一、系统文件IO
1.文件与读写字符串
对于C文件接口,假如想向特定文件写入字符串:
cFile.c
#include<stdio.h>
int main()
{
FILE * fp = fopen("./log.txt","w");
if(NULL == fp)
{
perror("fopen error");
return 1;
}
int count = 5;
while(count--)
{
const char *msg = "cFile\n";
fputs(msg,fp);
}
fclose(fp);
return 0;
}执行结果如下,查看log.txt文件:

假如想从特定文件读字符串,从log.txt中按行读取,读取的内容放在缓冲区,如果fgets读取成功,返回读取的新字符串的地址,如果读取失败就返回NULL,feof用来判断文件是否正常退出,即fgets是否读取成功:
cFile.c
#include<stdio.h>
int main()
{
FILE *fp = fopen("./log.txt","r");
if(NULL == fp)
{
perror("fopen error");
return 1;
}
char buffer[64];
while(fgets(buffer,sizeof(buffer),fp))
{
printf("%s",buffer);
}
if(!feof(fp))
{
printf("fgets quit not normally!\n");
}
else
{
printf("fgets quit normally!\n");
}
fclose(fp);
return 0;
}打印buffer字符串:

fprintf用于格式化地向一个文件中写入内容,fscanf用于格式化地从一个文件中读取。
2.标准输入、标准输出、标准错误
C程序会默认打开三个输入输出流:stdin, stdout, stderr,C语言会把标准输入输出流和标准错误当文件处理,流就是向硬件记录:

例如,fputs的第二个参数就是流,可以向标准屏幕stdout写入:
standardFile.c
#include<stdio.h>
int main()
{
FILE *fp =fopen("./log.txt","w");
const char *message = "this is a log file!\n";
fputs(message,stdout);
fclose(fp);
return 0;
}执行结果如下:

这种将本该显示到显示器的内容显示到文件里的操作也叫做输出重定向。既然能打印内容到标准输出,那么是否可以打印到stderr呢?请看下面代码:
standardFile.c
#include<stdio.h>
int main()
{
FILE *fp =fopen("./log.txt","w");
const char *message = "this is a log file!\n";
fputs(message,stderr);
fclose(fp);
return 0;
}执行结果如下,可以看到结果也打印在了显示器上,但是把stderr的内容重定向到文件时,却没有重定向成功,虽然都往显示器上打印,但是out和err重定向时是不一样的。:

由于linux下一切皆文件,fputs向一般文件或者硬件设备都能写入,所以fputs向磁盘也可以写入。
C++中的标准输入、标准输出、标准错误分别是cin、cout、cerr。基本上大部分语言都会提供这三个输入输出,因为写代码时,需要向程序输入数据,得有结果和错误,默认就把标准输入、标准输出和标准错误打开了。
刚刚c语言的所有操作都是在向硬件写入,而硬件包括显示器、磁盘、键盘、鼠标,由于操作系统时硬件和驱动的管理者,所以所有语言对文件的操作都必须贯穿操作系统。

而由于操作系统不相信任何人,要访问操作系统,就需要通过系统调用接口(system call),几乎所有语言都对操作系统的读写操作进行了封装,才有了语言级别的fopen、fclose、fread、fwrite、fgets、fputs、fgetc、fputc函数,这些函数底层都使用了OS提供的系统调用。
3.系统调用文件操作函数
(1)open
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.f>
int open(const char *pathname,int flags,mode_t mode);第一个参数pathname是文件名
第二个参数flags是打开方式,是32位的bit位,每一个bit位,代表一个标志,可以通过位操作的方式,一次向系统传递多个标志位,位操作在系统中很高效。查询fcntl-linux.h可以看到每个标志位的含义

第三个参数mode设置新建文件的权限。
返回值是int类型,如果执行成功,则返回新的文件描述符,如果执行失败,则返回-1。
c语言的fopen函数是对open 函数做了封装,所以在C文件中写文件操作直接就用C的接口。
(2)close
#include<unistd.h>
int close(int fd);其中,参数fd是文件描述符,要关闭文件时,直接传入文件描述符即可。
(3)read
从打开的文件中读取内容:
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);第一个参数fd是打开的文件描述符
第二个参数buf是把读取到的内容存入的变量
第三个参数count是从从打开的文件中读取多少个字节
返回值类型是ssize_t,是有符号整型,在32位机器上等同与int,size_t 就是无符号型的ssize_t。返回-1表示读取失败;返回正整数代表成功读取的字节数。
如下,想把log.txt中的文件内容全部读取到变量buffer中:

readProcess.c
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
int main()
{
int fd = open("./log.txt",O_RDONLY ,0644);
if(fd < 0)
{
perror("open error!\n");
return 1;
}
char buffer[1024];
ssize_t s = read(fd,buffer,sizeof(buffer)-1);//文件不需要用\0来标记字符串结束
if(s > 0)
{
buffer[s] = 0;//读取成功后,手动字符串结尾加上\0
printf("%s\n",buffer);
}
close(fd);
return 0;
}读取结果如下:

(4)write
向打开的文件中写入内容:
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);第一个参数fd是打开的文件描述符
第二个参数buf是把的缓冲区buf中的内容写入到文件
第三个参数count是向文件中写入buf的count个字节
返回-1表示写入失败;返回正整数,表示成功向文件写入的字节数。
注意:
当向文件中写入字符串时,不需要写入字符串末尾的\0,因为文件关心的是字符串的内容,\0仅仅只是字符串结束的标志位,并不是需要写入到文件的内容,所以不需要把\0写进去。
如下代码,将字符串写入到文件中:
#include<stdio.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
int main()
{
int fd = open("./log.txt",O_WRONLY|O_CREAT,0644);
if(fd < 0)
{
perror("open error!\n");
}
char *buffer = "OK,just as the sushine\n";
ssize_t s = write(fd,buffer,strlen(buffer));//strlen没有包含\0,不需要把\0写进去
return 0;
}执行结果如下:

二、文件描述符
1.什么是文件描述符
open函数的返回值会返回一个文件描述符,可以看看这个文件描述符的值是多少:
#include<stdio.h>
#include<unistd.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{
int fd = open("./log.txt",O_CREAT | O_RDONLY,0644);
if(fd < 0)
{
printf("open error!\n");
}
printf("fd = %d\n",fd);
close(fd);
return 0;
}发现fd=3:

那如果多打开几个文件呢?文件描述符的值各是多少?
#include<stdio.h>
#include<unistd.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{
int fd1 = open("./log1.txt",O_CREAT | O_RDONLY,0644);
int fd2 = open("./log2.txt",O_CREAT | O_RDONLY,0644);
int fd3 = open("./log3.txt",O_CREAT | O_RDONLY,0644);
int fd4 = open("./log4.txt",O_CREAT | O_RDONLY,0644);
int fd5 = open("./log5.txt",O_CREAT | O_RDONLY,0644);
if(fd1 < 0 || fd2 < 0 || fd3 < 0 || fd4 < 0 || fd5 < 0)
{
printf("open error!\n");
}
printf("fd1 = %d\n",fd1);
printf("fd2 = %d\n",fd2);
printf("fd3 = %d\n",fd3);
printf("fd4 = %d\n",fd4);
printf("fd5 = %d\n",fd5);
close(fd1);
close(fd2);
close(fd3);
close(fd4);
close(fd5);
return 0;
}执行结果如下,发现文件描述符从3开始递增了:

文件描述符从3开始,那0、1、2去哪里了呢?
0标准输入:键盘
1标准输出:显示器
2标准输出:显示器
Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入0, 标准输出1, 标准错误2
因此连续打开多个文件时,底层给文件分配的文件描述符分别是:

这说明文件描述符就是一个数组的下标。
所有的文件操作,表面上看起来是进程执行对应的函数,也是进程对文件的操作,操作文件就必须先打开文件,并且将文件的相关属性信息加载到内存,而操作系统中存在大量的进程,且一个进程可以打开多个文件,有可能进程数:打开的文件数=1:n,那么操作系统就需要把打开的文件在内存也就是系统中管理起来,管理的方式------先描述,再组织。
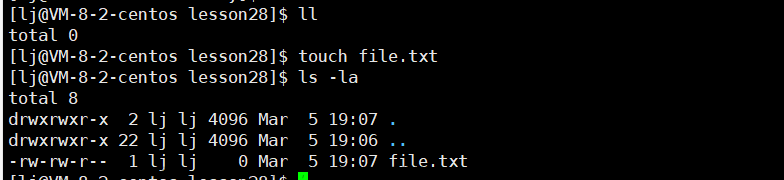
打开的文件在内存中,由操作系统做管理。文件没有打开时在磁盘上,由文件系统做管理,这时即便是一个空文件也需要占用磁盘空间的。比如当我们创建一个空文件时:

虽然它的大小是0KB,没有内容,但是它的属性是存在的,比如文件名称、修改日期、类型、大小、安全性能、详细信息、所有者、所属组、权限:

从以上可以看出,当我们创建一个文件时,文件要占用磁盘,文件有属性,属性也是数据。磁盘文件既包含文件内容,又包含文件属性。
之前对文件的所有操作,既有对文件内容的操作,也有对文件属性的操作。其中对文件内容的操作包括fread、fwrite、fgets、fputs。对文件属性的操作包括ftail、rewind、fseek、chmod、chgrp、mv更改文件名称。
操作系统管理文件采用先描述再组织的方式,那么操作系统是如何描述的?又是如何组织的呢?
打开文件时,要在内核里面设计对应的结构体,先把打开的文件描述起来,在内核当中描述打开的文件的结构体叫做struct file,文件在磁盘上已经有属性了,打开文件不过是把文件属性加载到特定内存,要加载一些内存当中特有的属性。因此当文件被打开时,在操作系统内部一定会维护struct file来表示一个已经被打开的文件——先描述。
struct file
{
//文件内容
//文件属性
}打开文件时,一定是先创建进程,这个进程可以打开多个文件,内核当中操作系统就要帮我们为每一个已经打开的文件,建立一个struct file结构,这个结构包含了文件的相关属性信息,如果一个进程打开了多个文件,那么在系统中会存在大量的struct file结构,操作系统会以双向链表的形式把所有struct file全部链接起来。

当操作系统管理进程时,有进程的列表。先描述再组织相关结构,如果要管理文件,也有文件相关的列表。打开的这么多文件,如何知道哪一个进程对应哪些文件?操作系统为了能够让进程和文件产生关联,让进程在内核当中包含一个结构file_struct,这个结构里包含了指针数组,所以task_struct也就是pcb当中包含一个指针指向file_struct的地址,数组里面包含的内容全部都是struct file类型的指针。

当打开文件时,把文件描述符描述起来,或者把文件和相关的struct对象描述起来之后,进程和文件如何关联?数组有0123下标,把对应的描述文件的结构体变量的地址写入到特定的下标里,这就相当于fd_array[0]指向了第一个文件。0、1、2文件描述符分别被申请成了保存键盘文件,显示器文件、显示器文件,保存着这三个文件各自的地址,对应标准输入、标准输出、标准错误。上层在调用这三个文件的时候就直接使用0、1、2即可调用。
因此当用户打开这三个文件之外的文件时,文件在磁盘中就被打开了,在内存里就需要形成struct_file结构,再把struct_file的文件描述符3分配给这个文件,会把这个结构体的地址填入下标为3的文件描述符内:

再把3返回给上层用户,此时就拿到了3这个下标。
成功打开文件的目的是要进行写入或者读取,不管是写入还是读取都是系统调用,且第1个参数都是文件描述符fd,那么问题来了。
在执行read或write的时候为什么要执行文件描述符fd呢?
进程执行read或write系统调用的同时把文件描述符fd传进来了,这个进程的task_struct能够通过自己的PCB找到自己打开的文件列表,然后根据文件描述符fd直接索引对应的数组,找到3号文件描述符里面的内容也就是上图存在fd_array[3]中的结构体地址,找到对应的文件,就可以对文件进行相关操作了。
为什么必须得有文件描述符呢?
当我们打开文件时,操作系统会描述文件的一些相关内容。操作系统要管理文件,必须先打开文件,只有打开文件,才能对文件进行相关操作,打开文件后,操作系统要对文件做管理,就要先描述再组织。
从以上不难看出,文件描述符的本质是内核中的进程和文件关联的数组的下标。
2.文件描述符的分配规则
先看以下代码:
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int main()
{
int fd = open("./log.txt",O_CREAT | O_WRONLY,0644);
printf("fd = %d\n",fd);
return 0;
}打印结果:

如果把标准输入关掉呢?那么fd_array数组的下标0就没有使用了,那么上述代码中的fd会变成什么呢?
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int main()
{
close(0);//把文件描述符0关掉
int fd = open("./log.txt",O_CREAT | O_WRONLY,0644);
printf("fd = %d\n",fd);
return 0;
}fd的值为0:

如果关闭文件描述符1呢?
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int main()
{
close(1);//关闭文件描述符1
int fd = open("./log.txt",O_CREAT | O_WRONLY,0644);
printf("fd = %d\n",fd);
}执行结果虽然没有打印到显示器,但是却打印到了log.txt中,这就说明关闭文件描述符1就关闭了向显示器的输出:


当打开文件log.txt时,操作系统内部会给log.txt形成一个struct_file并要求进程和struct_file对象产生关联,进程在文件描述符数组中搜索,发现1没有被人使用,因此1就指向了log.txt文件。

如果关闭文件描述符2呢?
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int main()
{
close(2);//关闭文件描述符2
int fd = open("./log.txt",O_CREAT | O_WRONLY,0644);
printf("fd = %d\n",fd);
}fd的值为2:

总结:
从以上可观察到,文件描述符的分配规则给文件分配的文件描述符是从fd_array中找一个最小的,没有被使用过的下标作为新的文件描述符。
这是由于当进程新打开一个文件时,需要把文件和进程关联起来,操作系统遍历fd_array找一个最小的没有被使用的下标,把文件结构体的地址填入到这个下标中,并返回该下标。

三、重定向
1.重定向概念
文件重定向即文件描述符重新选定自己的指向。语言层的标准输入、标准输出、标准错误、打开关闭函数的返回值类型都是FILE:
extern FILE *stdin;
extern FILE *stdout
extern FILE *stderr;
FILE *fopen(const char *path, const char *mode);这些方法都要向文件写入,文件是硬件,所以都要通过操作系统管理,FILE是C语言层面上的结构体。这些接口必须向下进行系统调用。语言层是上层,包含printf,fprintf, cin, cout等,系统层是下层,包括open,close, read, write, 语言层和系统层是上下级关系。所以当上层调用fread,fwrite,fopen这样的接口时,是通过FILE里面的文件描述符操控底层的,由于操作系统定义了底层,所以进程最后访问文件都是通过文件描述符做到的,所以文件描述符必须存在。
从前面的代码看出,如果关闭文件描述符1,log.txt的文件描述符变成1,printf只关心1,并不关心1对应的是标准输出还是文件,所以数组下标为1的元素填充的本应该是stderr结构体的地址,但是现在填充了log.txt的结构体地址,把本应该输出到显示器上的内容,都输出到了log.txt文件中,这就是输出重定向。

2.重定向分类
重定向分为输出重定向、输入重定向、追加重定向
(1)输出重定向
输出重定向:将命令的正常输出结果保存到指定的文件中,而不是直接显示在屏幕上
输入重定向有以下符号:
命令符号格式 |
作用 |
命令>文件 |
将命令执行的标准输出结果重定向输出到指定的文件中,如果该文件已包含数据,会清空原有数据,再写入新数据 |
命令>>分界符 |
将命令执行的标准输出结果重定向输出到指定的文件中,如果该文件已包含数据,新数据将写入到原有内容的后面 |
命令>文件
echo是重定向命令,使用echo进行重定向时,把echo进程的1关掉了,然后把log.txt文件打开,再把echo输出的所有内容打印到log.txt。

命令>>文件
追加时,对于文件中已有内容,不会清除或覆盖,会追加到原有内容后面:

(2)输入重定向
输入重定向:将命令中输入的途径由默认的键盘改为其他文件,而不是等待从键盘输入
输入重定向有以下符号:
命令符号格式 |
作用 |
命令<文件 |
把文件作为命令的输入设备 |
命令<<分界符 |
从标准输入设备(键盘)中读入,直到遇到分界符才停止(读入的数据不包括分界符),分界符是自定义的字符串 |
命令<文件1>文件2 |
将文件 1 作为命令的输入设备,该命令的执行结果输出到文件 2 中 |
命令<文件
比如,默认情况下,cat命令会接收标准输入设备也就是键盘的输入,并显示到控制台,相当于关闭了文件描述符0。如果用文件代替键盘作为输入设备,那么该命令会把指定的文件作为输入设备,并且读取文件的内容并显示到控制台。

执行结果虽然相同,但是第一行代表是以键盘作为输入设备,第二行代码是以log.txt文件作为输入设备。
命令<<分界符
指定"-"作为分界符,在输入-之前,就可以一直输入数据

命令<文件1>文件2
新建文件log1.txt,重定向log.txt作为输入设备,并输出重定向到log1.txt,这就将log.txt的内容复制到了log1.txt中。

四、dup2函数
之前的文件重定向,每次都必须把一个文件描述符关掉,再进行重定向到另一个文件描述符。假如在两个文件描述符都打开的情况下,如何完成重定向呢?dup2函数可以解决这样的问题。
dup2函数如下:
#include<unistd.h>
int dup2(int oldfd,int newfd);其中,oldfd是旧文件描述符,newfd是新文件描述符。dup2函数的作用是让newfd重定向到oldfd所指的文件上,如果出错就返回-1,否则返回的就是newfd。如果newfd已经被open过,那么就会先将newfd关闭,然后让newfd指向oldfd所指向的文件,即把oldfd赋值给newfd,如果newfd本身就等于oldfd,那么就直接返回newfd。因此,传入的newfd既可以是open过的,也可以是一个任意非负整数。
1.使用dup2写重定向
如下代码,使用dup2函数将本来应该写入到标准输出(显示器)的内容写入(显示)到log.txt文本中。newfd文件描述符1中本来存有标准输出的结构体地址,使用dup2后,将oldfd fd(log.txt的文件描述符)指向的进程的文件的结构体地址赋值给文件描述符1中存的结构体地址,此时文件描述符1就指向log.txt,向屏幕写入内容时,就显示到了log.txt文件中。
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int main()
{
int fd = open("./log.txt",O_WRONLY | O_TRUNC));//在向文件写入之前,先将文件清空
if(fd < 0)
{
perror("open");
return 1;
}
//dup2函数的作用是让newfd重定向到oldfd所指的文件上,int dup2(int oldfd,int newfd)
dup2(fd,1);//把本来应该显示到显示器的内容,写入到文件
printf("This is printf\n");
fprintf(stdout,"This is printf\n");
fputs("This is fputs\n",stdout);
return 0;
}结果如下:

printf、fprintf、fputs都是向stdout写入的,stdout只关心文件描述符1,而文件描述符1里面存的进程的文件结构体地址已经被改成了log.txt对应的文件描述符的结构体的地址,因此打印内容都被存入了log.txt文件中。
2.使用dup2读重定向
将log.txt的内容进行改变:

如下代码,使用dup2函数将本来应该从标准输入(键盘)读取内容变成从log.txt文本读取。newfd文件描述符0中本来存有标准输入的结构体地址,使用dup2后,将oldfd fd(log.txt的文件描述符)指向的进程的文件的结构体地址赋值给文件描述符0中存的结构体地址,此时文件描述符0就指向log.txt,从键盘读取内容时,实际上读取的是log.txt文件内容。
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int main()
{
int fd = open("./log.txt",O_RDWR);//读写打开
if(fd < 0)
{
perror("open");
return 1;
}
//dup2函数的作用是让newfd重定向到oldfd所指的文件上,int dup2(int oldfd,int newfd)
dup2(fd,0);//把本来应该从键盘读入的内容,变成从文件读入
char buffer[1024];
scanf("%s",buffer);
printf("%s\n",buffer);
return 0;
}结果如下:

scanf是从标准输入stdin读入的,stdin只关心文件描述符0,而文件描述符0里面存的进程的文件结构体地址已经被改成了log.txt对应的文件描述符的结构体的地址,因此读入的内容是log.txt文件的内容。
五、程序替换会影响文件描述符吗
前面学过,用fork创建出子进程后,子进程调用exec*函数来执行另一个程序,当进程调用exec*函数时,进程的用户空间的代码和数据完全被新程序替换,从新的程序开始执行。
那么使用exec*函数进行程序替换的时候,会不会影响曾经打开的文件呢?答案是不会,因为文件描述符这里是文件打开的相关数据结构,程序替换只会替换代码和数据,不会替换曾经打开的文件。

默认情况下,由exec*函数的调用程序所打开的所有文件描述符在exec*函数的执行过程中会保持打开状态,且在新程序中依然自动有效。在程序替换之前,文件会识别到重定向,并将子进程的文件描述符进行重定向,重定向之后再进行程序替换,比如:

替换之后,在echo里面打印结果的时候,就把内容打印到了文件里。
使用fork创建子进程会让子进程共享父进程的文件描述符:当创建子进程的时候,一定会形成一个新的task_struct、新的地址空间、新的页表,构建新的映射关系,同时也会形成新的file_struct结构体,这个结构体本来是属于进程的,父进程的file_struct会共享给子进程。子进程的数据有很多来源于父进程,以父进程为模板拷贝数据结构内容,所以task_struct中的属性信息拷贝过来了,file_struct对应的属性信息也要拷贝过来,因此父子进程的文件描述符表是一样的。
需要注意的是,创建子进程时,task_struct和file_struct会新建,但是虚线框中的stdin、stdout、stderr、log.txt都不会被新建,因为左侧紫色框部分是进程,右侧黑色虚线框部分是文件。创建进程时不关心文件,文件不会拷贝,会被共享。

因此文件没有变,这就导致父进程和子进程有可能指向同一个文件,因为子进程的文件指针继承自父进程。假如父进程曾经打开了标准输入、标准输出和标准错误,子进程也会继承下去。所以当父进程往显示器上打印的时候,子进程也可以向显示器上打印,它们同时在向显示器进行打印,所以父子进程打印的内容可能是交替的。
六、文件何时关闭
一个进程可以打开多个文件,一个文件也可以被多个进程打开,那么文件什么时候会被关闭呢?
在每个file_struct中存在一个count变量,第9行的f_count文件引用计数就是用来统计有多少个进程指向了该文件:
struct file{
union {
struct list_head fu_list; //文件对象链表指针linux/include/linux/list.h
struct rcu_head fu_rcuhead; //RCU(Read-Copy Update)是Linux 2.6内核中新的锁机制
} f_u;
struct path f_path; //包含dentry和mnt两个成员,用于确定文件路径
#define f_dentry f_path.dentry //f_path的成员之一,当统的挂载根目录
const struct file_operations //*f_op; 与该文件相关联的操作函数
atomic_t f_count; //文件的引用计数(有多少进程打开该文件)
unsigned int f_flags; //对应于open时指定的flag
mode_t f_mode; //读写模式:open的mod_t mode参数
off_t f_pos; //该文件在当前进程中的文件偏移量
struct fown_struct f_owner; //该结构的作用是通过信号进行I/O时间通知的数据。
unsigned int f_uid, f_gid; //文件所有者id,所有者组id
struct file_ra_state f_ra; //在linux/include/linux/fs.h中定义,文件预读相关
unsigned long f_version;
#ifdef CONFIG_SECURITY
void *f_security;
#endif
void *private_data;
#ifdef CONFIG_EPOLL
struct list_head f_ep_links;
spinlock_t f_ep_lock;
#endif
struct address_space *f_mapping;
};如果当前有一个进程指向这个文件,那么该文件的f_count++,当进程不指向这个文件时,f_count--,当f_count变为0时,file_struct才会被释放。
当创建子进程时,子进程有独立的file_struct结构,file_struct结构会继承父进程的数据,因此file_struct结构里面填入的文件地址和父进程相同,那么父进程和子进程指向的是同一个文件,从而子进程会继承父进程打开的文件,这就是为什么子进程会默认打开标准输入、标准输出、标准错误的原因,所有进程的父进程都是bash,因此所有进程都会默认打开标准输入、标准输出和标准错误。
七、缓冲区
1.关闭文件描述符之后
先看下面一段代码:
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int main()
{
close(1);
int fd = open("./log.txt",O_CREAT | O_WRONLY,0644);
printf("fd:%d\n",fd);
fprintf(stdout,"Souls of My People. The night is beautiful, so the faces of my people.\n");//这里的stdout只是fprintf的第一个参数流文件
return 0;
}将文件描述符1关掉后,按照文件描述符分配规则,使用最小的未被使用的数组下标1作为log.txt的文件描述符,fprintf把本该输入到标准输出的字符串输入到了log.txt文件中。

如果在上述代码最后15行添加close:
close(fd);会发现执行后,log.txt文件中没有内容:

2.缓冲区刷新策略
log.txt文件中没有内容是因为C语言提供了用户缓冲区。在【Linux】-- 开发工具yum、vim、gcc、g++、gdb、make、makefile使用介绍一文中第六节的进度条小程序,在使用printf打印时,如果不加"\n",那么数据就不会立即刷新出来,用户缓冲区是在语言层面实现的,使用printf或fprintf打印的字符串消息并没有直接写入到操作系统,通过stdout,把数据从用户缓冲区拷贝到C语言缓冲区,再通过系统调用接口利用文件描述符从用户缓冲区拷贝到内核缓冲区,再由操作系统定期把数据刷新到磁盘当中。如果通过fflush刷新,那么fflush刷新时将数据刷新到内核缓冲区,fflush在底层会调用接口把内核缓冲区刷新写入到磁盘当中。
C语言缓冲区把数据写入到内核缓冲区的过程就相当于把数据写入到文件中:

stdout的定义如下,发现其类型是FILE*的:
#include <stdio.h>
extern FILE *stdin;
extern FILE *stdout;
extern FILE *stderr;当打开文件时,文件有对应的内核缓冲区,再来看看FILE结构体,位于/usr/include/libio.h 文件中:
struct _IO_FILE
{
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno; //封装的文件描述符
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};其中第22行的fileno是封装的文件描述符,维护了C语言缓冲区的相关内容。这也就说明
extern FILE *stdout;中的FILE struct不仅封装了一个fd,还封装了文件描述符用来维护C语言缓冲区的相关内容,当执行close(fd);后进程退出了,文件描述符被关掉,数据还在C语言缓冲区中,但是C语言缓冲区的内容已经不被维护了,数据来不及刷新到内核缓冲区,因此log.txt文件里面就没有内容。
执行close(fd);后,fprintf所写的消息没有显示出来,也没有刷新到外设里面,而是保存到了FILE结构体相关的缓冲区里面,FILE结构体不仅仅有文件描述符,还有缓冲区。所以C语言调用接口时,对数据要进行格式化处理时,就得有数据格式化处理的区域,这个区域就是FILE。经过在FILE格式化处理后,在以下情况会从C语言缓冲区刷新到内核缓冲区:
(1)遇到"\n"
(2)进程退出时
当遇到"\n"或进程退出时,会把数据从用户缓冲区(C语言缓冲区)刷新到操作系统缓冲区(内核缓冲区),刷新策略如下:
1.立即刷新(不缓冲)
2.行刷新(行缓存"\n",如刷新到显示器)
3.缓冲区满了,才刷新(全缓冲),比如往磁盘文件中写入
以上策略也是操作系统缓冲区刷新到外设的刷新策略。
假如把第9行注释掉:
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int main()
{
//close(1);
int fd = open("./log.txt",O_CREAT | O_WRONLY,0644);
printf("fd:%d\n",fd);
fprintf(stdout,"Souls of My People. The night is beautiful, so the faces of my people.\n");//这里的stdout只是fprintf的第一个参数流文件
close(fd);
return 0;
}注释掉第9行就是不关闭文件描述符1,刷新策略就是行刷新,因为14行有"\n",刷新策略为行刷新,遇到"\n"就刷新到显示器了:

相反如果没有注释第9行,那么文件描述符1指向的就是log文件,fprintf要打印的内容就会重定向到log.txt文件,原本fprintf格式化的字符串有"\n",刷新策略是行刷新,现在重定向到文件中,就变成了全缓冲,数据拷贝到C语言缓冲区后,缓冲区的消息并没有被写满
当进程准备退出之前调用了close,文件描述符被关闭了,进程退出时,数据还在C语言缓冲区里,来不及刷新到内核缓冲区,因此log.txt文件里面没有对应内容。
当进程准备退出之前没有调用close,那么进程直接退出,数据会从C语言缓冲区刷新到内核缓冲区,使用cat查看log.txt文件时,会看到里面有数据了。
以下是立即酸辛的情况,使用fflush,那么进程退出前关闭文件描述符不会受到影响:
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int main()
{
//close(1);
int fd = open("./log.txt",O_CREAT | O_WRONLY,0644);
printf("fd:%d\n",fd);
fprintf(stdout,"Souls of My People. The night is beautiful, so the faces of my people.\n");//这里的stdout只是fprintf的第一个参数流文件
fflush(stdout);
close(fd);
return 0;
}由于使用fflush立即刷新,直接把写入到stdout的数据刷新到操作系统内部,不会被暂时写入到C语言缓冲区,所以进程退出前关闭文件描述符不会影响刷新:

FILE结构里面是包含用户缓冲区的,所以我们自己调用printf,fprintf,fwrite,fputs等C语言的接口,其实都是把所有的信息写道C语言的缓冲区,定期从C语言的缓冲区刷新到内核缓冲区,刷新的过程中要通过文件描述符和系统调用接口来把相关数据刷新到操作系统内部,底层用的是open和write,如果提前关闭了文件描述符,那么数据也不会刷新。如果没有关闭文件描述符,当数据写满时,就会把数据刷新到外设当中。
显示器的刷新策略是行刷新,文件描述符和刷新策略是没有对应关系的,因为有重定向在里面,所以如果要往显示器上刷新,那么刷新策略就是行刷新,往普通文件里面写就是全缓冲。当目标设备发生变化时,刷新策略也会自动变化,这是由C语言和操作系统自动帮我们实现的。
有以下代码:
#include<stdio.h>
#include<string.h>
#include<unistd.h>
int main()
{
const char *s1 = "Two roads diverged in a yellow wood\n";
write(1,s1,strlen(s1));
const char *s2 = "And sorry I could not travel both\n";
write(2,s2,strlen(s2));
printf("And be one traveler, long I stood\n");
fprintf(stdout,"And looked down one as far as I could\n");
close(1);
return 0;
}运行结果如下:

4个字符串都打印出来了,因为每个字符串的最后都是"\n",都是行刷新,往显示器上打印,在close(1)之前,所有消息都被刷新到显示器上了。
重定向时,只有标准错误没有被重定向,因为标准错误本来就是向2号文件描述符打印,标准错误是没有重定向的:

但是把文件描述符1重定向到了log.txt文件中,把本来应该显示到显示器的内容打印到了文件当中,但是发现log.txt中只有第1个字符串,没有第3个和第4个字符串:

这是因为代码第16行close了文件描述符1,本来是第3个和第4个字符串是往stdout C语言的缓冲区当中写的,数据会被暂时存在C语言的缓冲区,只不过重定向后,把本来应该显示到标准输出的内容显示到了文件当中,刷新策略是由目标文件类型决定的,由之前的行刷新变成了全缓冲,不立即刷新,当字符串数据准备刷新到内核缓冲区时,文件描述符被关了,所以这两条字符串数据来不及被刷新出来。
为什么第1条字符串会存在于log.txt中?write是系统调用,所以第1个字符串没有通过C语言的缓冲区把数据保存到内核缓冲区,因此关闭文件描述符1不影响第1条字符串。此时一关闭文件描述符,内核缓冲区的数据会直接刷新到磁盘。
因此第1条和第3、4条字符串写入或显示到哪里是由有没有向C语言缓冲区写入作为区分的。
再来看看fork函数和打印函数的关系:
#include<stdio.h>
#include<string.h>
#include<unistd.h>
int main()
{
const char *s1 = "Two roads diverged in a yellow wood\n";
write(1,s1,strlen(s1));
//C语言的接口
printf("And sorry I could not travel both\n");
fprintf(stdout,"And be one traveler, long I stood\n");
fputs("And looked down one as far as I could\n",stdout);
fork();
return 0;
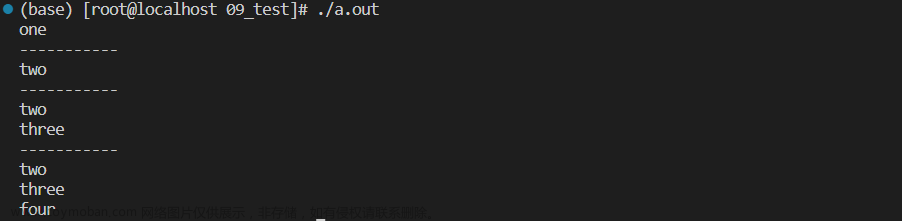
}4个字符串都打印在了标准输出上:

由于在打印了4个字符串之后,才进行fork,因此fork和打印没有关联。但是进行如果重定向,结果就不一样了:

重定向到文件之后,往显示器上打印时,刷新策略变了。第2、3、4条字符串先拷贝到了用户层的C语言缓冲区中,重定向到文件后,刷新策略由行缓冲变成了全缓冲,当数据没有把缓冲区写满时,数据就暂存在C语言缓冲区中,父进程调用了C语言的接口,缓冲区也在父进程当中,所以当fork之后,代码共享,写时拷贝,用户层C语言缓冲区没有刷新的时候,缓冲区里面的数据也属于父进程的数据,父子进程各自都有一份数据,进程退出时,C语言缓冲区的数据会被刷新出去,父子进程的数据都会被刷新,这就出现了因写时拷贝而产生的重复刷新。
如何解决重复刷新的问题呢?在fork之前使用强制刷新,已经刷新出去了,fork之后,缓冲区里没有数据了,就不会发生写时拷贝了:
#include<stdio.h>
#include<string.h>
#include<unistd.h>
int main()
{
const char *s1 = "Two roads diverged in a yellow wood\n";
write(1,s1,strlen(s1));
//C语言的接口
printf("And sorry I could not travel both\n");
fprintf(stdout,"And be one traveler, long I stood\n");
fputs("And looked down one as far as I could\n",stdout);
fflush(stdout);//在fork之前强制刷新
fork();
return 0;
}结果如下,没有重复刷新,把第2、3、4条字符串强制刷新出去了:

为什么write没有发生写时拷贝呢?
这是因为缓冲区在用户层,而不在操作系统层,printf和fprintf的底层都调用write,如果缓冲区在操作系统层,那么write的内容被重定向后,也会出现两份,但是系统调用没有,而C语言缓冲区出现了2份,说明缓冲区在用户层,因此所见到的缓冲区都叫做用户层缓冲区。此外Iostream和fstream都是类,类里面会包含缓冲区,缓冲区以字节为单位,不断往里面拷贝,也会按字节为单位不断拿走,这就叫做流。
八、文件系统
1.磁盘、磁道、扇区
磁盘是计算机中的一个机械设备,磁盘上的文件,是如何管理的呢?
假如在磁盘上创建一个空文件,空文件也要占用磁盘空间,因为它有文件属性,文件的内容和属性在系统看来都是数据,在磁盘看来都是01序列。假如文件没有被打开,那么文件就在磁盘上存放着。

盘面、柱面、扇区、磁道示意图如下:

其中,一个磁盘由多个盘片叠加而成,一个盘片可能会有两个盘面,每个盘面被划分为一个个磁道,盘面上的每一个半径不同的圈都是磁道,每个磁道都被划分为多个同样大小的扇区,上下多层磁道合起来就叫做柱面。

扇区是磁盘的最小存储单元,可用(盘面号,磁道号,扇区号)来定位任意一个"磁盘块", 根据该地址先找到盘面(磁头),再找到磁道,最后再找到扇区,为了提高效率,操作系统一次不会只读取一个扇区,而是读取多个扇区,也就是读取一个"块","块"是操作系统最小的存取单位,一般大小为4KB。
把数据刷新到磁盘,其实就是操作系统把数据写入到盘片上,操作系统认为磁盘是线性结构:

根据上图,磁盘线性结构可以当作一个数组,要访问某一个扇区,就只需要定位到扇区当中所对应的数组的下标,下标也是抽象出来的地址(Logic block address),实际上当访问磁盘时,就是再操作系统里面访问下标,即Logic block address。如果要把数据写入磁盘,那么一定要在物理磁盘上把Logic block address虚拟地址转化成物理磁盘地址。
2.理解文件系统和inode
(1)磁盘分区
如果磁盘比较大,可以使用分区的方式对磁盘进行管理,即大磁盘,小空间的方式管理。MBR(Master Boot Record主引导记录)文件系统示意图如下:

MBR磁盘指的是采用MBR启动的物理硬盘,其中MBR分区表的大小是固定的,只能容纳4个主分区信息。所以MBR磁盘最多创建4个主分区(3个主分区+扩展分区)。
那么计算机开机的时候时如何知道有几个磁盘分区呢?由于计算了boot block的大小,剩下的空间可以拆分成几个小空间,因此研究文件系统也就变成了研究如何管理block group,以Linux ext2文件系统为例:

一个block的大小是由格式化的时候确定的,并且不可以更改。例如mke2fs的-b选项可以设 定block大小为1024、2048或4096字节。而上图中启动块Boot Block的大小是确定的。上图中:
Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相 同的结构组成。
Super Block:存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量, 未使用的block和inode的数量,一个block的大小和一个inode的大小,最近一次挂载的时间,最近一次写入数据的 时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个 文件系统结构就被破坏了。
Group Descriptor Table:组描述符表。由很多组描述符组成,整个分区分成多少个组就对应有多少个组描述符。每个组描述符(Group Descriptor)存储一个组的描述信息,例如在这个组中从哪里开始是inode表,从哪里开始是数据块,空闲的inode和数据块还有多少个也就是inode Bitmap和BlockBitmap的使用情况等等。
Block Bitmap:Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没 有被占用 。
inode Bitmap:inode位图,每个bit表示一个inode是否空闲可用。
inode Table:inode表,存放文件属性,如文件大小,所有者,最近修改时间等。
Data Blocks:数据区,存放文件内容
(2)inode
文件数据在磁盘上都储存在"块"中,那么很显然,还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。inode Table里面包含了多个inode,每一个文件都有对应的inode,每个inode大小为128KB或256KB,每个inode里面包含了与该文件有关的一些信息:
文件的字节数
文件拥有者的User ID
文件的Group ID
文件的读、写、执行权限
文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
链接数,即有多少文件名指向这个inode
文件数据block的位置
可以使用
stat filename命令来查看文件的inode信息:

其中:
Access:最后访问时间,读取时间
Modify:文件内容最后修改时间
Change:属性最后修改时间
修改文件内容时,有可能会更改文件的属性,比如文件大小可能会被修改,会导致Modify、Change时间发生变化。makefile和gcc会根据时间问题,来判定源文件和可执行程序谁更新,来指导系统需要对哪些源文件重新编译。
(3)创建文件的过程
从以上可以看出,磁盘是将inode Table和Data Blocks分开存放的,也就是将文件属性和文件内容数据分开存放,它们是如何工作的呢?
现在新建一个文件Log.txt:

在linux中,文件名在系统层面没有意义,是给用户使用的,每个文件都有唯一对应的inode编号,Linux中真正标识一个文件,是通过文件的inode编号来标识的。上图通过ls -i命令查看到log.txt文件的inode编号为1179930。
将文件系统简化一下,只保留inode Table和Data Blocks,可以看到创建文件后操作系统如何为文件分配inode编号的过程:

具体执行过程如下:
1. 存储属性
内核先找到一个空闲的i节点(这里是1179930)。内核把文件信息记录(创建时间、用户ID、权限等)到其中。
2. 存储数据
该文件需要存储在三个磁盘块,内核找到了三个空闲块:200,204,207。将内核缓冲区的第一块数据复制到200,下一块复制到204,以此类推。
3. 记录分配情况
文件内容按顺序200,204,207存放,内核在inode上的磁盘分布区记录了上述块列表。
4. 添加文件名到目录
为inode编号和文件名增加映射关系
linux如何在当前的目录中记录这个文件?内核将入口(1179930,log.txt)添加到目录文 件。文件名和inode之间的对应关系将文件名和文件的内容及属性连接起来。 所以创建文件的本质就是把新增加的inode编号和文件名的映射关系添加到目录当中。
那么问题来了,在创建文件时,在inode table里面申请空间就一定能申请到吗?如何知道申请的是哪一个空间呢?把每一个inode都遍历一下确定哪个inode没有被使用的做法效率太低了,查找未被使用的数据块也同理,inode Bitmap和block Bitmap用来解决这个问题。
当touch文件时,为了能够快速申请到inode,只需要把inode Bitmap位图加载到内存当中,再使用位操作进行查找,比如10110011的第2个bit位为0,那么就可以把新创建的文件属性填入到第2个inode就可以了。Block Bitmap也同理。

所以,查找文件,只需要再inode Table中找到inode编号,就能找到inode的属性和对应的数据块。当查看一个文件时,经历了以下过程:
cat log.txt
1.查看fdProcess的Data blocks
2.在Data blocks目录中根据1179930:log.txt的映射关系,找到inode编号
3.去inode Table里面找inode
4.通过inode 1179930找到对应的block数据块列表编号
5.在block中找到对应的数据块
删除文件时经历了以下过程
rm log.txt
1.在fdProcess目录中直接找到log.txt的数据块,根据1179930:log.txt的映射关系,找到inode编号
2.删除文件不需要修改inode table,直接把inode bitmap由1置为0
3.通过inode 1179930找到对应的block
4.把Data bitmap 中block数据块列表编号的bitmap由1置为0
这就是为什么拷贝文件比删除文件所花费的时间长的原因。究其原因,还是因为删除文件并不会真的删除文件的属性和数据,而是把文件由有效置为无效即可,不会修改inode,会修改inode Table。下次再创建该文件时,根据inode,把inode Bitmap和Block Bitmap的位由0置1。
3.软链接和硬链接
(1)软连接
创建软链接
软链接是通过文件名引用另外一个文件,可以使用如下命令创建软链接:
ln -s source target现在创建softLinks.txt的软链接softLinks_copy.txt:

现在已经建立了软链接softLinks_copy.txt,指向了softLinks.txt
删除软链接
使用如下命令可删除软链接:
unlink softLink_filename比如删除软链接softLinks_copy.txt:

软链接使用场景
假如在/home/delia/linux/20230313-IO/fd/shellEcho路径下创建shell脚本echo.sh:
#!/bin/bash
echo "Two roads diverged in a yellow wood"
如果不在shellEcho目录下运行echo.sh脚本,而想在其他目录下比如fileLink目录中运行脚本呢?

如果不使用软链接,就得使用绝对路径来运行脚本:

有时候绝对路径比较长,定位起来较麻烦,就可以创建软链接。在fileLink中创建软链接引用shellEcho下的echo.sh文件:

软链接像是windows下的快捷方式。
可以看到软链接的源文件和目标文件都有各自的inode:

源文件和目标文件是独立文件,所以有自己的结构体、数据块、属性等等
(2)硬链接
磁盘上每个文件都有对应的inode,Linux中查找文件不是通过文件名,而是通过inode来查找的,其实在Linux中可以让多个文件名对应同一个inode,硬链接就让源文件和目标文件对应同一个文件名,可以使用如下命令创建硬链接:
ln source target使用touch创建hardLink文件后,只有一个文件名和inode建立了映射关系,看到硬连接数为1:

现在创建hardLink.txt的硬链接,硬连接数变成了2,有两个文件名和同一个inode建立了映射关系,并且源文件和目标文件的inode是一样的:

假如再对hardLink.txt创建一个硬链接呢?硬件连接数变成了3,有三个文件名和同一个inode建立了映射关系,并且hardLink 3个文件的inode是一样的:

inode结构体里面有一个成员是链接数,即当前有多少个文件名指向这个inode,如果有文件指向这个inode,那么链接数++,如果某个文件不指向这个inode,那么链接数--,如果链接数变成0,那么该文件就被删掉了。
因此软硬连接的根本区别在于文件是否具有独立的inode。
需要注意的是刚创建新目录时,链接数不是1,而是2,其中一个是目录自身,另外一个是"."也就是当前目录:

在目录里面再创建一个目录时,inode编号为1179961的链接数就变成了3:

九、动态库和静态库
1.动静态库概念
静态库(.a):程序在编译链接的时候把库的代码链接到可执行文件中,程序运行的时候不再需要静态库,以.a为后缀。
动态库(.lib):程序在运行的时候采取链接动态库的代码,多个程序共享使用库的代码,以.so为后缀。
使用以下命令
ldd exe_name(可执行程序名)可以查看可执行程序依赖了哪些动态库:

看一下libc.so.6:

libc-2.17.so是C语言的标准库,标准库是系统当中的文件,会包含C语言大部分用的内容。既然动静态库是文件,那么也是磁盘上的文件:

对于库文件的命名,从libc-2.17.so的后缀.so就能看出来libc-2.17.so是动态库。动静态库的命名规则如下:

那么libc-2.17.so库的真实名字是c-2.17。
来看看C++的标准库,写一个C++程序:
#include<iostream>
int main()
{
std::cout << "Two roads diverged in a yellow wood" << std::endl;
}使用ldd命令可以看到可执行程序依赖的库:

可以看到libstdc++.so.6也是一个软链接:

2.静态链接和动态链接
静态编译程序时需要加static关键字,对于如下代码:
#include<stdio.h>
int main()
{
printf("Two roads diverged in a yellow wood\n");
return 0;
}Makefile,使用static关键字编译程序:
fdTest:fdTest.c
gcc -o $@ $^ -static
.PHONY:clean
clean:
rm -f fdTest编译,可以看到静态链接体积很大:

file命令查看fdTest-static的文件类型,可以看到,fdTest-static采用的是静态链接:

查看libc下的静态库和动态库:

一般服务器可能没有内置语言的静态库,只有动态库,可以通过yum安装C/C++静态库。
静态链接把依赖的代码拷贝进可执行程序,当编译程序时,通过链接库找到像printf、scanf这些系统函数,把这些模块拷贝编译到可执行程序里,当启动可执行文件时,所有模块都被加载进来,因此可执行程序的体积比较大,一旦形成就不再依赖库了。
优点:加载速度快,执行速度快
缺点:体积大;如果库更新,需要重新编译程序;多个程序使用静态链接,会被装载多次,浪费内存。
动态链接是把要关联的函数先关联起来编译成动态链接库,不进行任何拷贝行为,当执行程序时,这些模块不会被加载,需要执行哪个库函数时直接跳转到哪个库函数当中就行了。
优点:体积小;多个程序可以使用同一个动态库,不需要在磁盘上存储多个拷贝。
缺点:可移植性低;如果库缺失,程序无法运行。
3.如何打包并使用静态库
库文件是二进制的,但是头文件是文本的。完整的库包含以下内容:
1.库文件
2.头文件
3.说明文档(说明库中暴露出来的方法的基本使用)
库文件位置:
Linux的库安装在/lib64和/usr/lib目录下:


头文件位置:

说明文档位置:

在写代码时,为什么要把函数声明放在头文件里,把函数实现放在源文件里呢?因为以这种方式制作的库,会对源文件进行封装保护,不仅方便使用,而且私密性比较高。如【数据结构】栈-C语言版中,完整代码段。
编译型语言适合制作库,可以编译成二进制,这样就能分离头文件和源文件。
现在试着做一个库,在libTest下有4个文件,分别是add.h,add.c,sub.h,sub.c, 在libTestFolder下有1个文件test.c:

libTest/add.h
#pragma onde
#include<stdio.h>
extern int add(int x,int y);libTest/add.c
#include "add.h"
int add(int x,iny)
{
return x + y;
}libTest/sub.h
#pragma once
#include<stdio.h>
extern int sub(int x,int y);libTest/sub.c
#include "sub.h"
int sub(int x,inyt y)
{
return x - y;
}test.c
#include "./libTest/add.h"
#include "./libTest/sub.h"
int main()
{
int x = 60;
int y = 50;
int result1 = add(x,y);
int result2 = sub(x,y);
printf("result1 = %d\n",result1);
printf("result2 = %d\n",result2);
return 0;
}由以上可以看到libTest文件夹里面没有main函数,只有add.c sub.c源文件和add.c sub.c对应的文件add.h sub.h。而test.c只包含了头文件,没有源文件即函数实现,虽然函数实现在libTest文件夹里,但是gcc编译器不知道啊,因此要指定目录和源文件。如果没有库的话,该怎么编译呢?创建Makefile文件,和libTest、test.c同级:
obj=test.o add.o sub.o #test.o add.o sub.o比较长,提取出来作为一个变量
test:$(obj) #test可执行文件依赖于test.o add.o sub.o
gcc -o $@ $^
%.o:%.c #test.o依赖于test.c,根据源文件自动推导形成.o
gcc -c $<
%.o:./libTest/%.c #add.o sub.o依赖于add.c sub.c
gcc -c $<
.PHONY:clean
clean:
rm -f *.o test$@ 表示目标文件
$^ 表示所有的依赖文件
$< 表示第一个依赖文件
$? 表示比目标还要新的依赖文件列表
执行make命令后,生成了add.o sub.o test.o目标文件和test可执行文件:

发现可执行文件执行成功:

这说明,如果现在有许多源文件和头文件给对方用,可以有两种方式:
直接给对方提供源文件和头文件
将程序打包成静态库
如果不想给对方源文件和头文件,可以采用第二种,那么如何打包成静态库呢?打包之前,需要了解打包命令和参数。
(1)静态库打包命令及参数
ar 备份压缩命令,常用来将多个目标文件(*.o)打包为静态链接库文件(*.a)
-r:静态库文件当中的目标文件有更新,则用新的目标文件替换旧的目标文件
-c:生成静态库文件
-t:列出静态库中的文件
-v:程序执行时显示详细的信息gcc 将源代码生成可执行程序
-L:指定库路径
-l:指定库名
-I:制定头文件路径(2)如何打包生成静态库
第1步:生成目标文件和静态库
只给对方提供.o文件,对方也可以用来链接,将所需的.o文件打包起来就是库,这里只需要把add.o和sub.o打包成静态库就可以了。现在来写打包的Makefile,切换到libTest文件夹下,创建Makefile文件:

Makefile:
libcaculate.a:add.o sub.o #caculate为库名,依赖于add.o sub.o
ar -rc $@ $^
%.o:%.c #add.o sub.o依赖于add.c sub.c
gcc -c $<生成libcaculate.a静态库:


查看一下libcaculate.a里面的内容:

有add.o和sub.o。如同libc.a一样,里面全部都是.o文件。这样就把源文件隐藏起来了。
第2步:将静态库和头文件组织起来
现在对方拿到了静态库,但是对方并不知道静态库里面有什么方法,所以需要把头文件也同步给对方,修改Makefile。把头文件和静态库拷贝到到同一个文件夹output中:
libcaculate.a:add.o sub.o
ar -rc $@ $^
%.o:%.c
gcc -c $<
.PHONY:clean
clean:
rm -rf *.o output libcaculate.a #同时删除.o文件 output文件夹和libcaculate.a库
.PHONY:output
output:
mkdir output
cp -rf *.h output
cp libcaculate.a output执行的时候,先make,再make output,可以看到头文件和静态库都被拷贝到output文件夹了:

给别人头文件和静态库时,把output文件夹给别人就可以了。
(3)如何使用别人给的静态库
现在要在另一个文件夹libUse下使用静态库,创建libUse文件夹后,将test.c和Makefile文件移动到libUse文件夹下,在libUse中创建lib文件夹,并将libTest/output文件夹的内容全部移动到libUse/lib中:

现在对test.c文件进行编译,使用如下命令:
gcc 源文件 -I.头文件路径 -L.库文件路径 -l库名称 -o 目标文件执行结果如下所示:

这样就成功使用了别人给的静态库。

可以把编译命令放到Makefile文件中:
test:test.c
gcc -o $@ $^ -I./lib -L./lib -lcaculate
.PHONY:clean
clean:
rm -f test执行也是OK的:

再使用ldd命令,发现好像并没有依赖刚刚的静态库caculate:

其实不是没有,而是程序已经被拷贝到了test中,因为制作完静态库后,给别人交付的其实是库文件+头文件。
库的搜索路径一般有以下几种:
1.由左到右搜索-L指定的目录
2.由环境变量指定的目录 (LIBRARY_PATH)
3.由系统指定的目录:/usr/lib和 /usr/local/lib等
4.如何打包并使用动态库
(1)动态库打包命令及参数
要形成动态库,就要把所有.o打包,-share形成一个动态链接的共享库。
生成动态库参数:
1.shared:形成动态链接的共享库
2.fPIC:产生位置无关码
3.库名规则:libxxx.so
这里要强调一下fPIC参数:
1.-fPIC只在编译阶段使用,告诉编译器产生与位置无关的代码,这份代码只使用相对地址,没有绝对地址,所以才与位置无关,因此代码可以被加载器加载到内存的任意位置。而共享库就要求共享库被加载时,在内存的位置不是固定的。
2.如果不使用-fPIC选项,那么加载.so文件的代码段时,代码段引用的数据对象需要重定位,重定位会修改代码段的内容,这就造成每个使用这个.so文件代码段的进程在内核里都会生成这个.so文件代码段的拷贝,这个.so文件代码段和数据段内存映射的位置不一样,那么每个拷贝都不一样。
3.不加-fPIC编译出来的.so是要在加载时根据加载到的位置再次重定位的,因为它里面的代码BBS位置无关代码。如果该.so文件被多个应用程序共同使用,那么它们必须每个程序维护一份.so的代码副本(因为.so被每个程序加载的位置都不同,显然这些重定位后的代码也不同,当然不能共享)。
4.用-fPIC来生成.so,但从来不用-fPIC来生成.a。但是.so一样可以不用-fPIC选项进行编译,只是这样的.so必须要在加载到用户程序的地址空间时重定向所有表目。
(2)如何打包生成动态库
第1步:生成目标文件和动态库
现在要制作动态库,需要修改libTest下的Makefile:

做如下修改:
libcaculate.so:add.o sub.o
gcc -shared -o $@ $^
#生成.o目标文件,程序内部的地址方案是:与位置无关,库文件可以在内存的任何位置加载,且不影响其他程序的关联性。
%.o:%.c
gcc -fPIC -c $<
.PHONY:clean
clean:
rm -f libcaculate.so add.o sub.o执行make之后,生成了add.o、sub.o和libcaculate.so文件:

使用file命令来识别文件类型,可以看到libcaculate.so的文件类型是动态库:

第2步:将动态库和头文件组织起来
现在对方有了动态库,但是对方并不知道动态库里面有什么方法,所以需要把头文件也同步给对方,修改Makefile。把头文件和动态库拷贝到到同一个文件夹lib中:
libcaculate.so:add.o sub.o
gcc -shared -o $@ $^
#生成.o目标文件,程序内部的地址方案是:与位置无关,库文件可以在内存的任何位置加载,且不影响其他程序的关联性。
%.o:%.c
gcc -fPIC -c $<
.PHONY:clean
clean:
rm -f libcaculate.so add.o sub.o
.PHONY:lib
lib:
mkdir lib
cp *.h lib
cp libcaculate.so lib执行过程如下:

删掉libUse中的可执行文件:

(3)如何使用动态库
现在要在另一个文件夹libUse下使用动态库,libUse文件夹已经有test.c和Makefile文件,将lib文件夹复制到libUse文件夹下:

那么对方就有了一个lib文件夹,lib里面就包含了动态库文件,对方如何使用这个库呢?Makefile如下:
test:test.c
gcc -o $@ $^ -I./lib -L./lib -lcaculate
.PHONY:clean
clean:
rm -f test执行结果如下,虽然形成了test可执行文件,但是运行可执行程序发现报错,找不到动态库.so:

使用ldd命令查看可执行程序依赖的库,发现找不到动态库:

C/C++程序要运行,必须要先使用加载器加载到内存中,这就要用到exec*系列程序替换函数,它们充当了加载器,把库和磁盘当中的程序加载到内存。而加载器在运行的时候,进一步告知系统,我们的库在哪里。程序编译链接运行的时候都需要动态库,编译命令
gcc -o $@ $^ -I./lib -L./lib -lcaculate只是告知编译器头文件库路径在哪里,当程序编译好的时候,头文件路径和库文件路径此时已经和编译无关了,因此通过ldd命令找不到动态库。那么静态库为什么没有出现这样的问题呢?因为静态库在运行时不需要找库,因为程序已经被拷贝到了可执行文件中。
对于动态库要解决这个问题,有以下3种做法:
把动态库和头文件都拷贝到系统路径下:
cp 动态库 /lib64
更改动态查找库的路径:
LD_LIBRARY_PATH用来告诉加载器在哪些目录中可以找到共享库,可以为LD_LIBRARY_PATH设置多个搜索目录, 这些目录之间用冒号分隔开。
echo LD_LIBRARY_PATH=$LD_LIBRARY_PATH:绝对路径
但是假如退出shell,再重新登录,就会发现动态库的查找路径为空:

如果能够把动态库查找路径保存起来就更好了。
配置动态库配置文件:
环境变量默认在系统里面没有配置,存放的都是.conf配置文件,配置文件里面存放的都是路径。系统自动在/etc/ld.so.conf.d/路径下找.conf配置文件里面的路径下查找所需的库。
第一步:把库文件绝对路径存放在.conf文件中:

第二步:把.conf文件拷贝到/etc/ld.so.conf.d/路径下:

第三步:使用ldconfig命令更新动态库配置文件/etc/ld.so.conf,这样可共享的动态链接库也就更新。
此时使用ldd命令,发现还是not found:文章来源:https://www.toymoban.com/news/detail-468452.html

使用ldconfig命令后:文章来源地址https://www.toymoban.com/news/detail-468452.html
sudo ldconfig
到了这里,关于【Linux】-- 基础IO和动静态库的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!