0、引入
随着ChatGPT的火热,科技公司们各显神通,针对大语言模型LLM通常需要极大的算力支持,且没有开源,阻碍了进一步的研究和应用落地。受 Meta LLaMA 和 Stanford Alpaca 项目的启发,来自加州大学伯克利分校、CMU、斯坦福大学和加州大学圣地亚哥分校的成员,共同推出了一个 Vicuna-13B 开源大模型。
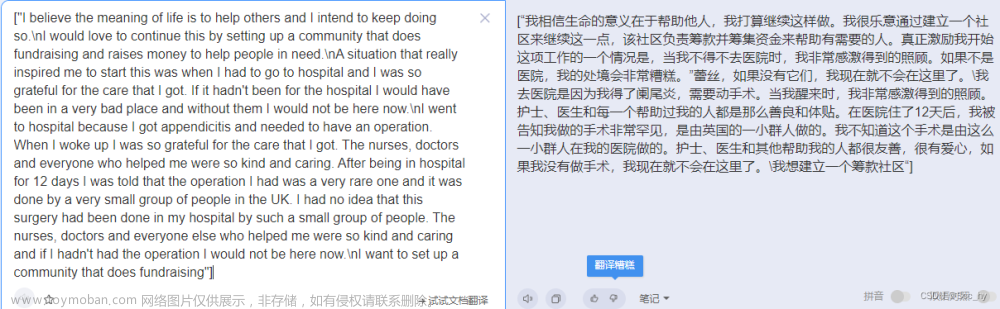
根据论文显示,其Vicuna-13B可以达到ChatGPT/Bard 90%以上水平,并且开源,并且Vicuna-7B模型可以在单卡上面运行(github说7B需要16GB的现存,亲测在3090上面可以运行,速度挺快)。
目前Vicuna开源了模型权重以供大家进行研究和微调,本文受限于算力仅尝试运行7B模型。
本文大概的流程是:首先将权重文件保存到阿里云盘中(12GB),然后在autodl云服务器中开一台3090,使用autodl提供的离线下载将阿里云盘的权重下载到3090中,然后下载Vicuna的代码进行编译安装,就可以执行测试了。
章节1-5为具体部署方法,如果觉得太麻烦,可以直接看章节6:直接使用我的镜像立即开启人机对话,通过加载镜像后两行代码就可以开启对话
1、保存权重文件到阿里云盘
官方没有直接放出权重文件,而是需要通过增量和LLM自己进行转换,转换7B的权重需要30GB的RAM才可以。所以这里直接分享转换后的权重下载即可。
vicuna-7b-小羊驼 点击链接保存到自己云盘(note:不需要下载)
2、部署环境
Vicuna最小的7B模型也需要14GB的显存,(穷,没有)所以使用autodl租一台3090,也便宜一般1~1.5一小时。选择一台3090,它拥有24GB显存,运行7B模型已经够了。
在创建时选择框架:Pytorch1.10+Py3.8+CUDA11.3
3、上传权重文件到3090
该部分在autodl的帮助下,将阿里云盘权重直接下载到3090,不需要经过本机下载再上传。
当我们开启一台机器后可以看到下面的信息
点击“AutoPanel”进入面板,选择“公网网盘”,此时选择阿里云盘并扫码登录,就可以看到你的文件了。
找到vicuna-7b文件夹(里面就是相关权重文件),点击下载。
下载完成后,该模型权重就在我们3090的/root/autodl-tmp/里了,一会儿就可以直接使用。
权重文件较大,传输比较耗时,你可以点击右上角的传输任务查看进度。
4、下载安装源码
4.1 下载编译安装源码
首先从 v0.1.10下载“Dource code(zip)”并上传。如下如所示在1标记处可以上传文件,基本的上传进度条完成后可以在左侧看到FashChat-0.1.10.zip
然后,点击“终端”打开终端,使用命令"unzip FastChat-0.1.10.zip -d ./"进行解压,成功后可以看到FastChat-0.1.10文件夹
note:不要去主页下最新版,最新版与本文的权重不符,会有小bug。
4.2 安装
首先在终端进入文件夹:cd FastChat-0.1.10
为了方便访问从github下载,请根据自己机器的区域设置代理AutoDL帮助文档
比如我的是毕业季A去所以执行:
export http_proxy=http://10.0.0.7:12798 && export https_proxy=http://10.0.0.7:12798
然后依次执行:sudo pip3 install --upgrade pip sudo pip3 install -e .
至此一切就绪!
5、开始使用
一些配置好后,在终端中执行使用命令:python3 -m fastchat.serve.cli --model-path ~/autodl-tmp/vicuna-7b/
等待加载chckpoint完成后,就会有提示符“Human:”就可以进行人机对话了
6、直接使用我的镜像立即开启人机对话
如果觉得上面的步骤太麻烦,使用我制作好的镜像,直接输入命令就可开启对话。
首先你需要获取我准备好的镜像,受限于autodl镜像分享只能通过指定id的方式,你可以在评论区留下你的autodl的ID,我分享给你。
你的id在这里查看:
假设你已经有了镜像,然后去租一台3090,在控制台将3090关机,从“更多”中选择“更换镜像”,选中我分享的镜像,等待重置完成。
开机后,一次执行:cd FastChat-0.1.10python3 -m fastchat.serve.cli --model-path vicuna-7b/
就可以开启对话了文章来源:https://www.toymoban.com/news/detail-466973.html
Debug:可能的报错

上次执行使用命令占用的显存没有释放,只需要如下图关闭该终端,然后新开终端进入FastChat文件夹后再使用执行命令即可再次对话 文章来源地址https://www.toymoban.com/news/detail-466973.html
文章来源地址https://www.toymoban.com/news/detail-466973.html
到了这里,关于LLM:Vicuna 7B模型简单部署体验的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!