目录
一、数据挖掘与机器学习
1、概念
2、人工智能
3、数据挖掘体系
二、机器学习
1、什么是机器学习
2、机器学习的应用
3、实现机器学习算法的工具与技术框架
三、Spark MLlib介绍
1、简介
2、MLlib基本数据类型
Ⅰ、概述
Ⅱ、本地向量
Ⅲ、向量标签的使用
Ⅳ、本地矩阵
Ⅴ、分布式矩阵的使用
3、MLlib统计量基础
Ⅰ、概述
Ⅱ、计算基本统计量
Ⅲ、计算相关系数
四、距离度量和相似度度量
1、概念
2、欧氏距离
3、曼哈顿距离
4、切比雪夫距离
五、最小二乘法
1、简介
2、原理及推导
3、案例练习
4、多元线性回归模型的细节说明
一、数据挖掘与机器学习
1、概念
数据挖掘:也成为data mining,它是一个很宽泛的概念,也是现在新兴的学科,目的在如何从海量数据中挖掘出有用的信息来
数据挖掘这个工作BI(商业智能)可以做,统计分析可以做,大数据技术可以做,市场运营也可以做,或者用excel分析数据,发现了一些有用的信息,然后这些信息可以指导你的业务business,这也属于数据挖掘。
机器学习:machine learning,是计算机科学与统计学交叉的学科,基本目标是学习一个x->y的函数(映射),来做分类、聚类或者回归的工作。现在好多数据挖掘的工作是通过机器学习提供的算法工具实现的,比如说PB级别的点击日志通过典型的机器学习流程可以得到一个预估模型,从而提高互联网广告的点击率和回报率;个性化推荐,还是通过机器学习的一些算法分析平台上的各种购买,浏览和收藏日志得到的一个推荐模型,然后预测你喜欢的商品,还有现在的抖音你点赞关注什么类型的视频,就会给你推荐相似类型的视频等等
深度学习:deep learning,机器学习里面现在比较火的一个topic,本身是神经网络算法的衍生,在图像,语言等富媒体的分类和识别上取得非常好的效果,所以各大研究机构和公司都投入大量的让人力做相关的研究和开发。
总结:数据挖掘是一个很宽泛的概念,数据挖掘经常用的方法来自于机器学习这门学科,深度学习也是来源于机器学习的算法模型,本质上是原来的神经网络。
2、人工智能

“人工智能”一词最初是在1956 年Dartmouth学会上提出的。从那以后,研究者们发展了众多理论和原理,人工智能的概念也随之扩展。人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。
人工智能是对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也可能超过人的智能。
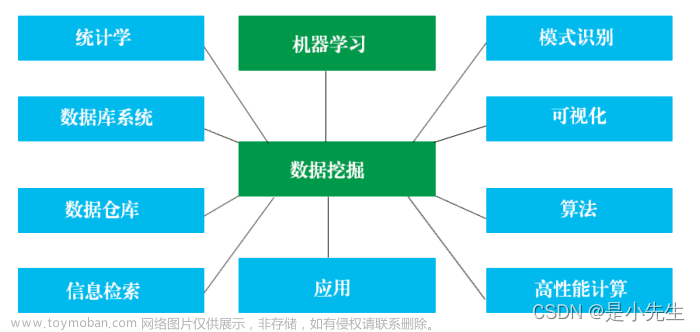
3、数据挖掘体系
二、机器学习
1、什么是机器学习
机器学习是是一门多领域交叉学科。涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。机器学习的算法在数据挖掘里被大量使用。
此外它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。
2、机器学习的应用
①、市场分析和管理
比如:目标市场,客户关系管理(CRM),市场占有量分析,交叉销售,市场分割
1.比如做目标市场分析:
构建一系列的“客户群模型”,这些顾客具有相同特征:兴趣爱好,收入水平,消费习惯,等等。确定顾客的购买模式
CTR估计(广告点击率预测)比如通过逻辑回归来实现。
2.比如做交叉市场分析:
货物销售之间的相互联系和相关性,以及基于这种联系上的预测
②、风险分析和管理,风险预测,客户保持,保险业的改良,质量控制,竞争分析
1.比如做公司分析和风险管理:
财务计划——现金流转分析和预测
资源计划——总结和比较资源和花费
竞争分析——对竞争者和市场趋势的监控
对顾客按等级分组和基于等级的定价过程
针对上述的场景,可以通过聚类模型将整个数据样本划分为两类,从而找到低价值和高价值用户,进而完成客户关系的维护
对定价策略应用于竞争更激烈的市场中
保险公司对于保险费率的厘定
比如:
根据以往的历史数据建立回归模型,同回归模型可以实现预测

③、欺骗检测和异常模式的监测(孤立点)
欺诈行为检测和异常模式
1.比如对欺骗行为进行聚类和建模,并进行孤立点分析
2.汽车保险:相撞事件的分析
3.洗钱:发现可疑的货币交易行为
4.医疗保险:职业病人,医生或以及相关数据分析
5.电信:电话呼叫欺骗行为,根据呼叫目的地,持续事件,日或周呼叫次数,分析该模型发现与期待标准的偏差
6.零售产业:比如根据分析师估计有38%的零售额下降是由于雇员的不诚实行为造成的
7.反恐
④、文本挖掘
1.新闻组
2.电子邮件(垃圾邮件的过滤)可以通过贝叶斯来实现
3.文档归类
4.评论自动分析
5.垃圾信息过滤
6.网页自动分类等
⑤、天文学
例如:JPL实验室和Palomar天文台层借助于数据挖掘工具
⑥、推荐系统
当当网的图书推荐
汽车之家的同类汽车推荐
淘宝的同类商品推荐
新浪的视频推荐
百度知道的问题推荐
社交推荐
职位推荐
⑦、智能博弈
棋谱学习
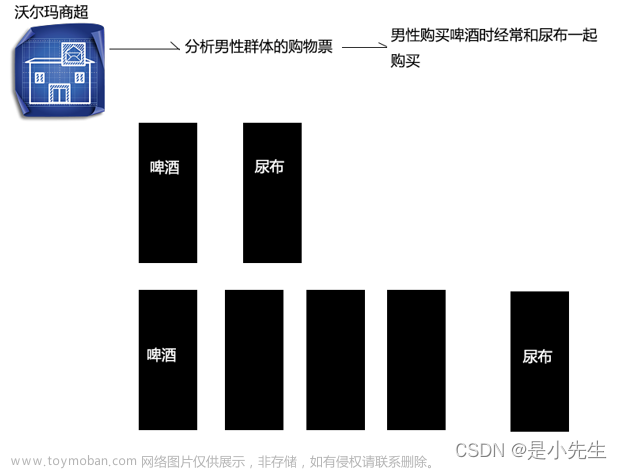
⑧、频繁模式挖掘
购物篮商品分析,典型案例:啤酒-尿布
⑨、模式识别
1.语音识别
2.图像识别
n 指纹、虹膜纹识别
n 脸像识别
n 车牌识别
n 动态图像识别
n 小波分析
3、实现机器学习算法的工具与技术框架
Matlab R
Pyhton SPSS
Eviews Hadoop(Mahout)
Spark(MLlib)
三、Spark MLlib介绍
1、简介
MLlib是一个构建在Spark上的、专门针对大数据处理的并发式高速机器学习库,其特点是采用较为先进的迭代式、内存存储的分析计算,使得数据的计算处理速度大大高于普通的数据处理引擎。
MLlib机器学习库还在不停地更新中,Apache的相关研究人员仍在不停地为其中添加更多的机器学习算法。目前MLlib中已经有通用的学习算法和工具类,包括统计、分类、回归、聚类、降维等。
MLlib采用Scala语言编写,Scala语言是运行在JVM上的一种函数式编程语言,特点就是可移植性强,“一次编写,到处运行”是其最重要的特点。借助于RDD数据统一输入格式,让用户可以在不同的IDE上编写数据处理程序,通过本地化测试后可以在略微修改运行参数后直接在集群上运行。对结果的获取更为可视化和直观,不会因为运行系统底层的不同而造成结果的差异与改变。
2、MLlib基本数据类型
Ⅰ、概述
RDD是MLlib专用的数据格式,它参考了Scala函数式编程思想,并大胆引入统计分析概念,将存储数据转化成向量和矩阵的形式进行存储和计算,这样将数据定量化表示,能更准确地整理和分析结果。
它支持多种数据类型,也支持部署在本地计算机的本地化格式
| 类型名称 |
释义 |
| Local vector |
本地向量集。主要向Spark提供一组可进行操作的数据集合 |
| Labeled point |
向量标签。让用户能够分类不同的数据集合 |
| Local matrix |
本地矩阵。将数据结合以矩阵形式存储在本地计算机中 |
| Distributed matrix |
分布式矩阵。将矩阵集合以矩阵形式存储在分布式计算机中 |
Ⅱ、本地向量
MLlib使用本地化存储类型是向量,这里向量主要有两类:稀疏性数据集和密集型数据集
举例:
package cn.yang.vector
import org.apache.spark.mllib.linalg.Vectors
object Driver {
def main(args:Array[String]):Unit={
//--建立密集型向量
//--dense可以将其理解为MLlib专用的一种集合形式,它与Array类似
val vd=Vectors.dense(2,0,6)//
println(vd) //[2.0,0.0,6.0]
//一参:size。spare方法是将给定的数据Array数据(9,5,2,7)分解成指定的size个部分进行处理,本例中是7个
//二参:输入数据对应的下标,要求递增,并且最大值要小于等于size
//三参:输入数据。本例中是Array(9,5,2,7)
val vs=Vectors.sparse(7,Array(0,1,3,6),Array(9,5,2,7))
println(vs(6)) //7.0
}
}package cn.yang.vector
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* 学习MLib的向量类型,后续有很多模型,建模时需要将数据封装成为向量类型来处理
*/
object Driver01 {
def main(args: Array[String]): Unit = {
//通过传入指定个数的double参数创建向量
//如果传入其他的数值类型参数,可以隐式转换为double类型
val v1=Vectors.dense(2.5, 1.5,5.6)
val v2=Vectors.dense(1,2,3)
//可以通过下标的方式操作向量
println(v1(0))
println(v2)
//重点掌握下面的方式来创建向量
val v3 =Vectors.dense(Array[Double](1,2,3))
val v4 = Vectors.dense(Array(1.1,2.1,3.3))
//练习1:通过Spark处理vectors.txt。RDD[line:String]->RDD[Vector]
val conf =new SparkConf().setMaster("local").setAppName("vector")
val sc = new SparkContext(conf)
val data = sc.textFile("D://data/ml/vectors.txt")
val r1=data.map{line=>line.split(" ").map { num => num.toDouble }}
.map{arr=>Vectors.dense(arr)}
r1.foreach(println)
}
}Ⅲ、向量标签的使用
向量标签用于对MLlib中机器学习算法的不同值做标记。例如分类问题中,可以将不同的数据集分成若干份,以整型数0、1、2……进行标记,即程序的编写者可以根据自己的需要对数据进行标记。
举例:
package cn.yang.vector
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* 学习MLib的向量标签类型
*/
object Driver02 {
def main(args: Array[String]): Unit = {
val v1 = Vectors.dense(2,3,1)
//创建向量标签。①参:标签值(看作时因变量Y)②参:向量(看作是所有自变量组成的向量)
//标签值要求的类型是Double,如果是其他的数值类型,会隐式转换成Double
val lb1=LabeledPoint(10,v1)
println(lb1.label)//获取标签值
println(lb1.features)
//练习:处理vectors.txt。前两列是自变量,第三列是因变量。要求完成转换:
/**
*vectors.txt的数据
* 2.1 3.2 1
* 2.2 7.3 2
* 1.1 5.1 1
* 5.2 2.1 1
*/
//RDD[line:String]->RDD[labeledPoint]
val conf =new SparkConf().setMaster("local").setAppName("vector")
val sc = new SparkContext(conf)
val data = sc.textFile("D://data/ml/vectors.txt")
val r1 = data.map{line=>
val info=line.split(" ")
//获取因变量
val Y=info.last.toDouble
//获取自变量数组
val XArr=info.dropRight(1).map{num=>num.toDouble}
LabeledPoint(Y,Vectors.dense(XArr))
}
r1.foreach(println)
}
}Ⅳ、本地矩阵
大数据运算中,为了更好地提升计算效率,可以更多地使用矩阵运算进行数据处理。部署在单机中的本地矩阵就是一个很好的存储方法。
举一个简单的例子,例如一个数组Array(1,2,3,4,5,6),将其分为2行3列的矩阵:
package cn.yang.vector
import org.apache.spark.mllib.linalg.Matrices
object Driver {
def main(args: Array[String]): Unit = {
val m1=Matrices.dense(2,3, Array(1,2,3,4,5,6))
println(m1)
}
}
结果:
1.0 3.0 5.0
2.0 4.0 6.0 从结果来看,数组Array(1,2,3,4,5,6)被重组成一个新的2行3列的矩阵。Matrices.dense方法是矩阵重组的调用方法,第一个参数是新矩阵行数,第二个参数是新矩阵的列数,第三个参数为传入的数据值。
Ⅴ、分布式矩阵的使用
一般来说,采用分布式矩阵进行存储的情况都是数据量非常大的情况
①、行矩阵
行矩阵是最基本的一种矩阵类型。行矩阵是以行作为基本方向的矩阵存储格式,列的作用相对较小。可以将其理解为行矩阵是一个巨大的特征向量的集合。每一行就是一个具有相同格式的向量数据,且每一行的向量内容都可以单独取出来进行操作。
数据:
1 2 3
4 5 6
代码:
import org.apache.spark.mllib.linalg.distributed.RowMatrix object Driver{ def main(args: Array[String]): Unit = { val conf=new SparkConf().setMaster("local").setAppName("vd") val sc=new SparkContext(conf) val data=sc.textFile("d://ml/rowMatrix.txt") //转成RDD,并且行数据的格式是Vector val parseData=data.map(_.split(" ").map(_.toDouble)).map(array=>Vectors.dense(array)) //读入行矩阵 val rm=new RowMatrix(parseData) //打印行数 println(rm.numRows) //打印列数 println(rm.numCols()) } }
②、带有行索引的行矩阵
单纯的行矩阵对其内容无法进行直接显示,当然可以通过调用其方法显示内部数据内容。有时候,为了方便在系统调试的过程中对行矩阵的内容进行观察和显示,MLlib提供了另外一个矩阵形式,即带有行索引的行矩阵。
数据:
1 2 3
4 5 6
代码:
package cn.yang.vector import org.apache.spark.mllib.linalg.Matrices import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.mllib.linalg.distributed.IndexedRow import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.mllib.linalg.distributed.IndexedRowMatrix object Driver { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local").setAppName("vector") val sc = new SparkContext(conf) val data = sc.textFile("D://data/ml/rowMatrix.txt") var index=0 //转成RDD,并且行数据的格式是Vector val parseData=data.map(_.split(" ").map(_.toDouble)) .map(array=>Vectors.dense(array)).map{vector=> index+=1 new IndexedRow(index,vector) } val rm = new IndexedRowMatrix(parseData) //打印矩阵所有的行数据 rm.rows.foreach {println} //打印指定索引的行数据 rm.rows.filter { x => x.index==1 }.foreach { x => print(x) } } }
3、MLlib统计量基础
Ⅰ、概述
数理统计中,基本统计量包括数据的平均值、方差,这是一组求数据统计量的基本内容。在MLlib中,统计量的计算主要用到Statistics类库。
| 类型名称 |
释义 |
| colStats |
以列为基础计算统计量的基本数据 |
| corr |
对两个数据集进行相关系数计算,根据参量的不同,返回值格式有差异 |
Ⅱ、计算基本统计量
主要调用colStats方法,接受的是RDD类型数据,但是需要注意,它工作和计算是以列为基础进行计算,调用不同方法可获得不同的统计计量值。
| 方法名称 |
释义 |
| count |
行内数据个数 |
| Max |
最大值 |
| Min |
最小值 |
| Mean |
均值 |
| normL1 |
曼哈顿距离 |
| normL2 |
欧几里得距离 |
| numNonzeros |
不包含0值的个数 |
| variance |
标准差 |
练习一:计算基本统计量
package cn.yang.vector
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.stat.Statistics
object Driver {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("testSummary")
val sc=new SparkContext(conf)
val rdd=sc.textFile("d://data/ml/testSummary.txt").map(_.split(" ").map(_.toDouble)).map(array=>Vectors.dense(array))
//返回一组数据的各项基本指标
val summary=Statistics.colStats(rdd)
println(summary.mean)//计算均值
println(summary.variance)//计算方差
println(summary.max)//最大值
println(summary.min)//最小值
println(summary.count)//行数
}
}
结果:
[3.0]
[2.5]
[5.0]
[1.0]
5练习二:距离计算
除了一些基本统计量的计算,此方法中还包括两种距离的计算,分别是normL1和normL2,代表着曼哈段距离和欧几里得距离。这两种距离主要是用以表达数据集内部数据长度的常用算法。
//接上面代码
println(summary.normL1)//计算曼哈顿距离 [15.0]
println(summary.normL2)//计算欧式距离 [7.416198487095663]曼哈顿距离:
曼哈段距离用来标明两个点在标准坐标系上的绝对轴距总和。其公式如下:
x=x1+x2+x3+…+xn
Ⅲ、计算相关系数
相关系数是一种用来反映变量之间相关关系密切程度的统计指标,在现实中一般用于对两组数据的拟合和相似程度进行定量化分析。常用的一般是皮尔逊相关系数,MLlib中默认的相关系数求法也是使用皮尔逊相关系数法。
练习:计算皮尔逊相关系数
数据:
testCorrX.txt
1 2 3 4 5
testCorrY.txt
2 4 7 9 10
package cn.yang.vector
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.mllib.stat.Statistics
object Driver {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("testCorrect")
val sc=new SparkContext(conf)
val rddX=sc.textFile("d://data/ml/testCorrX.txt").flatMap(_.split(" ").map(_.toDouble))
val rddY=sc.textFile("d://data/ml/testCorrY.txt").flatMap(_.split(" ").map(_.toDouble))
val correlation:Double=Statistics.corr(rddX,rddY)//计算两组数据之间的相关系数
println(correlation)//0.9877569118027772
}
}四、距离度量和相似度度量
1、概念
在数据分析和数据挖掘的过程中,我们经常需要知道个体间差异的大小,进而评价个体的相似性和类别。而如何来度量数据之间的差异则成为关键,分类算法或聚类算法的本质都是基于某种度量(距离度量和相似度度量)来实现的。
距离度量:用于衡量个体在空间上存在的距离,距离越远说明个体间的差异越大。
1.欧氏距离
2.明可夫斯基距离
3.曼哈顿距离
4.切比雪夫距离
5.马氏距离
相似度度量:
1.向量空间余弦相似度(Cosine Similarity)
2.皮尔森相关系数(Pearson Correlation Coefficient)
2、欧氏距离
在二维和三维空间中的欧氏距离的就是两点之间的距离。
二维空间的欧氏距离:
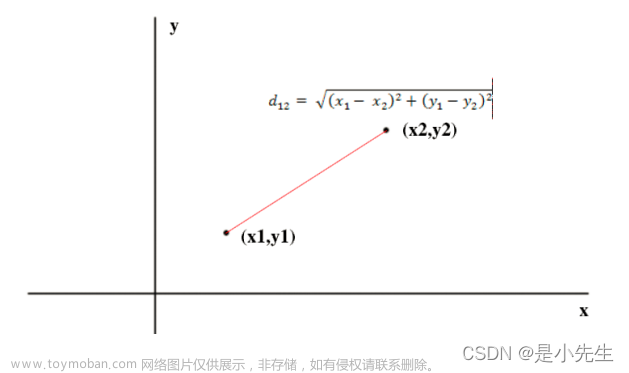
二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:
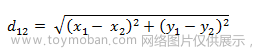
三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:

两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离:

也可以用表示成向量运算的形式:
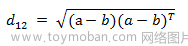
3、曼哈顿距离
可以理解为出租车距离,出租车到目的地的最短距离。
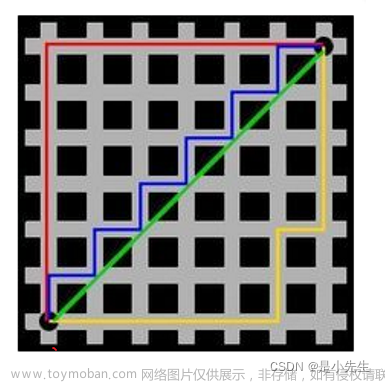
红线代表曼哈顿距离,绿色代表欧氏距离,也就是直线距离;
蓝色和黄色代表等价的曼哈顿距离。
曼哈顿距离--两点在南北方向上的距离加上在东西方向上的距离,即:
d(i,j)=|xi-xj|+|yi-yj|
例如:在平面上。坐标(x1,y1)的i点与坐标(x2,y2)的j点的曼哈顿距离为:
d(i,j)=|x1-x2|+|y1-y2|
package cn.yang.vector
object Driver {
def main(args: Array[String]): Unit = {
val p1=Array(2,1,5)
val p2=Array(5,10,3)
//计算出两个点之间的曼哈顿距离
val p1p2=p1 zip p2 //拉链
p1p2.foreach(println)
/**
* (2,5)
* (1,10)
* (5,3)
*/
val dis1=p1p2.map{x=>Math.abs(x._1-x._2)}.sum
println(dis1)//14
}
}4、切比雪夫距离
切比雪夫距离,我们可以理解为国王到目的地走的最少步数。
最少步数总是max(|x2-x1|,|y2-y1|)步

//计算出两个点之间的切比雪夫距离
val dis2=p1p2.map{x=>Math.abs(x._1-x._2)}.max
println(dis2)//9五、最小二乘法
1、简介
最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合。其他一些优化问题也可通过最小化能量或最大化熵用最小二乘法来表达。
2、原理及推导
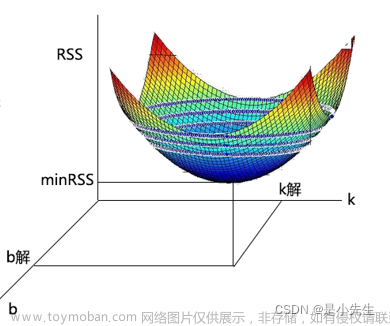
我们来看一下最简单的线性情况。
对于某个数据集(xi, yi) (i=0,1,…,n),我们需要找到一条趋势线(图中的虚线),能够表达出数据集(xi, yi)这些点所指向的方向。

我们先用一个直线函数表示这条趋势线:
Y=KX+b
数据集的点一定位于这条趋势线的上下两侧,或者与趋势线重合。我们把某个样本点xi到这条趋势线的垂直距离定义为残差ξi,那么过这一点与趋势线平行的样本函数为yi=kxi+b+ξi。如果这个样本点位于趋势线的上侧,在残差ξi>0,反之则ξi<0,如果样本点位于趋势线上则ξi=0。
现在,我们求解这条趋势线。因为是线性函数,所以也就是求解k、b这两个值。
下面我们将带有残差的直线函数修改为下面的形式:
ξi=yi-kxi-b
因为残差ξi有正负号的问题,所以我们统一用平方和来计算,即残差平方和:
很明显这个二次函数是一个凸函数(单峰函数),我们接下来对该函数求极值,即它的一阶导数等于0。
接下来,将两个方程联立,我们令:
解得a、b的值为:
上式中,x与y都已知,所以可求得k,b。
3、案例练习
某种商品的需求量(y,吨)、价格(x1,元/千克)和消费者收入(x2,元)观测值如下表所示。
y=β1X1+β2X2+β0
| y |
x1 |
x2 |
| 100 |
5 |
1000 |
| 75 |
7 |
600 |
| 80 |
6 |
1200 |
| 70 |
6 |
500 |
| 50 |
8 |
30 |
| 65 |
7 |
400 |
| 90 |
5 |
1300 |
| 100 |
4 |
1100 |
| 110 |
3 |
1300 |
| 60 |
9 |
300 |
为了能够通过Mllib建模,我们首先需要对数据格式进行一定的处理,比如如下所示:
| 100|5 1000 |
| 75|7 600 |
| 80|6 1200 |
| 70|6 500 |
| 50|8 30 |
| 65|7 400 |
| 90|5 1300 |
| 100|4 1100 |
| 110|3 1300 |
| 60|9 300 |
预测:X1=10 X2=400 Y=?
思路:
基于已收集的数据,建立目标方程:
y=β1X1+β2X2+β0
然后通过最小二乘法求解出目标方程的最优系数解(β0,β1,β2 )
最后通过此方程完成预测:
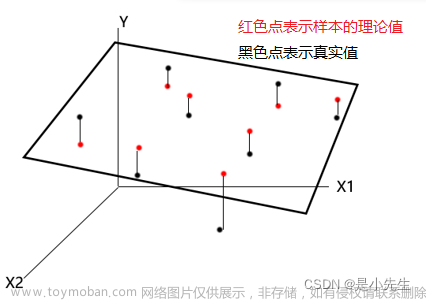
代码:
package cn.yang.lr
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.regression.LinearRegression
/**
* 本案例是建立多元线性回归模型,用于预测商品的需求量
* 模型方程:Y=β1X1+β2X2+β0
* 底层通过最小二乘解出最优的系数解,从而利用此方程完成数据的预测
*/
object Driver {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("lr")
val sc = new SparkContext(conf)
//创建SaprkSql上下文对象,用于创建或转换DataFrame
val sqc = new SQLContext(sc)
val data = sc.textFile("D://data/ml/lritem.txt")
//第一步:RDD[line:String]->RDD[(x1,x2,y)]
val r1 = data.map{line =>
val info =line.split("\\|")
val Y=info(0).toDouble
val X1=info(1).split(" ")(0).toDouble
val X2=info(1).split(" ")(1).toDouble
(X1,X2,Y)
}
// r1.foreach(println)
//第二步,为了满足建模需要,RDD[(X1,X2,Y)]->DataFrame(X1,X2,Y) 数据表类型也叫数据框
//RDD转成DataFrame的要求:RDD中每个元素必须是元组类型,而且DataFrame的列的个数以及顺序要和元组一致
val df1 = sqc.createDataFrame(r1).toDF("X1","X2","Y")
//df1.show()
//第三步:DataFrame(X1,X2,Y)->DataFrame(Vector(X1,X2),Y)这是模型最终要的数据结构
//new VectorAssembler()向量转换工具类
//setInputCols:指定自变量的列名
//setOutputCol:为所有的自变量起一个别名,后续建模可以通过这个别名找到所有自变量的列
val vectorAss= new VectorAssembler().setInputCols(Array("X1","X2"))
.setOutputCol("features")
val df1Vectors=vectorAss.transform(df1)
//第四步:通过Saprk的MLlib库建立多元回归模型
//setFeaturesCol:通过别名指定哪些列是自变量列
//setLabelCol:指定因变量的列名
//setFitIntercept(true):表示计算截距项系数。截距项系数可以不计算,但自变量的系数必须要计算
//fit:代入数据建模
val model = new LinearRegression().setFeaturesCol("features")
.setLabelCol("Y")
.setFitIntercept(true)
.fit(df1Vectors)
//获取自变量系数值
val coef = model.coefficients
//获取截距项系数值
val intercept= model.intercept
println(coef)
println(intercept)
//Y=-6.497X1+0.016X2+106.369
//第五步:通过模型实现预测
//回代样本集
val predictResult=model.transform(df1Vectors)
predictResult.show
//给定一组数据 X1=10 X2=500 利用模型预测出Y=?
//RDD[(X1,X2,Y)]->DataFrame("X1","X2","Y")->DataFrame(Vector(X1,X2),Y)->model.transform 完成预测
//因为模型预测是根据自变量做预测,和Y没关系,所以封装数据时,Y可以取任意值。
val testRDD = sc.makeRDD(List((10,500,0)))
val df2 = sqc.createDataFrame(testRDD).toDF("X1","X2","Y")
val df1Vectors1=vectorAss.transform(df2)
val predictResult1=model.transform(df1Vectors1)
predictResult1.show
//第六步:模型的检验
//获取模型的多元R2值,这个指标可以评估模型的优良性,最大值1,越趋近1,表示模型对于数据的拟合越好
//在生产环境下,R2在0.55以上都可以接受
val R2 = model.summary.r2
println(R2)
}
}结果:

4、多元线性回归模型的细节说明
①、多元,可以理解为建立的目标方程中有多个(大于1个)自变量
比如Y=β1X1+β2X2+β0
②、一元,可以理解为建立的目标方程中只有1个自变量
比如Y=β1X1+β0
③、线性,可以理解为建立的目标方程式线性方程
比如直线方程,平面方程,超平面方程都属于线性方程
直线方程:Y=β1X1+β0
平面方程:Y=β1X1+β2X2+β0
在更高维(超过三维)中的超平面方程:Y=β1X1+β2X2+...+βnXn+β0
可以的得到一个结论:线性方程的形式式已知的(固定的)
④、非线性,可以理解为建立的目标方程是非线性方程,比如圆、椭圆方程等
一般习惯是是使用线性方程来集合数据,因为线性方程的形式固定,容易求解,
而非线性方程形式不固定,很难求解
⑤、回归模型,可以理解通过这种模型,可以解决一类问题。回归模型用于解决预测问题。
在机器学习中的模型有:
回归模型,正则化模型,决策树模型,集成模型,聚类模型,分类(判别)模型
SVM模型,贝叶斯模型,降维模型,图模型,关联规则模型,推荐模型,
神经网络模型,深度学习模型
⑥、算法,可以理解为通过某种算法求解模型方程中的系数文章来源:https://www.toymoban.com/news/detail-468356.html
最小二乘法,梯度下降法,路径积分法,模拟退火算法...文章来源地址https://www.toymoban.com/news/detail-468356.html
到了这里,关于大数据笔记--Spark机器学习(第一篇)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[机器学习、Spark]Spark机器学习库MLlib的概述与数据类型](https://imgs.yssmx.com/Uploads/2024/01/406818-1.png)

![[机器学习、Spark]Spark MLlib实现数据基本统计](https://imgs.yssmx.com/Uploads/2024/02/781801-1.png)