现。
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm-6b再下载模型参数文件,并将下载的文件替换到本地的chatglm-6b目录下。
3.4 文件目录
Demo和模型下载完成之后的文件目录如下图所示。

4 环境安装
在Nvidia GPU上运行,安装所需的依赖包,如transformers、gradio等。
cd ChatGLM-6B
pip install -r requirements.txt5 运行
5.1 FP16
可以通过如下代码调用ChatGLM-6B模型来生成对话:
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。代码实现在ChatGLM-6B/web_demo.py,需要将下面两行代码里的模型文件路径"THUDM/chatglm-6b"修改为3.3中模型文件在本地下载后的绝对路径"/absolute-path/THUDM/chatglm-6b",否则运行时会重新从远端下载。
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()修改完成之后,直接运行以下代码即可。程序会运行一个Web Server,并输出地址。在浏览器中打开输出的地址(比如http://127.0.0.1:7860)即可使用。
python web_demo.py也可以运行以下代码在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入clear可以清空对话历史,输入stop终止程序。
python cli_demo.py5.2 量化
8-bit量化使用方法如下,4-bit量化使用方法类似。
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).quantize(8).half().cuda()量化过程需要在内存中首先加载FP16格式的模型,消耗大概13GB的内存。如果机器上内存不足的话,可以直接加载量化后的模型,INT4量化后的模型仅需大概5.2GB的内存:
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).half().cuda()6 演示
以FP16 Web Server为例演示,对话如下,有兴趣的可以自己部署体验一下。文章来源:https://www.toymoban.com/news/detail-466492.html
 文章来源地址https://www.toymoban.com/news/detail-466492.html
文章来源地址https://www.toymoban.com/news/detail-466492.html
到了这里,关于清华ChatGLM-6B本地GPU推理部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!