前言
列表,元组,字典,集合,生成器都是python中的可迭代对象,使用的时候经常忘记,通过这篇博文总结一下。
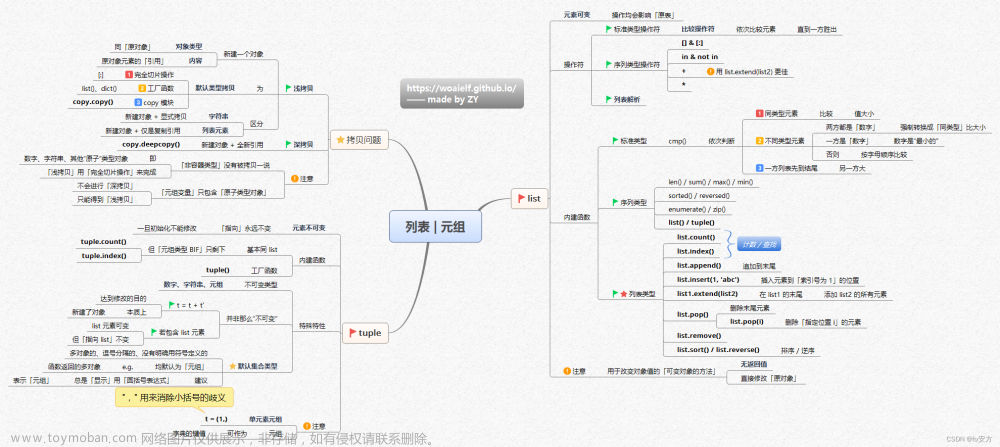
一. 列表
列表(list)是Python中的一种数据结构,它可以存储不同类型的数据。不同元素以逗号分隔。
1.1. 使用规则
- 使用方括号[]表示开始和结束。
- 不同元素以逗号分隔。
- 每个元素的排列是有序号的,元素相同但排列不同的列表属于不同的列表。
- 列表索引是从
0开始的,我们可以通过下标索引的方式来访问列表中的值。- 列表中可以存放不同类型的元素(整数,浮点数,字符串等),可以嵌套(列表,字典,集合)
1.2. 常用功能
- 遍历:
for/while循环遍历列表;- 增加:
append(),extend(),insert()分别为末尾添加一个元素,将一个列表的元素添加到另一个列表,在指定位置添加元素;- 查找:
in,not in;- 修改:指定索引修改,如
li[2] = 'a';- 删除:
del[i],pop(),remove()分别为根据下标删除,删除最后一个元素,根据元素值删除;- 排序:
li.sort(reverse=False),li = sorted(li, reverse=False)一个是对象,一个是函数实现;- 操作:
+,*,==,<,>分别用于列表的拼接,重复次数,判断是否相等,判断列表的大小(从第一个元素开始进行逐个比较,直到找到不相等的)- 嵌套:列表之间可以嵌套,如
[1,2,3,[1,2,[1,2,3]]];- 切片:如
li[:3],这一部分更详细的操作可参考我的另一篇博文:python切片操作
二. 元组
2.1. 使用规则
Python的元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。
- 使用圆括号
()表示开始和结束。- 不同元素以逗号分隔。
- 每个元素的排列是有序号的,元素相同但排列不同的元组属于不同的元组。
- 元组可以使用下标索引来访问元组中的值 。
- 元组不允许修改元组。
- 元组中只有一个元素的时候需要在最后加一个逗号
(1,)
2.2. 常用功能
由于元组是不可变类型,因此,列表中拥有的很多功能在元组中并不适用,如增删查改、排序等需要改动元组的时候都是不行的。
- 遍历:
for/while循环;- 计数:
len()用于求取元组的个数;- 切片:
tu[2:];- 转换:
tuple(li)把列表转为元组;- 操作:
+,*,==,<,>分别用于列表的拼接,重复次数,判断是否相等,判断列表的大小(从第一个元素开始进行逐个比较,知道找到不相等的)
三. 字典
字典是一种存储数据的容器,它和列表一样,都可以存储多个数据。每个元素都是由两部分组成的,分别是键和值。
3.1. 使用规则
字典使用规则:
- 使用花括号{}表示开始和结束,并且每个元素是以key:value方式成对出现。
- 不同元素以逗号分隔。
- 每个元素的排列是无序的(不支持索引),元素相同但排列不同的字典属于相同的字典。
- 根据键访问值。(注意:如果使用的是不存在的键,则程序会报错。)
- 键值唯一,字典不允许重复,如果尝试在字典中使用重复的键,则只有最后一个键值对会保留在字典中,而之前的键值对会被丢弃。键本身必须唯一。
3.2. 常用功能
- 遍历:
dicts.key(),dicts.value,dicts.items()分别表示遍历键、值、元组(键值对一个整体,可以拆开进行键值对遍历);- 增加:直接
dicts['num'] = 110或者new_dict = {"num": 110}, dicts.update(new_dict)- 删除:
del dicts['a']/del dicts,dicts.pop('a'),clear()分别表示删除元素/整个字典(删除整个字典后字典不就存在了)、删除元素并返回value值,清空字典;- 查找:使用键访问
dicts['a'],如果键不存在会报错。不确定键是否存在可以使用get()方法,num = dicts.get('num')。也可以使用in方法;- 更改:直接修改键对应的值,
dicts['a'] = 'xiaoming';- 长度:获取字典元素的个数,
len();- 键:
dicts.keys();- 值:
dicts.values();
对字典的遍历演示一下:
if __name__ == "__main__":
dicts = {'num': 110, 'name': 'xiaoming'}
print("key遍历:")
for key in dicts.keys():
print(key)
print("value遍历:")
for value in dicts.values():
print(value)
print("元素遍历:")
for item in dicts.items():
print(item)
print("键值对遍历:")
for key, value in dicts.items():
print(key, value)
# 遍历字典默认返回键
print("默认遍历返回键:")
for key in dicts:
print(key)
输出:
key遍历:
num
name
value遍历:
110
xiaoming
元素遍历:
('num', 110)
('name', 'xiaoming')
键值对遍历:
num 110
name xiaoming
默认遍历返回键:
num
name
四. 集合
4.1. 使用规则
- 使用花括号
{}表示开始和结束,并且每个元素是以单个元素方式出现。- 不同元素以逗号分隔。
- 每个元素的排列是无序的(不支持索引),元素相同但排列不同的集合属于相同的集合。
- 集合中若有重复元素,会自动删除重复值,不会报错。
4.2. 常用功能
集合中的元素是唯一的,因此集合不支持索引访问、切片、排序,修改等操作,并且集合的元素必须是不可变类型(整数,字符串,元组等),不能是可变类型(列表,字典等)。可变(Mutable)类型是指在创建后可以修改其值或内容的数据类型,而不可变(Immutable)类型是指在创建后不可修改其值或内容的数据类型,修改后地址会变化。简单理解可变不可变即修改后地址是否变化。
- 遍历:
for/while循环;- 增加:
my_set.add(6);- 删除:
remove(),discard(),clear()都是删除,第一个删除没有的元素会报错,第二个删除没有的元素不会报错,第三个是清空集合;- 查找:
in;- 长度:
len();- 集合:
|,&,-,^分别为并集、交集、差集、交叉补集。
五. 迭代器、生成器、可迭代对象
5.1. 迭代器
迭代器类型的定义:
- 当类中定义了
__next__和__iter__两个方法__iter__方法需要返回对象本身,即:self__next__方法,返回下一个数据,如果没有数据了,则需要抛出一个stopIteration的异常。
迭代器就是实现了__next__ 和 __iter__ 方法(实际使用的时候一般是缺一不可,但是python也规定了可以省略__iter__,是不是感觉很扯淡,自己规定要两个都写,有时候又可以省略,省略__iter__时不能通过for循环遍历迭代器)的对象,就叫迭代器。其中 __iter__ 方法返回迭代器自身,__next__ 方法不断返回迭代器中的下一个值,直到容器中没有更多的元素时则抛出Stoplteration异常,以终止迭代。迭代器没有长度,不可以用len来获取长度,没有len属性。迭代到最后将会抛出异常,因此不能重复迭代。看一下怎么自己创建迭代器:
# 创建迭代器类型:
class IT:
def __init__(self):
self.counter = 0
def __iter__(self):
return self
def __next__(self):
self.counter += 1
if self.counter == 3:
raise StopIteration()
return self.counter
# 实例化一个迭代器对象
obj1 = IT()
# 返回1
v1 = obj1.__next__()
# 返回2
v2 = obj1.__next__()
# 会抛出异常
# v3 = obj1.__next__()
obj2 = IT()
# 也可以直接通过内置函数next执行
a1 = next(obj2)
a2 = next(obj2)
# 抛出异常
# a3 = next(obj1)
obj3 = IT()
# 首先会执行迭代器对象的__iter__方法并获取返回值,然后一直反复的执行next方法,每次执行的结果都会赋值为item.
for i in obj3:
print(i)
输出:
1
2
5.2. 生成器
生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅。它不需要再像上面的类一样写__iter()__和 __next__方法了,只需要一个yiled关键字。也就是说,如果一个函数包含yield关键字( 不管有多少个yield ),这个函数就会变为一个生成器。yield有什么作用?
- 程序每次在代码中遇到
yield关键字后,会返回结果- 保留当前函数的运行状态,等待下一次调用,下次调用时从上一次返回
vield的语句处开始执行后面的语句。
# 创建生成器函数,定义一个函数,只要这个函数中出现了yield就是生成器。
def fun():
yield 1
yield 2
yield 3
#
for i in obj1:
print(i)
输出:
1
2
3
生成器就是一种特殊的迭代器。yield可以理解成return,一个yield执行完之后,程序就停止到这里,下次在此进来的时候从停止地方来时执行,因此上面的程序可以直接输出1,2,3。关于yield这个函数用法不理解的小伙伴可以跳转到这位大神写的博文学一下:python中yield的用法详解——最简单,最清晰的解释。关于yield更高级的用法可以移步到这个视频:Python开发编程高级进阶教程,线程通信/装饰器/迭代器/异步IO/魔术方法/反射。
send方法的作用:
- 像
next方法一样去调用生成器(调用生成器有两个方法:next方法和send方法)send方法在调用生成器时,可以同时给生成器传递数据到生成器内部
预激活生成器有两种方法:
- 直接调用
next方法来激活生成器- 调用
send(None)方法来激活生成器
5.3. 可迭代对象
从实现上看,一个可迭代对象要么有一个__iter__这个方法 ,要么有是一个sequence有__getitem__这个方法,这两者都是为了可以在iter()这个函数的作用下返回一个迭代器,而一个迭代器必须有__next__这个方法,__next__保证了他在被next()作用的时候可以返回下一个可迭代对象里面的值。
这里解释一个疑惑,如果一个对象是可迭代对象,那么这个对象可以被for循环,因为for循环的内部先执行obj.__iter__方法,他返回的是一个迭代器对象,我们知道迭代器对象是可以执行obj.__next__去取值,那么在for循环的内部是不是就基于这个迭代器对象调用它的__next__是可以帮助我们逐一去取值。这里就出现一个疑惑了,那么for循环后面为什么跟一个迭代器也可以呢?因为他如果直接去循环迭代器对象,那迭代器对象的__iter__是不是返回的是他自己还是一个迭代器对象对吧,然后再调用__next__方法,所以两者是说得通的,没毛病。
在python中可以通过iter()方法获取可迭代对象返回的迭代器,然后使用next()函数逐个获取其中的元素。当迭代器耗尽时,再次调用next()函数会引发StopIteration异常。
自己创建一个可迭代对象:
# 如果一个类中有__iter__方法且返回一个迭代器对象 ; 则我们称以这个类创建的对象为可迭代对象。
class Foo:
def __iter__(self):
return 迭代器对象/生成器对象
# 可迭代对象是可以使用for来进行循环的,在循环的内部其实是先执行__iter__方法,
# 获取其迭代器对象,然后再在内部执行这个迭代器对象的next功能,逐步取值。
obj = Foo()
for i in obj:
pass
先看个通过__getitem__创建的简单例子:
class Employee:
def __init__(self, employee):
self.employee = employee
# item是解释器帮我们维护索引值,在for循环的时候自动从0开始计数。
def __getitem__(self, item):
return self.employee[item]
emp = Employee(["zhangsan", "lisi", "wangwu"])
for i in emp:
print(i)
再看个例子:
class IT:
def __init__(self):
self.counter = 0
def __iter__(self):
return self
def __next__(self):
self.counter += 1
if self.counter == 3:
raise StopIteration()
return self.counter
# 如果类中有__iter__方法并且返回一个迭代器对象,这个创建的对象就成为可迭代对象。
class Foo:
def __iter__(self):
return IT()
# 循环可迭代对象时,内部先执行obj.__iter__并获取迭代器对象,然后在for循环内部不断地执行迭代器对象的next方法
# (区别一下迭代器是先调用__iter__方法返回自己本身,然后在调用next方法,这里是内部先执行iter方法返回迭代器对象,然后迭代器对象去调用next方法。)
obj = Foo()
for i in obj:
print(i)
输出:
1
2
基于上面的理解,我们来自己创建一个基于迭代器的range方法:
class ItRange:
def __init__(self, num):
self.num = num
self.counter = -1
def __iter__(self):
return self
def __next__(self):
self.counter += 1
if self.counter == self.num:
raise StopIteration()
return self.counter
class my_range:
def __init__(self, max_num):
self.max_num = max_num
def __iter__(self):
return ItRange(self.max_num)
for i in my_range(5):
print(i)
输出:
0
1
2
3
4
再来看一个基于生成器的自定义range方法:
class my_range:
def __init__(self, max_num):
self.max_num = max_num
def __iter__(self):
counter = 0
while counter <self.max_num:
yield counter
counter += 1
for i in my_range(5):
print(i)
输出:
0
1
2
3
4
总结:
- 迭代器:类,实现了
__iter__和__next__接口的类。- 生成器:函数,通过
yield遍历元素。- 可迭代对象:一般为数据容器,且保留 迭代接口
__iter__。
__iter__方法是留给程序获得迭代对象iter();- 获得迭代对象后,通过
__next__或next()遍历元素。
迭代器一定是可迭代对象,可迭代对象不一定是迭代器
为什么有了可迭代对象还要有迭代器?
答:
虽然可迭代对象可以通过iter()函数转换为迭代器,但迭代器的设计目的是为了提供一种惰性生成元素的方式。迭代器在每次请求元素时才会计算或生成,而不是一次性将所有元素都存储在内存中。节约了空间。
举两个例子:
# 创建一个包含大量元素的列表
large_list = [i for i in range(1000000)]
# 使用for循环遍历大型列表
for item in large_list:
process_item(item)
在上述代码中,我们直接使用for循环遍历大型列表large_list。这样做会一次性将整个列表加载到内存中,然后逐个获取列表中的元素进行处理。这种方法会在处理大型列表时占用大量的内存,特别是当列表非常庞大时。如果列表太大而无法一次性放入内存中,可能会导致内存溢出的问题。
看下使用迭代器的方法:
class LargeListIterator:
def __init__(self, large_list):
self.large_list = large_list
self.index = 0
def __iter__(self):
return self
def __next__(self):
if self.index >= len(self.large_list):
raise StopIteration
value = self.large_list[self.index]
self.index += 1
return value
# 创建一个包含大量元素的列表
large_list = [i for i in range(1000000)]
# 使用迭代器逐个获取列表中的元素
iterator = LargeListIterator(large_list)
for item in iterator:
process_item(item)
过创建
LargeListIterator的实例并将大型列表传递给它,我们可以在for循环中使用迭代器逐个处理列表中的元素,而不需要一次性将整个列表加载到内存中。这种方式可以有效地处理大型列表,节省内存并提高性能。迭代器会在需要时按需生成列表元素,而不是一次性生成整个列表。
七. zip函数
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,即返回一个zip迭代器(python2是返回一个可迭代的zip对象)。
- 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同
- 利用
*号操作符,可以将元组解压为列表。
python中常见的可迭代对象:列表,元组,字符串,字典,集合,文件对象,生成器等。可以通过下面的方法进行判断:
from collections.abc import Iterator, Iterable
l1 = [1, 2, 3, 4, 5]
print(isinstance(l1, Iterator))
print(isinstance(l1.__iter__(), Iterator))
L2 = [1, 2, 3, 4, 5]
# Iterable无法判断一个对象是否是可迭代对象,需要配合Iterator进行判断(不是迭代器,但是是一个Iterable表明是一个可迭代对象)
print(isinstance(l1, Iterable))
print(isinstance(l1.__iter__(), Iterable))
输出:
False
True
True
True
来看下zip函数怎么打包的:
list1 = [1, 2, 3, 4, 5]
list2 = ["hello", "good", "nice", "haha"]
# 集合是一个无序,无重复的可迭代对象,0=False,实际上内部按照一定逻辑对集合已经排序好了
set3 = {True, False, None, 0}
print(set3)
print('*' * 60)
zip_tup = zip(list1, list2, set3) # 打包
for i in zip_tup:
print(i)
print('*' * 60)
zip_tup = zip(list1, list2, set3)
print(next(zip_tup))
print(next(zip_tup))
print(next(zip_tup))
print('*' * 60)
print(zip_tup)
print('*' * 60)
zip_tup = zip(list1, list2, set3)
print(list(zip_tup)) # 可以将包转化为列表,查看包中的内容
输出:
{False, True, None}
************************************************************
(1, 'hello', False)
(2, 'good', True)
(3, 'nice', None)
************************************************************
(1, 'hello', False)
(2, 'good', True)
(3, 'nice', None)
************************************************************
<zip object at 0x0000027E1E353A48>
************************************************************
[(1, 'hello', False), (2, 'good', True), (3, 'nice', None)]
再来看下怎么解包:
元组通过*进行解包
"""
拆包
"""
list1 = [1, 2, 3, 4, 5]
list2 = ["hello", "good", "nice", "haha"]
# 集合是一个无序,无重复的可迭代对象,0=False,实际上内部按照一定逻辑对集合已经排序好了
set3 = {True, False, None, 0}
zip_tup = zip(list1, list2, set3) # 打包
li_zip = list(zip_tup)
print(li_zip)
print('*' * 60)
zip_tup = zip(list1, list2, set3) # 打包
for item in zip(*zip_tup):
print(item)
输出:
[(1, 'hello', False), (2, 'good', True), (3, 'nice', None)]
************************************************************
(1, 2, 3)
('hello', 'good', 'nice')
(False, True, None)
字典通过**解包,看一个函数传参的经典例子:
person = {"name": "Alice", "age": 25, "city": "New York"}
tu = (1, 2, 3, 4)
def fun(*args, **kwargs):
print(args)
print(kwargs)
fun(tu, person)
fun(*tu, **person)
# 不使用拆包需要手动拆包
fun(1, 2, 3, 4, name="Alice", age=25, city="New York")
这里提个问题:
直接定义一个l1=[1,2,3,4,5],l2=[1,2,3,4,5]打印l1,l2输出的就是列表的内容,l1,l2也是一个可迭代对象,可以直接打印内容,为什么zip(l1,l2)直接打印就不能直接输出元组呢?他的返回不也是一个可迭代对象吗?
答:
- 列表是一种可迭代对象,可以直接打印其内容。列表对象内部实现了
__iter__()方法,使其可以被迭代。当你直接打印一个列表时,Python会调用列表的__str__()方法,返回列表的字符串表示形式,其中包含了列表的内容。zip()函数返回一个迭代器,实际上是一个迭代器,用于生成元组序列。当你直接打印zip()返回的可迭代对象时,它会显示为一个类的标识符,而不是直接输出元组的内容。这是因为在Python中,打印一个对象时,默认会调用对象的__repr__()方法来显示其表示形式。
加深一下印象,我们再来看个例子:
# 将每个元组的元素作为参数传递给函数
def print_values(a, b):
print("Value of a:", a)
print("Value of b:", b)
# 使用解包操作符 * 将元组的元素作为参数传递给函数
for tuple_values in zip(l1, l2):
print_values(*tuple_values)
print("-" * 10)
# 在打印语句中输出多个值
for tuple_values in zip(l1, l2):
print(*tuple_values)
Value of a: 1
Value of b: 2
----------
Value of a: 2
Value of b: 3
----------
Value of a: 3
Value of b: 4
----------
Value of a: 4
Value of b: 5
----------
1 2
2 3
3 4
4 5
八. enumerate函数
这个函数比较简单,enumerate(iteration, start)函数默认包含两个参数,其中iteration参数为需要遍历的参数,比如字典、列表、元组等,start参数为开始的参数,默认为0(不写start那就是从0开始)。enumerate函数有两个返回值,第一个返回值为从start参数开始的数,第二个参数为iteration参数中的值。
来看个例子:
names = ["Alice", "Bob", "Carl"]
for index, value in enumerate(names):
print(f'{index}: {value}')
0: Alice
1: Bob
2: Carl
从结果上看,他返回了列表中的所有元素并且加上了索引号,默认从0开始。
九. 打包
上面简要介绍了*的用法,下面再来详细介绍下打包和解包。
在函数定义的时候,如果变量的前面加上*则表示收集所有位置参数到一个新的元组,并将整个元组赋值为新的变量args,如果变量前面加上的是**,则表示收集关键字参数到一个新的字典,并将字典赋值给变量kargs。下面分别看一个例子。
*在函数定义的时候使用:
def f(*args): # * 在函数定义中使用
print(args)
f()
f(1)
f(1, 2, 3, 4)
输出:
()
(1,)
(1, 2, 3, 4)
**在函数定义的时候使用:
def f(**kwargs): # ** 在函数定义中使用
print(kwargs)
f()
f(a=1, b=2)
输出:
{}
{'a': 1, 'b': 2}
十. 解包
解包参数和打包参数一样,也是*和**,只不过这时候*和**不是用在函数的定义的时候了,而是用在了函数的调用阶段,只有在调用阶段这两个参数才表示解包。在函数调用中,* 能够将元组或列表解包成不同的参数(打包的时候是打包成元祖,解包可以解包元祖和列表,集合)。在函数调用中,** 会以键/值的形式解包一个字典,使其成为一个独立的关键字参数。下面看几个例子。*在函数调用的时候:
def func(a, b, c, d):
print(a, b, c, d)
args = (1, 2, 3, 4)
func(*args) # * 在函数调用中使用
args = [1, 2, 3, 4]
func(*args)
args = {1, 2, 3, 4}
func(*args)
输出:
1 2 3 4
1 2 3 4
1 2 3 4
**在函数调用的时候:
def func(a, b, c, d):
print(a, b, c, d)
kwargs = {"a": 1, "b": 2, "c": 3, "d": 4}
func(**kwargs) # ** 在函数调用中使用
输出:
1 2 3 4
总结:
在函数定义时,*和**表示打包,在函数体内部,*和**表示的却是解包。看个例子:
def foo(*args, **kwargs):
print(args) # 未解包参数
print(*args) # 解包参数
v = (1, 2, 4)
d = {'a': 1, 'b': 12}
foo(v, d)
输出:
((1, 2, 4), {'a': 1, 'b': 12})
(1, 2, 4) {'a': 1, 'b': 12}
可以看到,在一开始,v,d作为整体被打包成了一个元祖,然后在解包回原来的形式。
在看一个例子:
def foo(*args, **kwargs):
print(args) # 未解包参数
print(*args) # 解包参数
print(kwargs) # 未解包参数
v = (1, 2, 4)
d = {'a': 1, 'b': 12}
foo(v, d, a=1, b=-2)
输出:文章来源:https://www.toymoban.com/news/detail-466533.html
((1, 2, 4), {'a': 1, 'b': 12})
(1, 2, 4) {'a': 1, 'b': 12}
{'a': 1, 'b': -2}
此时,v,d由*args打包,然后解包,a=1,b=-2(关键字)由**kwargs打包。文章来源地址https://www.toymoban.com/news/detail-466533.html
到了这里,关于一文详解列表,元组,字典,集合,生成器,迭代器,可迭代对象,zip,enumerate的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!