运维同事导入一批大约500万左右的数据,耗时较久。他使用的是纯SQL导入,主键使用的是UUID,因为业务原因没有使用自增ID。
因为是内网,不能远程访问。
通过沟通,大致觉得有两个原因,一是因为UUID作为主键,二是表字段繁多,单行加起来接近10000的长度引起行溢出。
因为是临时一次性任务,同事没有做深纠,我在这里简单做一个验证。
版本:5.7.19
引擎:innodb
uuid主键的影响
mysql自带的UUID()函数简单方便,不重复。但是它缺点也是众所周知的。
-
UUID的返回值通常是随机的,而InnoDB的表实质是以主键组织存储的索引,插入新的记录不是顺序追加,而会往前插入,造成页分裂,表的再平衡。在数据量越大的情况,性能影响越严重。
-
主键包含在每个二级索引中,过长的主键会浪费磁盘和内存的空间。
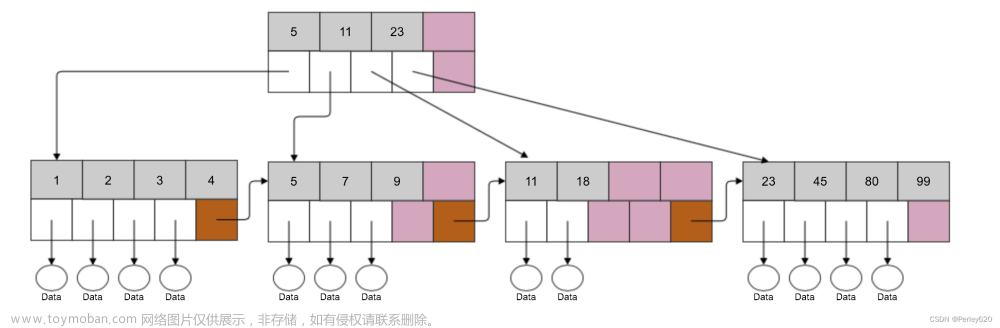
页分裂
为什么主键ID的顺序这么重要?
mysql innodb引擎数据结构为B+tree,查找的时候二分查找,这就要求数据是按顺序存储的。
而UUID是无序的,它作为主键在写入的时候,就可能会频繁的进行中间插入和页分裂。页分裂会造成已有的数据移位,类似于arraylist进行插入数据。
因此表数据越多,插入的效率就会越低。也会使得磁盘空间利用率降低。
除了UUID,其它还有两种常见的ID生成法。
一是自增id,最简单效率也最高,但不适合分布式唯一主键,和在一些敏感业务如订单注册用户时,可能通过ID值会暴露一些商业秘密。
雪花算法
再一个是雪花算法,最常见的分布式ID生成算法。
可以看到它跟时间戳(毫秒级)和服务器相关,通过12bit序列号区分同毫秒内产生的不同id。
因此能保证在单台服务器上的大致趋势递增。 在并发高的情况下不能保证完全递增,因此需考虑到这一点。
它有时钟回拨的问题,这里不展开。

定量验证
以上只是定性的判断。
下面做一下定量的测试。
本文验证自增id,雪花算法ID,以及uuid作为主键3种情况,往3张空表插入500万条数据,每个批次10万,共50个批次。
StopWatch stopWatch = new StopWatch();
stopWatch.start("准备数据阶段");
int count = 500 * 10000 ;
List<TUser> list = new ArrayList<>(count);
ExecutorService executorService = Executors.newFixedThreadPool(100);
List<TUser> finalList = list;
Semaphore semaphore = new Semaphore(100);
for (int i = 0; i < count; i++) {
executorService.submit(new Runnable() {
@SneakyThrows
@Override
public void run() {
semaphore.acquire();
TUser user = new TUser();
// 雪花算法ID
user.setId(SnowflakeIdUtil.snowflakeId());
user.setName(testService.getRandomName());
// UUID
user.setId(UUID.randomUUID().toString());
finalList.add(user);
semaphore.release();
}
}).get();
}
stopWatch.stop();
System.out.println("开始写入");
List<Time> times = new ArrayList<>();
stopWatch.start("写入数据阶段");
List<TUser> subList = new ArrayList<>(100000);
for (int i = 1; i <= count; i++) {
TUser user = finalList.get(i-1);
subList.add(user);
if (i % 100000 == 0) {
// finalList.remove(user);
long start = System.currentTimeMillis();
tUserDao.insertBatch(subList);
long time = System.currentTimeMillis() - start;
times.add(new Time(time));
subList.clear();
log.info("写入一次" + i);
}
}
stopWatch.stop();
System.out.println(stopWatch.prettyPrint());
// 将每个批次耗时打印出来,放入excel生成图表
times.stream().map(e -> e.getTime()).forEach(System.out::println);
总耗时情况
UU ID:414321ms
雪花ID 167748ms
自增ID 75829ms
将最后每个批次耗时的集合打印出来,放到Excel中,生成图表。
纵坐标表示耗时,单位ms
横坐标表示写入批次

可以明显的观察到,使用UUID作为主键,在表数据量在350万以后,耗时上升极快,性能呈指数级下降。
同时自增ID效率高于雪花算法ID,都很稳定。
这是在行数据量极小(<50)的情况下。
在行大小> 8000,在页16KB至少两行数据的情况下,也必然会发生行溢出。这里再看看测试情况。
行溢出情况
MySQL单行数据最大能存储65535字节的数据,InnoDB的页为16KB,即16384字节,当行的实际存储长度超过16384/2的长度时,就会行溢出。
为什么是/2,因为页至少需要存储两行数据。
为什么单页至少存储两行数据,如果为1,B+tree就退化为了链表。
当行溢出的时候,会将大字段数据存放在页类型为Uncompress BLOB页中,在当前页就会对大字段建立一个引用,类假于二级索引。
所以设置测试表name长度大于大约16384/2的时候,就会发生行溢出现象。
行溢出时,3种不同ID的表现
测试代码跟上面类似。
再准备3张空表。
字段类型varchar,长度10000,user.setName()设置实际长度大于8000。
这次只写入50万条数据,每批次1万条数据,共50个批次。

这次uuid在写入30万条记录后,耗时开始明显上升。
以上是行溢出的情况下,UUID,雪花算法,自增ID等 3种ID的写入性能情况。
uuid在溢出和不溢出下的表现
下面来测试一下,使用UUID在行溢出和不溢出的两种情况下写入性能情况。
再新建两张表,t_user_uuid_long,此表name字段长度100000,最终写入字符长度9995
t_user_uuid_short,此表name字段长度8000,最终写入字符长度7995

写入耗时曲线大致相当,看不出明显差距。
但是读的差距非常明显!
因为t_user_uuid_long 中的name字段发生了行溢出,。。。。。select的时候需要跨页提取数据,类似于做了1次回表,而且回表还是跨页的。
select id,name from t_user_uuid_short order by id asc limit 1000
耗时0.145s
select id,name from t_user_uuid_long order by id asc limit 1000
耗时4.153s,性能相差接近30倍。
小结
以上测试结果只是在测试机上的粗糙测试结果,不是基准测试,只做参考。文章来源:https://www.toymoban.com/news/detail-468175.html
测试结果表明,运维同事的慢操作可能受UUID影响 ,但大字段对写入的影响并不明显。
不过大字段对读取的性能影响明显。文章来源地址https://www.toymoban.com/news/detail-468175.html
到了这里,关于MySQL uuid及其相关的一些简单性能测试的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!