1 缘起
无意中翻阅官方文档,看到了Kubernetes中的网络模型,
于是,开始学习,分享如下。
官方文档:
网络模型https://kubernetes.io/docs/concepts/services-networking/
Servicehttps://kubernetes.io/docs/concepts/services-networking/service/
2 Kubernetes网络模型
集群中的每个Pod会在集群范围内获取自己唯一的IP地址。
因此,Pod间不需要创建链接,同样不要处理容器端口与主机端口的映射关系。
这样即构建了简洁且向后兼容的模型。
可以将Pod视为虚拟机或者物理机,比如在为Pod进行端口分配、命名、服务发现、负载均衡、应用配置和迁移。
Kubernetes在对网络实现上提出如下基本要求(禁止任何故意进行网络分段):
- Pod与其他节点的Pod进行通信无需NAT
- Node的代理(如系统进程、kublet)可以与该节点的任何Pod通信
注意:对于支持Pod运行于主机网络的平台(如Linux),当Pod获取节点的主机网络时,可以不通过NAT与所有节点的Pod通信。
该网络模型不仅仅减少全局复杂度,最重要是这种设计方式与Kubernetes的期望一样,即应用程序从虚拟机到容器平滑迁移。如果之前的任务运行于虚拟机中,那么虚拟机只要有IP即可与项目中其他虚拟机同通信。两者的基本模型是一致的。
Kubernetes的IP地址存在于Pod作用域中,包括IP地址和MAC地址(Pod中的容器共享网络命名空间),意味着Pod中的容器可以通过localhost在各自端口上相互通信,并且Pod需要管理端口的使用,这与虚拟机中的处理是一致的,称为“IP-per-pod”模型。
将Node端口的请求转发到Pod(称为主机端口),但这是非常常规的操作,如何实现转发仍然是容器运行时的处理的,Pod自身是不关心主机端口的。
3 Service
Service是将一系列Pod应用暴露为网络服务的一种方法。
Kubernetes中不需要编辑应用来使用陌生的服务发现机制,Kubernetes为Pod分配了IP地址、独立的DNS名称,通过IP和DNS名称实现Pod的负载均衡。
3.1 动机
Kubernetes中Pod的创建和销毁是为了集群的正常的运行,Pod是非持久性的资源(可以按需要创建和销毁),如果使用Deployment运行应用可以动态地创建或销毁Pod(即水平扩缩容)。
虽然每个Pod可以获取各自的IP地址,但是在Deployment中,Pod的IP地址是随时间发生变化的,即时刻A Pod的IP可能和时刻B的IP不同。
这会导致的问题:集群中如果后端Pod为前端Pod提供服务,前端如何实时跟随变化的后端IP?
答案:使用Service。
3.2 Service资源
Kubernetes中,Service是一种顶层抽象,定义了进入Pod的逻辑和策略(有时,这种模式称为微服务)。Service通过定义selector定向到Pod群组。
比如,一个无状态的镜像处理后台有3个副本,这些副本是可替代的,前端无需关心他们使用的是哪个,虽然实际的后台Pod可能会发生变更,但是,前端客户端无需感知以及实时跟踪这些Pod的变化。
Service的这种设计方式实现不同服务的Pod解耦,结构如下图所示。
不同业务间的Pod通过Service转发请求与响应。
云原生服务发现
如果应用中可以使用Kubernetes的API进行服务发现,
那么,通过API即可查询服务变更情况。
对于非原生应用,Kubernetes在应用和后端Pod间提供了配置网络端口和负载均衡的入口。
3.3 定义Service
Kubernetes中的Service是REST对象,类似于Pod,与所有REST对象一样,可以通过POST请求API来创建实例,Service对象名称需是有效的RFC 1035标签名称。
比如,假定每个Pod监听TCP端口为9376,包含标签:app=MyApp,
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
上述配置创建的Service对象名称为my-service,将请求转发到标签为MyApp、TCP端口为9376的Pod上。
Kubernetes为my-service这个服务分配IP地址(有时称为clusterIP),供Service代理使用。
控制器为Service选择器持续扫描匹配的Pod,然后向my-service提交更新信息。注意:Service可以将port映射到targetPort,为方便起见,默认将port和targetPort设为相同的值。
Pod中定义端口同时可以配置名称,根据名字可以配置Service中targetPort属性,如下配置:
在Pod中通过port名称:http-web-svc,将Servcie中的targetPort绑定到Pod中的containerPort:80。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app.kubernetes.io/name: proxy
spec:
containers:
- name: nginx
image: nginx:stable
ports:
- containerPort: 80
name: http-web-svc
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app.kubernetes.io/name: proxy
ports:
- name: name-of-service-port
protocol: TCP
port: 80
targetPort: http-web-svc
即使Service中混合多个Pod使用同一个配置名称同样是可以正常工作的,相同的网络协议使用不同的端口号,这为部署和迭代Service提供了诸多方便。比如更新Pod的可以修改暴露的端口,而无需终止客户端。默认的Service协议为TCP,也可以使用其他支持的协议,如:UDP和SCTP。
鉴于Service需要暴露多个端口,Kubernetes支持在一个Service对象中定义多个端口,每个端口的协议可以相同,也可以不同。
3.3.1 Service没有选择器
Service可以通过选择器访问Kubernetes的Pod,当使用了没有选择器的终端,Service可以抽象出其他类型的后端服务,包括集群外的服务,如:
- 生产环境使用外部数据库集群,但测试环境使用自己的数据库;
- 将自己的Service指向有不同Namespace或者其他集群的服务;
- 迁移工作负载到Kubernetes。
如上情况可以定义没有Pod选择器的Servcie,如:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
由于这个Service没有选择器,所以对应的终端对象不会自动创建。可以手动将Service映射到对应的地址和端口,手动添加如下:
apiVersion: v1
kind: Endpoints
metadata:
# the name here should match the name of the Service
name: my-service
subsets:
- addresses:
- ip: 192.0.2.42
ports:
- port: 9376
终端对象的名称必须是有效的DNS子域名。当为Service创建终端对象时,对象名称必须与Service名称一致,即metadata.name一致。注意:终端的IP不应该是:环回地址(127.0.0.0/8 for IPv4, ::1/128 for IPv6)或者链路本地地址(169.254.0.0/16 and 224.0.0.0/24 for IPv4, fe80::/64 for IPv6)。
终端IP地址不能是其他Kubernetes集群Service的IP,因为,kube-proxy不支持虚拟IP作为终点。
访问Service无需区分有无选择器。上面的例子中,流量会路由到定义的终端对象:192.0.2.42:9376(TCP协议)。
Endpoint是Service的映射对象。
注意:Kubernetes API服务禁止代理没有映射的Pod。比如执行kubectl proxy ,由于这个限制,该Service没有选择器会代理失败。这会阻止Kubernetes API服务被用于代理未授权的终端接入。
ExternalName类型的Service是一类没有选择器并且使用DNS名称的特殊Service。
3.3.2 终端过载
如果终端资源超过1000个,Kubernetes集群(版本v1.22或更高),Endpoints会使用标识:endpoints.kubernetes.io/over-capacity: truncated。该注解说明Endpoints对象过载,控制器会删除Endpoints,保持1000个。
3.3.3 Endpoint分片
Endpoint分片是API资源提供可伸缩的Endpoint。虽然概念上与Endpoint非常相似,但是,Endpoint分片允许跨资源分配网络。默认情况下,Endpoint分片达到100个即认为是满载,多余的Endpoint分片会在其他的终端中创建并存储。
3.3.4 应用协议
appProtoco属性为每个Service的端口提供了访问协议,该属性由对应的Endpooints和EndpointSlice对象进行映射。
该属性遵循Kubernetes标准标签语法,值应为IANA标准服务名称或者域名前缀名称,如mycompany.com/my-custom-protocol。
3.4 虚拟IP和服务代理
Kubernetes集群的每个节点(Node)都会运行kube-proxy,kube-proxy是Service虚拟IP的实现方式(除了ExternalName)。
3.4.1 为什么不使用round-robin域名系统
一个常见的问题是:为什么Kubernetes依赖于代理将流量转发给后端。有没有其他方案呢?
比如,是否可以配置有多个A值(或IPv6的AAAA) DNS以及依赖round-robin名称的解析?
Service使用代理的几点原因:
- DNS的实现在很长一段时间中不遵守记录TTL(存活时间)并且缓存应该过期的查询结果;
- 一些应用使用DNS搜索一次,会永久缓存该结果;
- 虽然应用和相关工具库重新解析,但是,DNS记录的低存活时间或者零存活时间会导致DNS负载增加,导致DNS最终很难管理。
3.4.2 配置
kube-proxy可以通过配置使用不同的启动模式。
- kube-proxy通过ConfigMap进行配置,ConfigMap可以有效清除无需使用的kube-proxy功能;
- CoinfigMap不支持实时重载配置;
- kube-proxy的ConfigMap参数并不是总是有效的,因为,有硬件要求。比如,你的操作系统不允许使用iptables命令,kube-proxy内核的标准实现将无法正常工作。
3.4.3 用户空间代理模式
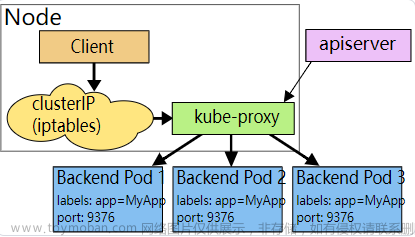
该模式下,kube-proxy监视Kubernetes控制平面中Service和Endpoint对象的添加和移除。
kube-proxy在本地节点(Node)上为每个Service开放一个随机选择的端口。
任何连接到这个“代理端口”的服务都会代理到Service的后端Pod上(通过Endpoint)。
kube-proxy Sevice根据SessionAffinity配置决定使用哪个后端Pod。
最后,用户空间代理安装iptables规则来获取流量,
流量分配被到Service的clusterIP(虚拟IP)和端口上。
kube-proxy将流量重定向到后端Pod的代理端口上,
默认情况下,kube-proxy在用户空间模式下通过round-robin算法选后端Pod,
过程如下图所示,由图可知,流量分发:traffic->clusterIP->kube-proxy->pod。
图片地址:https://d33wubrfki0l68.cloudfront.net/e351b830334b8622a700a8da6568cb081c464a9b/13020/images/docs/services-userspace-overview.svg

3.4.4 iptables代理模式
iptable代理模式中,kube-proxy通过Kubernetes控制平面监控Service和Endpoint对象的添加和移除。kube-proxy为每个Servcie安装iptable规则,将流量分配到Service的clusterIP和端口上,然后重定向到Service的后端Pod上。kube-proxy为每个Endpoint对象安装iptable规则来选择后端Pod。默认情况下,iptable模式下的kube-proxy是纯随机选择后端Pod。
该模式的架构示意图如下图所示,由图可知,流量分发:traffic->clusterIP->pod或者traffic->kube-proxy->pod。
原图地址:https://d33wubrfki0l68.cloudfront.net/27b2978647a8d7bdc2a96b213f0c0d3242ef9ce0/e8c9b/images/docs/services-iptables-overview.svg

使用iptable处理流量系统开销很小,因为Linux网络筛选器处理流量时无需进行用户空间和内核空间的切换。这种处理方式貌似更加可靠。
如果kube-proxy运行在iptable模式化下,选中的第一个Pod无响应,连接会失败。与用户空间模式不同的是:用户空间模式下,kube-proxy在第一个Pod中无法获取响应时,会自动向其他Pod发起重试请求。
可以使用就绪探针(readiness)验证后端Pod是否正常工作,因此iptable模式下kube-proxy只能观测到测试正常的后端Pod。这样意味着无需将流量通过kube-proxy分发到Pod就可以知道响应异常。
3.4.5 IPVS代理模式
ipvs模式下,kube-proxy观测kubernetes的Service和Endpoint,调用netlink接口创建对应的IPVS规则,并定期向Kubernetes的Sevice和Endpoint同步IPVS规则。该控制回环保证IPVS与期望的状态是一致的。当访问Servcie时,IPVS将流量直接定向到后端Pod。
IPVS模式是基于网络筛选器回调功能,与iptable模式是非常相似的,不同的是,IPVS使用hashtable作为数据结构并在内核空间中进行工作。这意味着IPVS模式下,kube-proxy流量重定向的时延比iptable模式中更低,同步代理规则的性能会更好。与其他模式相比,IPVS也支持更高吞吐量。
该模式的架构示意图如下图所示,由图可知,流量分发:traffic->clusterIP->pod或者traffic->kube-proxy->pod。
原图地址:https://d33wubrfki0l68.cloudfront.net/2d3d2b521cf7f9ff83238218dac1c019c270b1ed/9ac5c/images/docs/services-ipvs-overview.svg
IPVS为后端Pod的流量分发提供多种均衡策略:
- rr:轮询
- lc:最小连接(开启连接数量最少)
- dh:目标地址Hash
- sh:源Hash
- seq:期待延迟最少
- nq:非队列
注意:IPVS模式下运行kube-proxy,需保证启动kube-proxy前,在节点(Node)中IPVS是可用的。
kube-proxy以IPVS代理模式启动时,会确认IPVS内核模块是否可用,如果没有检测到可用的IPVS内核模块,kube-proxy会回退使用iptable代理模式。
这些代理模型,流量会绑定到Service的IP和Port(代理了后端Pod的Service),客户端无需感知任何关于Kubernetes、Servcie或者Pod。
如果想将某个特定的客户端的流量发送到同一个Pod,可以基于客户端IP地址设置会话,通过属性service.spec.sessionAffinity,配置为ClientIP,默认为None,同时支持配置会话最大存活时间,通过属性service.spec.sessionAffinityConfig.clientIP.timeoutSeconds配置,默认为10800秒,即3小时。
注意:Windows系统中,Service不支持最大会话存活时间。
3.5 多个端口Service
对于某些Service需要暴露多个端口。Kubernetes允许在Service对象中配置多个端口。一个Service配置多个端口,必须给端口配置名称,明确目的。多个端口配置样例如下:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
注意:与Kubernetes命名一致,端口的名称只能包含小写字母和中划线。端口名称的开始和结束必须是字母或数字。如合法的:123-abc,web;不合法:123_abc,-web。
3.6 选择IP地址
通过配置.spec.clusterIP属性,在Service创建请求中指定集群的IP地址。如,想重用已经有DNS或者原有系统已配置IP地址并且很难重新配置。
选择的IP地址须满足:在API server配置的service-cluster-ip-range CIDR范围内,有效的IPv4或者IPv6地址。如果创建的Service包含无效的clusterIP地址,API server会返回422状态码,表明错误。
3.7 流量策略
3.7.1 外部流量策略
通过属性spec.externalTrafficPolicy控制流量在外部资源的分发。可用的类型有Cluster和Local。Cluster:流量分发到已就绪的Endpoint,Local:只分发到已就绪的本地节点Endpoint。如果流量策略为Local,但是没有本地节点Endpoint,kube-proxy不会将流量转发到相关的Service。
注意:如果为kube-proxy开启ProxyTerminatingEndpoints属性,kube-proxy会检测节点是否有本地Endpoint以及所有本地Endpoint是否标记为terminating。如果有本地Endpoint并且所有本地Endpoint标记为terminating,kube-proxy会忽略Local策略的外部流量。如果外部流量策略为Cluster,本地节点Endpoint为terminating,kube-proxy会将流量分发到其他正常的Endpoint。即使健康检查节点启动失败时,这种转发方式对于终止的Endpoint,仍允许外部负载均衡器优雅地分离出NodePort Service的连接。否则,流量会在Pod终止期间丢失。
3.7.2 内部流量策略
通过属性spec.internalTrafficPolicy控制流量在内部资源的分发。与externalTrafficPolicy一样,有两种值:Cluster和Local。Cluster:内部流量只分配到就绪的Endpoint;Local:流量值分发到本地节点的Endpoint。如果流量策略为Local,如果没有本地Endpoint,kube-proxy会丢弃该流量。
3.8 Service部署
https://blog.csdn.net/Xin_101/article/details/124519232文章来源:https://www.toymoban.com/news/detail-467788.html
4 小结
核心:
(1)集群中的每个Pod会在集群范围内获取自己唯一的IP地址,Pod间通信无需建立连接,无需考虑端口映射;
(2)Service是将一系列Pod应用暴露为网络服务的一种方法,即通过Service访问Pod;
(3)代理模式有3种:用户空间代理模式、iptables代理模式和IPVs代理模式;
(4)Kubernetes允许在Service对象中配置多个端口;
(5)流量分配策略:Cluster和Local两种方式,Cluster:流量分发到就绪的Endpoint;Local流量只分发到本机Endpoint,Endpoint终止后,则会丢弃流量。文章来源地址https://www.toymoban.com/news/detail-467788.html
到了这里,关于详解K8S网络模型(包含Service讲解)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!