开始之前
你应当先克隆这个仓库
git clone https://github.com/ultralytics/yolov5 # clone
下载完毕后,进入克隆的仓库目录
cd yolov5
下载依赖
pip install -r requirements.txt # install
下载数据集
这里有个数据集,为了节省训练时间,文件不是很大。结尾处我会推荐几个大型数据集下载地址。
数据集下载
提取码:crnr
解压后,你会看到这几个文件夹:

标记数据集
可以登录 https://www.makesense.ai/ 网站去标记数据,当然,你也可以使用其他标记网站。

选择数据集目录,然后点击Object Detection,其中Image recognition主要用于图像分类。

注意注意注意 ⚠️ ⚠️ ⚠️ :请牢记你导入的图片,推荐你新建一个目录单独存储你需要标记的图片文件,这一步很关键,不然一会图片标签对应不上,你将白忙活一场!!!

这里我们可以首先添加几个标签,比如我想训练它识别苹果,香蕉,那你就可以设置两个标签,分别为:apple,banana
根据我们的数据集,这里我们选择设置一个名为plastic的标签名,我使用的数据集是下面这个目录。

如果你想同时训练这些所有类型的目录,你可以把他们集合起来,放在同一个目录当中然后导入到这个标记网站。

标记你需要识别的部分,然后点击选择标签。

标记过程非常无聊,很多次我想睡觉。这里我只标记了200个,理想情况下,需要更多的数据,如果你的时间充沛或者对识别结果要求很高,请尽量多标记一些数据,过程是很辛苦的。
以此类推,等你标记完所有数据,点击Export Annotations。


导出之后,我们将看到一个包含很多txt文件的文件夹。

plastic1.txt 文件就是代表 plastic1.jpg 图片的标记文件。以此类推。

其中的 0 就是代表我们的标签,一会训练的时候,你可以设置多个标签,比如设置 0 代表塑料,1代表纸箱等。
剩下那几个代表我们标记图像在整个图片当中的位置。
整理文件
这里我创建了一个名为 mydata 的文件夹。你应当记住你的文件路径。
文件夹内包含了两个文件夹,分别为 train,val。

train 文件夹内又包含了 images,labels两个文件夹。
当然,val 文件内也需要这个两个文件夹。

- images:我们标记的图片
- labels:标记位置的 txt 文件


新建 yaml 文件
我这里新建了名为 mydataset.yaml,你应当记住你的文件路径。
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: mydata # dataset root dir
train: shuju # train images (relative to 'path') 128 images
val: shuju # val images (relative to 'path') 128 images
# test: # test images (optional)
names:
0: plastic
- path: 数据集的根目录。所有其他路径(如训练集和验证集)都是相对于这个路径的。
- train: 训练数据集的路径。
- val: 验证数据集的路径
- test: 可选字段,指定测试数据集的路径。
这里配置文件的意思就代表 mydata/shuju。
举个例子,如果你的 mydata(包含了train,val的文件夹) 目录在 /aaa/bbb/ccc/mydata,那你的配置文件应该如下。
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /aaa/bbb/ccc/mydata # dataset root dir
train: train # train images (relative to 'path') 128 images
val: val # val images (relative to 'path') 128 images
# test: # test images (optional)
names:
0: plastic
它就代表: /aaa/bbb/ccc/mydata/train. /aaa/bbb/ccc/mydata/val.
这里的 0 就是我们标签,如果你当时在一个图片内标记了好几个物体。例如,你不仅标记塑料还标记了纸,那你的配置文件就应该为:
names:
0: plastic
1: paper
相应的你的 txt 文件也会自动出现多个标签,如果你标记数据时同时在一张图片内标记了多个物体的话。
开始训练
这个 mydataset 就是你配置文件的地址。
python train.py --img 640 --epochs 3 --data mydataset.yaml --weights yolov5s.pt
这里使用了 yolov5s
模型选择
执行训练的时候使用了 --weights yolov5s.pt ,这是一种模型,你可以参考下图具体选择,如我们选择 yolov5x ,就可以使用 --weights yolov5x.pt ,推荐使用 yolov5s,除非你要求的准确度非常高,不然你需要花费非常长的时间和足够的硬件支持来训练它。

训练完成
训练好的模型在 runs/train/exp**/weights/best.pt
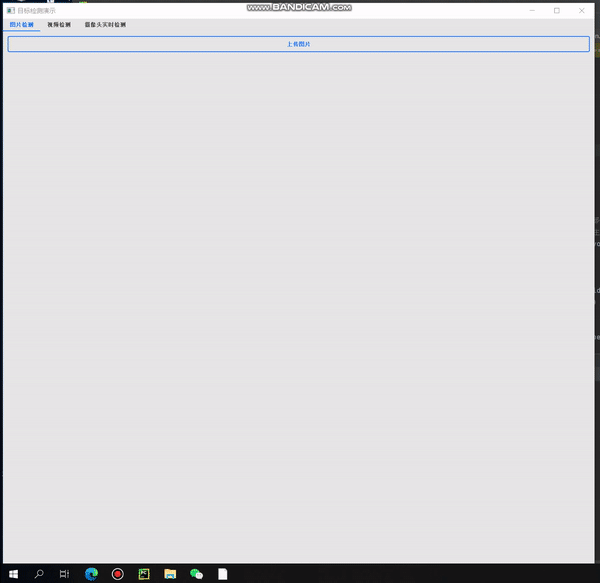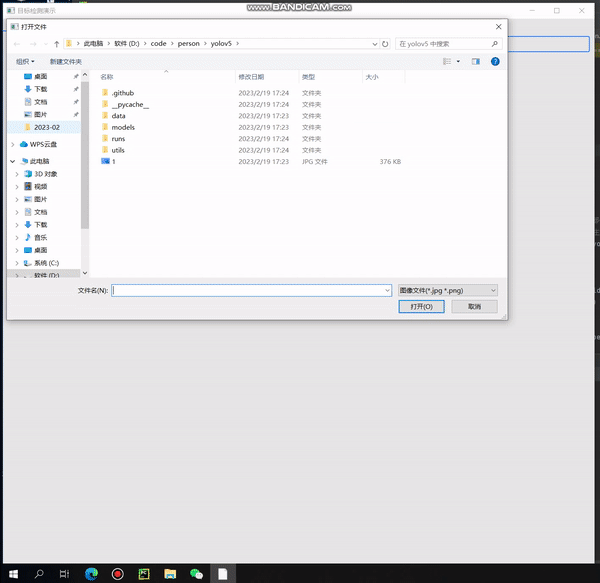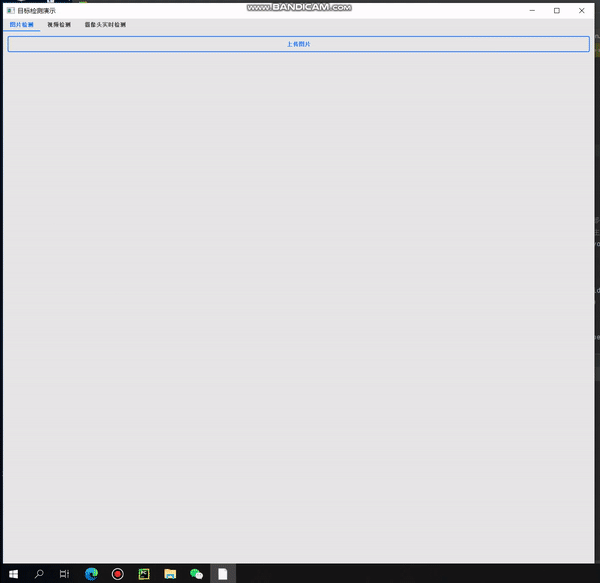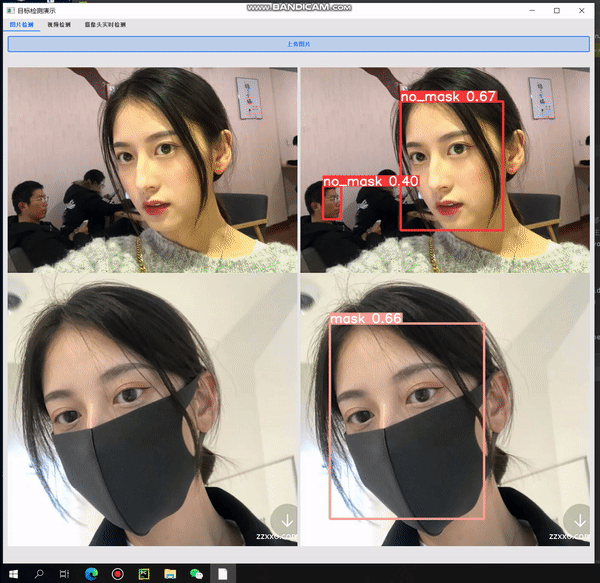
使用模型进行识别
这里的 best.pt 是你训练的模型地址。 –source 后面是你需要识别的图片地址。
python detect.py --weights best.pt --img 640 --source plastic184.jpg


自定义模型下载
如果你不想进行从头训练模型,可以下载这个已经训练好的模型进行上一步的 测试模型进行预测。
分类模型下载
提取码:vvd6
数据集下载地址分享
1:数据集下载地址1
2:数据集下载地址2文章来源:https://www.toymoban.com/news/detail-468026.html
问题
如果运行当中出现问题,欢迎咨询。文章来源地址https://www.toymoban.com/news/detail-468026.html
到了这里,关于使用yolov5实现图像识别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!