hadoop课程设计报告
一、设计目的与要求
1、设计目的
通过hadoop课程设计可以加深、巩固对本门专业课程理论知识的掌握。通过eclipse和hadoop来编写课设报告等方面的实践训练,筑牢编程基础,培养良好的逻辑思维能力,提高综合运用能力。同时也锻炼学生自我管理和自我发展的能力,合理安排时间完成自己的任务,促进个人和集体良好的合作交往。
- 设计要求
基于hadoop下的mapreduce分布式系统
具体要求:
- 实现代码在hadoop下的运行
- 高考英语单词的分词统计
- 实现单词频率由高到低的排序
- 实现文件保存其hdfs下
- 图形界面化
二、设计内容
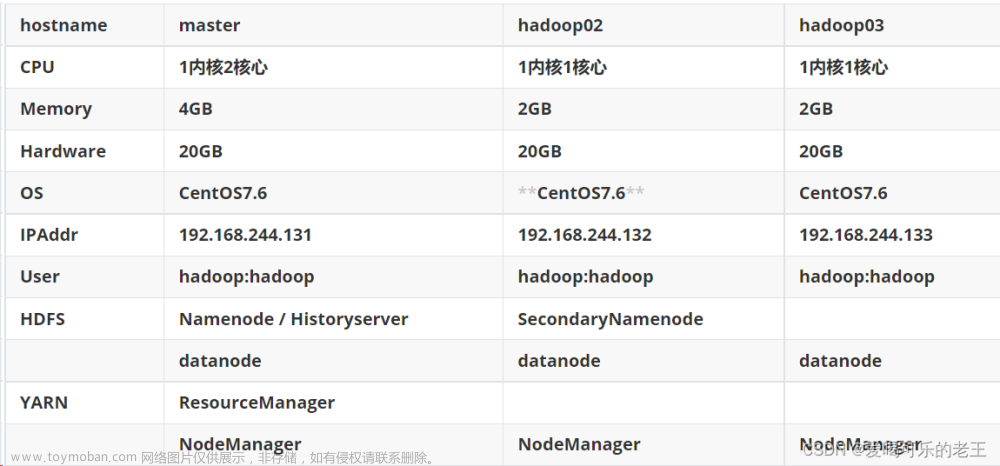
1、设计题目和环境
题目:基于hadoop下的高考英语高频词汇分析
语言:Java+Linux
环境:eclipise+Hadoop
2、设计过程与步骤
实现所涉及的文件:
- map.java:实现空格切割,冒号连接
- combine.java:对每个单词进行词频统计
- reduces.java:自定义Reduce类
- drivers.java:编写MapReduce主类
- read.java:图形界面化
- English.txt:文本文
操作过程与步骤如下:
- 将文本按照空格切割,以冒号连接,单词:文档名称作为key,单词次数作为value

图1 map.java
- 对map阶段的单词次数聚合处理,并重新设置key作为单词,value值由文档名称和词频组成

图2 combine.java
- 接收combine阶段的输出,最终案例倒排索引文件需求的样式,将单词作为key,多个文档名称和词频连接作为value,输出到目标目录

图3 reduce.java
- 设置MapReduce工作任务的相关参数,采用本地运行模式

图4 driver.java
- 图形界面化,显示最终内容

图5 reader.java

图6 reader.java
- 将Java程序打包成jar包的形式

图7 jar包
- 在hdfs下创建文件

图8 创建一个名为sigen的文件用于存放数据
- 将要分析的数据上传到hdfs中

图9 上传数据
- 在hadoop下运行jar包(其中cn.itcast.mr.invertedIndex 是java程序的package名,output是输出文件所在地)hadoop jar /export/sigen521.jar cn.itcast.mr.invertedIndex.drivers /sigen52/123.txt /sigen52/output

图10 运行
- 运行结果完成后可以查看

图11 查看结果
3、设计过程中出现的问题与解决方法
(1)问题一:图形界面设计的时候一直达不到预期的效果
解决方法:查看以前的例子,查询CSDN寻找到了灵感
(2)问题二:ecplise完成 初始代码后,不知道如何在hadoop下运行
解决方法:查询CSDN得知,在ecplise下打成jar包的形式然后在hadoop下运行
(3)问题三:在haadoop下运行hadoop jar /export/servers/Hadoop-2.7.4/12345.jar cn.itcast.mr.invertedIndex.drivers /sigen/1.txt /sigen/output 一直报错不知道什么原因
解决方法:查询资料,借助百度翻译得知hdfs下没有相应的文件,创建相应文件后,成功运行。
4、程序运行界面(或者是图表可视化结果)
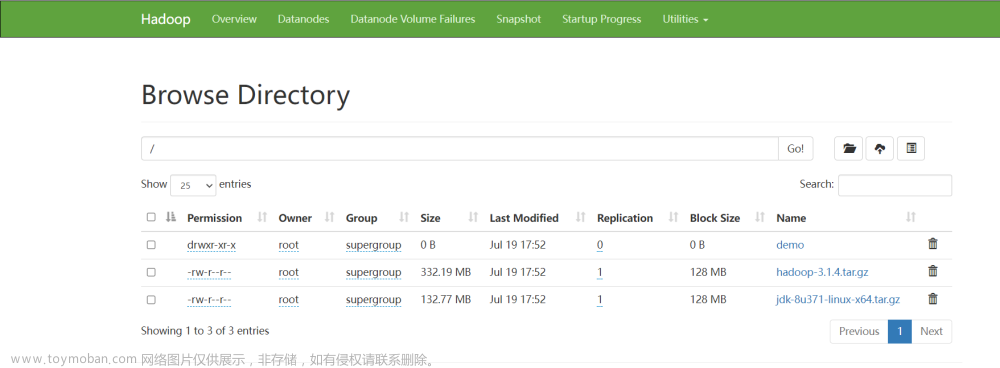
(1)程序运行后,hdfs界面

图12 文件位置
(2)图形可视化

图13 图形界面
- 设计总结
(1)通过本次大作业的学习与设计我的收获很大,将本学期所学习的知识由零零碎碎到整体实现一个大的设计有了一个清晰的认知,学会了自己去克服困难,磨练了我的意志以及加强了学习的能力,没有学到过的函数通过查阅资料请教同学也可以成功使用,同时我也对于hadoop这门课程有了更加深入的了解,喜欢上了这门课程,hadoop可以完成很多东西,在学习中也能找到自己的乐趣,经过自己的不断努力实现了代码的运行成功获取到了数据
(2)大学生活让我对爬虫有了一定的了解,但实际操作领域依旧是一片空白。纸上得来终觉浅,绝知此事要躬行。经过本次大作业,让我对自己有了新的认识,并明确了爬虫这一课程的前进方向。
(3) 1.继续学习,不断提升理论素养
在信息时代,学习是不断地汲取新信息,获得事业进步的动力。现在通过总感觉自己学的不够,要用到知识时总感觉脑袋总是空白。实习后让我明白,为了能更好的适应工作,不得不利用自己空闲时间去弥补学习中的不足。实训内容是与自己所学专业有密切联系的,所以自己在这方面格外侧重,希望能够加强自己的专业知识。
2.加强信心,坚持下去
希望能把所学习的知识,也能运用到课堂上。对自己多一点信心,多给自己点赞赏,多给自己鼓鼓劲,相信自己总会走出一条宽敞大道。
3、学习中的同学相处
感觉学生时代很美好,不仅仅是不需要去努力工作,而是在学生时代你可以有很好的同学,很好的朋友,大家相互嘘寒问暖,不必勾心斗角,同学之间互帮互助没有什么坏心思。我感觉这里才真的有纯洁的友谊,纯洁的感情。我想当踏上了社会,就会存在着利益关系,有工作繁忙,有着上下级的阶级,也多了份人情世故。希望以后自己努力,可以多几个朋友,希望自己可以有个团结工作的环境。在整个学习过程中,同学之间的关系总是那般融洽,学生时代是我们最开心的日子,为了面对以后的生活,我们现在能做的就是好好学习,掌握知识为了自己的明天祖国的未来奉献自己的一份力量。
下载地址:文章来源:https://www.toymoban.com/news/detail-467451.html
复制这段内容后打开百度网盘手机App,操作更方便哦
链接: https://pan.baidu.com/s/1u0WDtkGradU3sAEs-XbEuQ
提取码: jp2j文章来源地址https://www.toymoban.com/news/detail-467451.html
到了这里,关于基于hadoop下的使用map reduce分布式系统的高考高频词汇统计的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!