1、ConcurrentHashMap的原理和结构
我们都知道Hash表的结构是数组加链表,就是一个数组中,每一个元素都是一个链表,有时候也把会形象的把数组中的每个元素称为一个“桶”。在插入元素的时候,首先通过对传入的键(key),进行一个哈希函数的处理,来确定元素应该存放于数组中哪个一个元素的链表中。
这种数据结构在很多计算机语言中都能找到其身影,在Java中如HashMap,ConcurrentHashMap等都是这种数据结构。
但是这中数据结构在实现HashMap的时候并不是线程安全的,因为在HashMap扩容的时候,是会将原先的链表迁移至新的链表数组中,在迁移过程中多线程情况下会有造成链表的死循环情况(JDK1.7之前的头插法);还有就是在多线程插入的时候也会造成链表中数据的覆盖导致数据丢失。
所以就出现了线程安全的HashMap类似的hash表集合,典型的就是HashTable和ConcurrentHashMap.
HashTable实现线程安全的代价比较大,那就是所有有可能产生竞争的方法里都加上了synchronized,这就导致在出现竞争时,只能一个线程对整个HashTable进行操作,其他线程都需要阻塞等待当前取到锁的线程执行完成,这样效率非常低。
而ConcurrentHashMap解决线程安全的方式,它避免了对整个Map进行加锁,从而提高了并发的效率
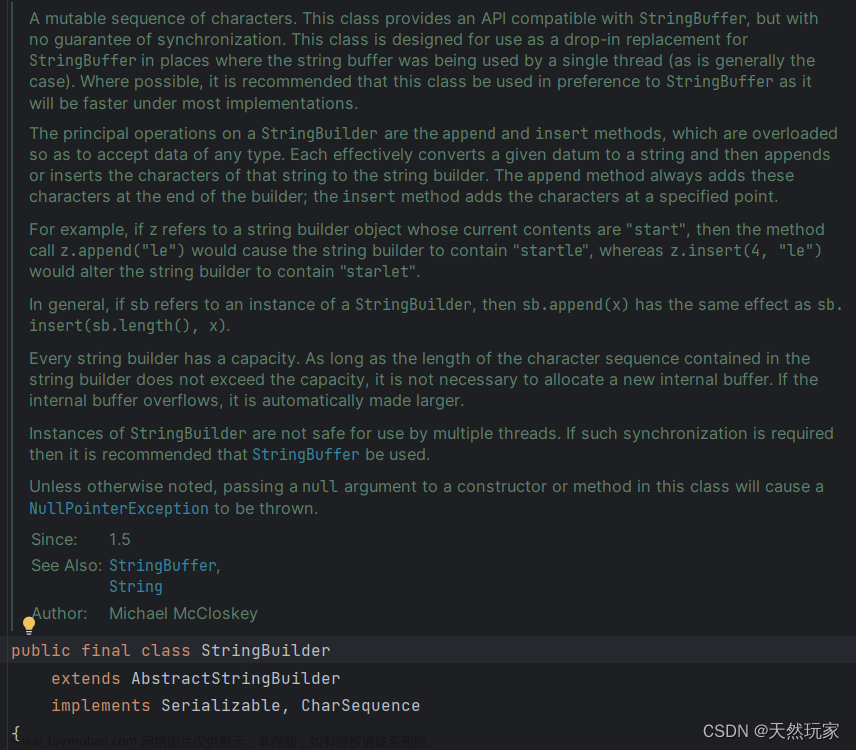
JDK1.7版本的ConcurrentHashMap采用分段锁的形式,每一段分一个Segment类,他内部类似HashMap的结构,内部有一个Entry数组,数组的每一个元素是一个链表,同时Segment继承自
ReentrantLock。
结构如下:

在HashEntry中采用volatile来修饰,HashEntry的当前值和next元素的值。所以get方法在获取数据的时候是不需要加锁的,这样就大大提高了执行效率
在执行put()方法的时候先尝试获取锁(tryLock()),如果获取失败,说明存在竞争,那么通过scanAndLockForPut()方法自旋,当自旋次数达到MAX_SCAN_RETRIES时会执行阻塞锁,直到获取锁成功。
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 首先尝试获取锁,获取失败则执行自旋,自旋次数超过最大长度,后改为阻塞锁,直到获取锁成功。
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
JDK1.8之后的ConcurrentHashMap
在JDK1.8版本中采用了CAS+synchronized的方法来保证并发,线程安全
put的源码如下:
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//1、计算出hash值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//2、判断当前数据结构是否从未放过数据,即是否未初始化,为空则先执行初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//3、通过key的hash判断当前位置是否为null
//(通过数组长度减一和hash做与运算得到要判断的当前数组位置)
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//如果当前位置为null,则通过CAS写入,如果CAS写入失败,通过自旋保证写入成功
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//4、当前hash值等于MOVED(-1)时,需要进行扩容
else if ((fh = f.hash) == MOVED)
//扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//5、当上面的内容都不满足时,采用synchronized阻塞锁,来将数据进行写入
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//6、如果数量大于TREEIFY_THRESHOLD(8),需要转化为红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}步骤:
1、计算出hash值
2、判断当前数据结构是否从未放过数据,即是否未初始化,为空则先执行初始化
3、通过key的hash判断当前位置是否为null
4、如果当前位置为null,则通过CAS写入,如果CAS写入失败,通过自旋保证写入成功
5、当前hash值等于MOVED(-1)时,需要进行扩容
6、当上面的内容都不满足时,采用synchronized阻塞锁,来将数据进行写入
7、如果数量大于TREEIFY_THRESHOLD(8),需要转化为红黑树
JDK1.8ConcurrentHashMap的get()方法
源码如下:
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}1、根据key的hash寻找到具体的位置
2、如果是红黑树就按照红黑树的方式去查找数据
3、如果是链表就按照链表的方式去查找数据
总结:
1、JDK1.7给Segment添加ReentrantLock锁来实现线程安全
2、JDK1.8通过CAS或者synchronized来实现线程安全
详细解释:
1、ConcurrentHashMap在JDK1.7中使用的是数组加链表的结构,其中数组分两大类,大数组segment,小数组HashEntry,而加锁是通过给Segment加ReentrantLock重入锁来保证线程安全文章来源:https://www.toymoban.com/news/detail-468208.html
2、ConcurrentHashMap在JDK1.8中使用的是数组加链表加红黑树的结构,它通过CAS或synchronized来保证线程安全的,并且缩小了锁的粒度,查询性能也更高文章来源地址https://www.toymoban.com/news/detail-468208.html
到了这里,关于ConcurrentHashMap为什么是线程安全的?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!