前言
写这篇文章的目的,主要是为了记录一下这次作业历程,并且笔者了解到很多同志饱受作业折磨,遂简单分享一下个人完成作业的历程,以下内容仅为本人的一些乱七八糟的想法,仅作参考O(∩_∩)O
作业要求
1、本作业的链接
【完成本次作业用到的代码文件,列出网盘链接,https://pan.baidu.com/xxx】
2、数据来源及概述
【1.列出数据的下载链接,或者说明数据的采集方法。2.概述数据的背景与内容。3.概述数据的 Volume和 Variety。】
3、数据存储与管理方案
【列出数据存储与管理的设计方案,包括:HBase、MongoDB、MapReduce。】
4、数据 存储与管理结果
【1.详述数据存储与管理的结果,详述数据的 Veracity 和 Velocity。2.给出必要的截图,每个图表都要有相应的文字说明。3.列出遇到的问题和解决办法,列出没有解决的问题。】
5、本作业的体会
【完成本次作业的心得体会。】
思路过程
1、本作业的代码文件链接
本次作业代码文件的网盘链接如下:
链接:数据自取
提取码:6666
2、数据来源及概述
本次作业的原始数据是在 kaggle 上找的开源的亚马逊餐饮评论数据集,数据集是由几个学者共同收集的,该数据集包含对亚马逊不同美食的评论。数据跨度超过 10 年,包括截至 2012 年 10 月的所有 500000 条评论。评论包括产品、用户信息、评级和纯文本评论,它还包括来自所有其他亚马逊类别的评论。数据集一共包含 568454 条数据,数据量可观,数据大小(Volume)为 287MB。该数据集包含 10 个属性,分别为序号、产品编号、用户编号、用户名、认为评价有帮助的用户数量、表示评价是否有帮助的用户数量、用户评分、评分时间、评论的概括以及详细评论内容。此外,该数据集为纯文本类型(Variety),类型单一,原本我打算使用一个图片数据集,但是数据质量不够好,比较杂乱,于是我依然采用文本类型的数据集完成作业。

3、数据存储与管理方案
HBase
Hbase是一种分布式存储的数据库,内部架构包含ZooKeeper、Master、HDFS,HBase 采用表来组织数据,表由行和列组成,列划分为若干个列族,每个 HBase表都由若干行组成,每个行由行键来标识。选用 HBase 存储并管理数据,HDFS 有
高容错、高扩展的特点,而 Hbase 基于 HDFS 实现数据的存储,因此 Hbase 拥有与生俱来的超强的扩展性和吞吐量。同时,由于 HBase 是一个列式数据库,当单张表字段很多的时候,可以将相同的列存在到不同的服务实例上,分散负载压力。我将数据存储到 HBase 的方案是先将数据上传至 HDFS,以 HDFS 为过渡,再将数据上传至 HBase,因为 HDFS 无法很好地管理数据,故采用 HBase。在对 HBase进行操作时,Zookeeper 会实时监测每个 Region 服务器的状态,当某个 Region服务器发生故障时,Zookeeper 会通知 Master。
MongoDB
MongoDB 是NoSQL类型的数据库,保留了关系型数据库即时查询的能力,保留了索引的能力。这一点汲取了关系型数据库的优点。同时,MongoDB 自身提供了副本集能将数据分布在多台机器上实现冗余,目的是可以提供自动故障转移、扩展读能力,MongoDB 使用分片技术对数据进行扩展,能自动分片、自动转移分片里面的数据块,让每一个服务器里面存储的数据都是一样的大小。在使用 HBase 上传数据后,我没有找到比较合适的可视化工具查看数据导入情况,而且工具的配置相对比较复杂,反观 MongoDB,提供了很多成熟的可视化工具,方便用户管理数据。同时,搭建一个分布式的 HBase 集群,需要进行安装Java、配置 SSH 免密登录、配置 NTP 时钟同步、安装匹配版本的 Hadoop、安装匹配版本的 Zookeeper、安装 HBase 等一系列繁琐操作,而安装 MongoDB 只需要对安装包进行解压,并进行一些必要配置即可。MongoDB 在实际管理数据时可以通过创建索引来提高查询效率,我先将数据上传至 MongoDB,然后在 adminMongo可视化工具对数据进行修改或者整理,实现管理数据的目的。
MapReduce
MapReduce 是一种编程模型,用于大规模数据集的并行运算,指定一个 Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的 Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。使用 MapReduce 自动调度计算节点来处理相应的数据块,作业和任务调度功能主要负责分配和调度计算节点(Map 节点或 Reduce 节点),同时负责监控这些节点的执行状态,并负责 Map 节点执行的同步控制。同时为了减少数据通信开销,中间结果数据进入Reduce 节点前会进行一定的合并处理;一个 Reduce 节点所处理的数据可能会来自多个 Map节点,为了避免 Reduce 计算阶段发生数据相关性,Map 节点输出的中间结果需使用一定的策略进行适当的划分处理,保证相关性数据发送到同一个 Reduce 节点。这里我调用 java 接口,实现将 HDFS 中的数据写入到 HBase 中。
4、数据存储与管理结果
HBase
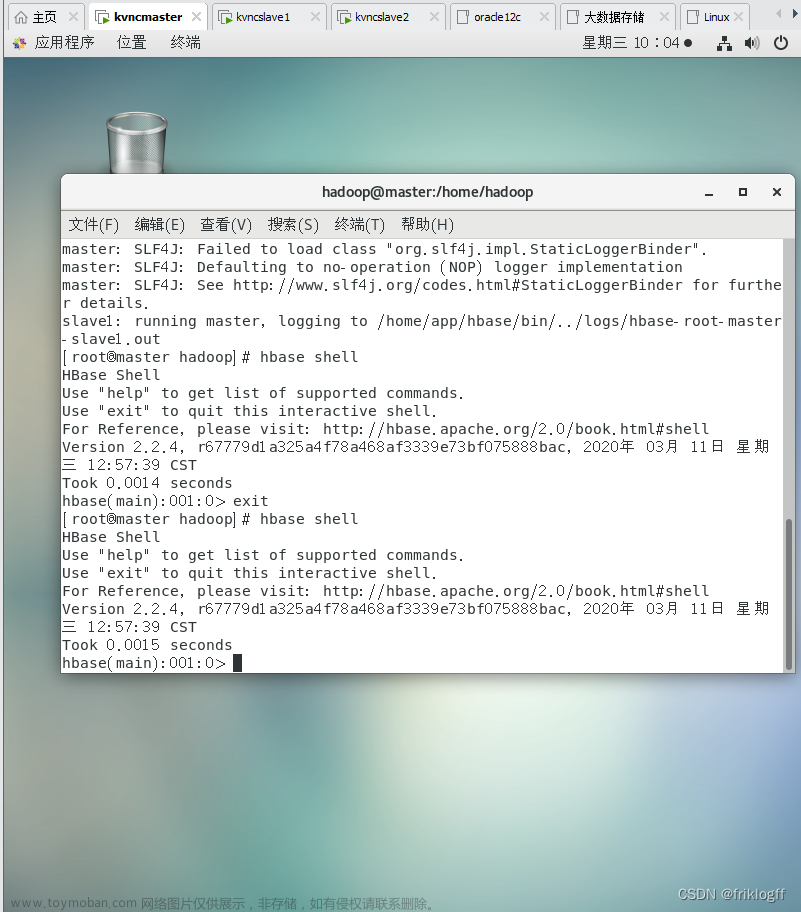
首先采用 HBase 进行数据的存储和管理,将数据集从本地拖入虚拟机中,首先启动 localhost,然后逐步启动 Hadoop 进程和 HBase 进程,先将数据传入 HDFS中,并查看数据集是否已经上传至 HDFS。


随后按照林子雨老师的教程安装 HBase。

安装完成后,启动 HBase,在启动 HBase Shell 时,一开始出现报错 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable,于是我进入首 native 目录,看看目录下有什么东西,我发现 libhadoop.so 存放在这个目录下,接着回到 Hadoop 目录,在 Hadoop 包中搜索发现,java.library.path 被
定义为 JAVA_LIBRARY_PATH,但是我没有定义 JAVA_LIBRARY_PATH。那么问题就好解决了,配置这个环境变量就行,我进入 bashrc 文件中,输入配置环境的命令 export JAVA_LIBRARY_PATH=/usr/local/hadoop/lib/native,保存后重新启动 HBase Shell 报错就消失了。解决了第一个报错后,我进入 Shell 中,先创建一个表,只有一个列簇info,然后输入命令 :
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator="," -Dimporttsv.columns="HBASE_ROW_KEY,info:Id,info:ProductId,info:UserId,info:ProfileName,info:HelpfulnessNumerator,info:HelpfulnessDenominator,info:Score,info:Time,info:Summary,info:Text" hbase-csv1 hdfs:///user/hadoop/input/FoodReviews.csv
尝试将文件上传至 HBase 中,但是出现报错,这个问题困扰了我很久,在网上找各种解决方案均没用,一直以为是语法问题,抠各种细节,后来才发现上传命令不能在 Shell 里面输入,我退出 Shell 之后再重新输入,成功上传。

待数据上传完成后,我使用 scan 命令查看刚刚存放数据的表,查看的时候一共耗时 564s,速度还算可以(Velocity);数据内容丰富度是比较高的,准确性好,拥有较高的质量 (Veracity)。我的原始数据是有 50 万行的,但是 scan之后只能看到 10 万行,我猜测这可能是 HBase 查看数据的上限?因为传入 HDFS中的文件大小跟主机中的一样,应该不存在数据损坏或者有部分数据未上传的情况,因此这对我来说是一个疑点。


MongoDB
其次,我使用 MongoDB 进行数据的管理,先将 MongoDB 安装好,这里我采用的是 MongoDB 官网的教程,安装完成后,启动 MongoDB 时出了点问题,报错细节为 Failed to start mongodb service: Unit mongodb.service not found,后来我发现我没有配置好 MongoDB,于是创建配置文件并追加文本,保存后退出重新启动 MongoDB 成功。


随后启动 MongoDB Shell,创建一个新的数据库,命名为 food,为了能使 show dbs 命令出现刚创建的数据库,我插入一条数据并查看,判断没问题之后关闭MongoDB Shell,开始将文件导入 MongoDB。

导入数据文件时,要注意前提是已经启动 MongoDB,并且不需要进入 MongoDB Shell 执行命令,导入成功后显示如下的界面。前几次上传过程会出现报错Failed: fields cannot be identical: '1' and '1',网上找了原因,可能是csv 格式问题,于是将 excel 文件另存为 utf-8 格式的 csv 格式,重新拖入虚拟机并重新上传,没用。于是另找原因,这时我想到命令有一个参数是--headerline,而我的数据集最顶上的属性行之前被我删了(为了方便上传至HBase),我把它补回去,重新上传,成功了!

将数据导入 MongoDB 后,我想使用可视化工具查看导入情况,于是着手安装mongo-express 和 adminMongo 工具。安装这两个工具都需要先下载 node.js,所以我在本地主机下载好 node.js 相应的版本,然后拖入虚拟机,先在/usr/local路径下创建 node 文件夹,将 node 文件的所有权限赋给 hadoop 用户,随后进入node 目录下,将 node.js 的压缩包复制到该目录下并解压,之后再配置环境,通过 node -v 和 npm -v 命令测试 node 是否安装成功,同时查看对应版本号。


安装了 node.js 后,安装 mongo-express,安装完成并且修改好配置文件后,在火狐浏览器打开 http://localhost:8081,在弹出的对话框中输入默认的用户名和密码 User Name:admin,Password:pass,点击 test 进入查看。





然而我个人更喜欢 adminMongo 的界面,因此我又安装了 adminMongo,安装完成后将其启动,并在浏览器中输入 http://0.0.0.0:1234,在弹出的页面中Connection name 输入 mongodb,Connection string 输入 mongodb://127.0.0.1,
点击 Add connection,最后点击 connect 进行数据查看。可以看到,数据完美地展现出来,跟 csv 文件中的一致,内容丰富,质量高,适合用于数据挖掘和数据分析(Veracity),但我还未尝试过,打算后续用 python 分析一下数据。




MapReduce
其实在前面将数据传入 HBase 的时候,已经间接地使用了 MapReduce,对数据进行一些计算,保证上传成功。我在 HBase 创建一个新的表,然后将 HDFS 中的文件导入至 HBase 中,这里我使用 Eclipse 进行实现,通过调用 java API,对数据进行管理。
(1)新建类用于读取 HDFS 上的数据
package com.xzw.hbase_mr;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import java.io.IOException;
public class ScanDataMapper extends TableMapper<ImmutableBytesWritable, Put> {
@Override
protected void map(ImmutableBytesWritable key, Result result, Context context) throws IOException,
InterruptedException {
//运行Mapper,查询数据
Put put = new Put(key.get());
for (Cell cell :
result.rawCells()) {
put.addColumn(
CellUtil.cloneFamily(cell),
CellUtil.cloneQualifier(cell),
CellUtil.cloneValue(cell)
);
}
context.write(key, put);
}
}
(2)新建类用于将读到的数据写入 HBase 表
package com.xzw.hbase_mr;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
import java.io.IOException;
public class InsertDataReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
@Override
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException,
InterruptedException {
//运行Reducer,增加数据
for (Put put :
values) {
context.write(NullWritable.get(), put);
}
}
}
(3)新建类用于组装运行 job 任务
package com.xzw.hbase_mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.JobStatus;
import org.apache.hadoop.util.Tool;
public class HBaseMapperReduceTool implements Tool {
public int run(String[] strings) throws Exception {
//作业
Job job = Job.getInstance();
job.setJarByClass(HBaseMapperReduceTool.class);
//mapper
TableMapReduceUtil.initTableMapperJob(
"xzw:people",
new Scan(),
ScanDataMapper.class,
ImmutableBytesWritable.class,
Put.class,
job
);
//reducer
TableMapReduceUtil.initTableReducerJob(
"xzw:user",
InsertDataReducer.class,
job
);
//执行作业
boolean b = job.waitForCompletion(true);
return b ? JobStatus.State.SUCCEEDED.getValue(): JobStatus.State.FAILED.getValue();
}
public void setConf(Configuration configuration) {
}
public Configuration getConf() {
return null;
}
}
(4)新建类用于启动程序文章来源:https://www.toymoban.com/news/detail-467979.html
package com.xzw.hbase_mr;
import org.apache.hadoop.util.ToolRunner;
public class T2TApplication {
public static void main(String[] args) throws Exception {
ToolRunner.run(new HBaseMapperReduceTool(), args);
}
}
五 、 本作业的体会
完成了第二次的大数据处理作业后,我感慨万千。这次作业耗费了我几乎一周的时间,完成作业前,我没想到它的繁琐程度会这么大。可能是还不熟悉 Linux 系统,我在使用虚拟机的时候频频报错,上传数据总是不能非常顺利,这非常考验耐心和毅力,因此我认为磨练意志是本次作业的一大收获。此外,通过完成此次作业,我对虚拟机的各种操作和命令更加熟悉了,之前还经常需要查看命令怎么写、怎么用,现在已经熟练到直接在终端敲就行了,我慢慢感悟到了 Linux 的魅力,虽然说操作上还是不太适应,但我感受到了这个系统的自由度,以及它的强大性。希望通过不断与数据打交道,我能有朝一日真正驾驭它。文章来源地址https://www.toymoban.com/news/detail-467979.html
到了这里,关于大数据处理技术作业——使用HBase&MongoDB&MapReduce进行数据存储和管理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!