一致性哈希算法是1997年由麻省理工的几位学者提出的用于解决分布式缓存中的热点问题。大家有没有发现,我们之前介绍的例如快排之类的算法是更早的六七十年代,此时分布式还没有发展起来,
大家往往还在提高单机性能。但是九十年代开始,逐渐需要用分布式集群来解决大型问题,相应的算法研究也就应运而生。
在说到一致性哈希算法,我们还是得先从缓存的发展谈起:
缓存,我们一般是用来提速的,当规模或者说数据量小时,我们往往用单机来部署一套缓存系统即可,如下图:

多台客户端在查询数据时,只要根据key进入缓存服务器查询到自己想要的内容即可。
但是随着业务的发展,单一的缓存服务器往往无法支撑住我们的业务需要。比如缓存数据太大,多城多活的网络部署等,
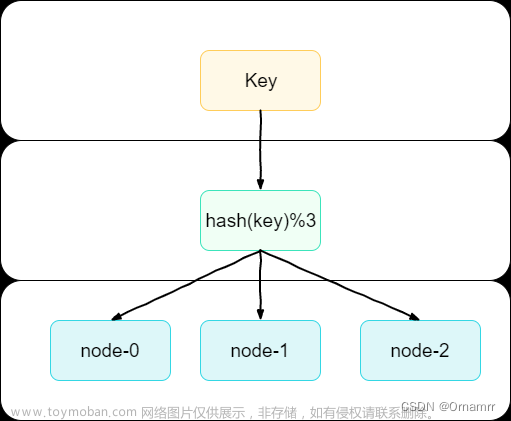
我们就需要多台缓存服务器来支撑,如下图:

客户端需要查询缓存时,先根据哈希算法,讲key进行计算,得到哈希值。然后通过哈希值对机器数取模(%n)来判定落在哪台机器上。
这个架构很简单,也很易实现,我们就不多说了。(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )
但是这里会存在一个缓存服务器伸缩的问题:什么意思呢?比如目前是三台,我们由于业务的需要,需要变为四台,或者变为两台。那么我们需要调整一遍所有数据所处的服务器位置,因为他们存在的位置都有可能改变。

分布式缓存本来就是为了解决大数据量问题的,此时重新调整,势必会极度影响可用性。那么如何解决呢?
来看看一致性哈希算法的思路:
我们假设存在一个虚拟环,这个环足够大,上边存在2^32个节点,三台器机器呢,我们根据id计算出他们在环中所处的位置,如图所示:

文章来源地址https://www.toymoban.com/news/detail-468555.html
当我们计算数据所处的缓存位置,不再是根据n来取模,而是根据2^32来取模,此时会有相当多的数据并没有落在缓存服务器所处的节点上。
那怎么办呢?我们按照顺时针方向计算,将数据落在下一个最近的顺时针节点上。
如下图所示:

这样当我们新增或者删除节点时,只会影响有限的节点上的数据,极大的缩小了受影响的节点和数据。我们只需要重新计算受影响的数据即可,但是这样还会存在新的问题:
1、缓存服务器计算出的位置不均匀,导致覆盖的节点数差异明显;(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )
2、数据并不均衡:数据经过哈希和取模运算后,可能落在集中的一片区域中,造成对应的缓存服务器的数据特别大。
以上问题我们称之为数据倾斜。数据倾斜的程度明显后,可能会导致所解决的问题再次出现(前文中的红字部分)。
那如何解决这种问题呢?很简单,加节点,只要节点足够多,那么就会越来越趋于平均,数据倾斜的情况就会越不突出。但是缓存服务器是有限的,并不是想加多少都可以的。
那怎么办呢?
我们可以采用虚拟缓存节点的形式解决问题。什么是虚拟缓存节点,就是并不实际存在的缓存节点。只是一个虚拟的点。
每个真实的缓存服务器对应多个虚拟缓存节点,两者是一对多的关系,如下图所示:

虚拟节点--图中连接在环上的就是虚拟缓存节点。
真实缓存节点--Cache
每个Cache对应若干的虚拟节点。当增减Cache时,我们只要调整对应的虚拟节点所对应的数据即可。文章来源:https://www.toymoban.com/news/detail-468555.html
到了这里,关于谈谈一致性哈希算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!