注意力
注意力分为两步:
- 计算注意力分布
α
\alpha
α

- 其实就是,打分函数进行打分,然后softmax进行归一化
- 根据
α
\alpha
α来计算输入信息的加权平均(软注意力)
- 其选择的信息是
所有输入向量在注意力下的分布
- 其选择的信息是

- 打分函数

- 只关注某一个输入向量, 叫作硬性注意力( Hard Attention)

- 本质上,从所有输入向量里面选一个向量(最具代表性)
键值对注意力

- Q-V 和 Q-KV结构对比

- 机器翻译的例子

- CNN中的注意力


各种注意力的定义

多头注意力:
与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的h组不同的 线性投影(linear projections)来变换查询、键和值。然后,这h组变换后的查询、键和值将并行地送到注意力汇聚中。 最后,将这h个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。这称为多头注意力。
- 对于h个注意力汇聚输出,每一个注意力汇聚都被称作一个头(head)。
自注意力:在深度学习中,经常使用卷积神经网络(CNN)或循环神经网络(RNN)对序列进行编码。
有了注意力机制之后,我们将词元序列输入注意力池化中, 以便同一组词元同时充当查询、键和值。 具体来说,每个查询都会关注所有的键-值对并生成一个注意力输出。 由于查询、键和值来自同一组输入,因此被称为 自注意力(self-attention)
位置编码:
- 在处理词元序列时,循环神经网络是逐个的重复地处理词元的, 而自注意力则因为并行计算而放弃了顺序操作。
- 为了使用序列的顺序信息,通过在输入表示中添加 位置编码(positional encoding)来注入绝对的或相对的位置信息。
- 位置编码可以通过学习得到也可以直接固定得到。
在位置嵌入矩阵P中, 行代表词元在序列中的位置,列代表位置编码的不同维度。
- Layer Normalization
- 残差连接
- Masked mutil-head attetion
- mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。
- 其中,padding mask 在所 有的 scaled dot-product attention 里面都需要用到
- sequence mask 只有在 decoder的 self-attention 里面用到,sequence mask 是为了使得 decoder 不能看见未来的信息。
Transformer概念理解


- 细节详解
克服的问题:
- RNNs的序列模型,串行编码具有天然的顺序属性,但是不能并行
- CNN可以并行,但是是局部连接,且无顺序属性
- 解决:用CNN去代替RNN,让CNN有重合部分达到连续的效果


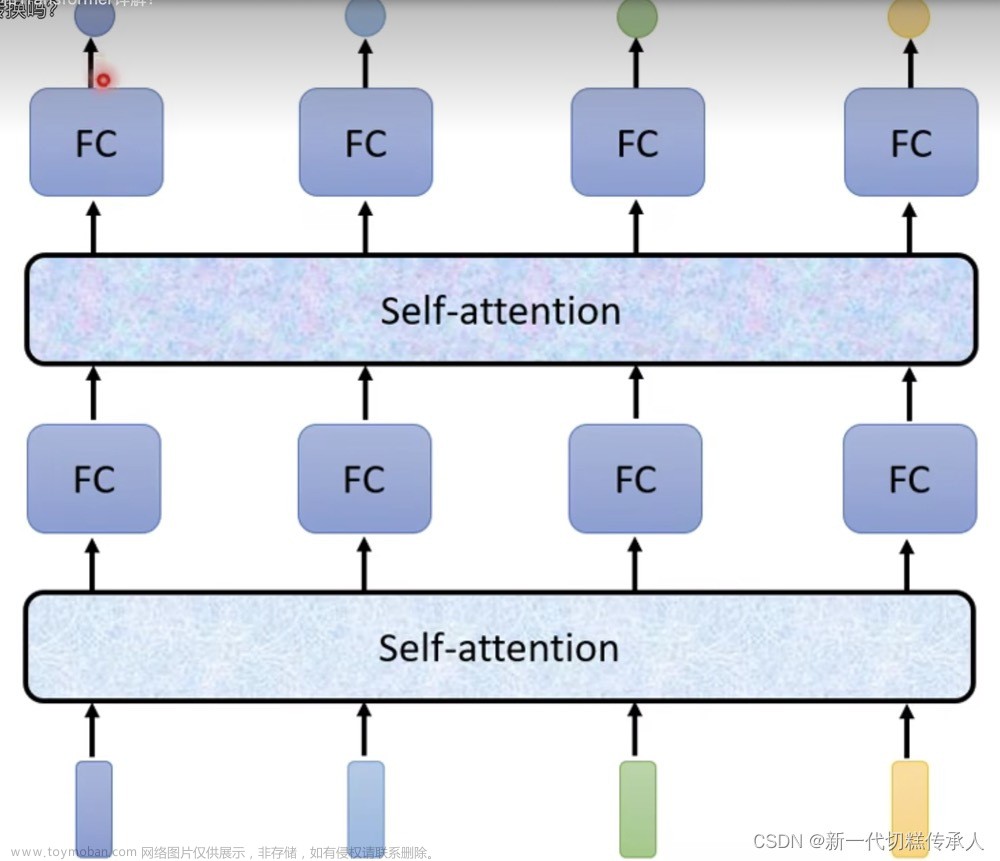
self-attendtion
- 把一个输入的向量拆成3个特征图,qkv是三个不同的权重矩阵


- 记住这句核心话,拿着每个query去对每个key做attendtion运算

-
α
\alpha
α权重要归一化

- 计算得到QKV矩阵


Demo to understand






Transformer Encoder
- 位置编码
- 层归一化
- 直连边
- 逐位的FNN



- 当使用神经网络来处理一个
变长的向量序列时,我们通常可以使用卷积网络或循环网络进行编码来得到一个相同长度的输出向量序列。
- 如何建立非局部(Non-local)的依赖关系 ->
自注意力模型

Transformer Code详解
Enbedding

class PositionalEncoding(nn.Module):
"""
compute sinusoid encoding.
"""
def __init__(self, d_model, max_len, device):
"""
constructor of sinusoid encoding class
:param d_model: dimension of model
:param max_len: max sequence length
:param device: hardware device setting
"""
super(PositionalEncoding, self).__init__()
# same size with input matrix (for adding with input matrix)
self.encoding = torch.zeros(max_len, d_model, device=device)
self.encoding.requires_grad = False # we don't need to compute gradient
pos = torch.arange(0, max_len, device=device)
pos = pos.float().unsqueeze(dim=1)
# 1D => 2D unsqueeze to represent word's position
_2i = torch.arange(0, d_model, step=2, device=device).float()
# 'i' means index of d_model (e.g. embedding size = 50, 'i' = [0,50])
# "step=2" means 'i' multiplied with two (same with 2 * i)
self.encoding[:, 0::2] = torch.sin(pos / (10000 ** (_2i / d_model)))
self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / d_model)))
# compute positional encoding to consider positional information of words
def forward(self, x):
# self.encoding
# [max_len = 512, d_model = 512]
batch_size, seq_len = x.size()
# [batch_size = 128, seq_len = 30]
return self.encoding[:seq_len, :]
# [seq_len = 30, d_model = 512]
# it will add with tok_emb : [128, 30, 512]
class TransformerEmbedding(nn.Module):
"""
token embedding + positional encoding (sinusoid)
positional encoding can give positional information to network
"""
def __init__(self, vocab_size, d_model, max_len, drop_prob, device):
"""
class for word embedding that included positional information
:param vocab_size: size of vocabulary
:param d_model: dimensions of model
"""
super(TransformerEmbedding, self).__init__()
self.tok_emb = TokenEmbedding(vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model, max_len, device)
self.drop_out = nn.Dropout(p=drop_prob)
def forward(self, x):
tok_emb = self.tok_emb(x)
pos_emb = self.pos_emb(x)
return self.drop_out(tok_emb + pos_emb)
MultiHeadAttention

注意点:(batch_size, length, self.n_head, d_tensor) -> (batch_size, self.n_head, length, d_tensor)
- 在多头注意力机制中,每个注意力头都会对输入序列进行独立的注意力计算。在计算过程中,每个注意力头需要对序列中的每个位置进行注意力权重的计算,然后根据这些权重对序列进行加权求和。这意味着每个注意力头需要对序列的维度进行操作。
- 如果直接使用view函数将输入张量的形状转换为(batch_size, self.n_head, length, d_tensor),那么每个注意力头在计算注意力权重时,会将序列的维度(length)与注意力头的维度(self.n_head)混合在一起。这样会导致每个注意力头无法独立地对序列进行注意力计算,而是将注意力头的维度与序列的维度进行混合计算。
- 为了保持每个注意力头的独立性,需要将注意力头的维度(self.n_head)与序列的维度(length)分开。通过先使用view函数将输入张量的形状转换为(batch_size, length, self.n_head, d_tensor),再使用transpose函数交换维度1和维度2的位置,可以保持每个注意力头的独立性,并且保持了正确的维度顺序,使得后续的多头注意力计算能够顺利进行。
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head):
super(MultiHeadAttention, self).__init__()
self.n_head = n_head
self.attention = ScaleDotProductAttention()
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_concat = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
# 1. dot product with weight matrices
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v)
# 2. split tensor by number of heads
q, k, v = self.split(q), self.split(k), self.split(v)
# 3. do scale dot product to compute similarity
out, attention = self.attention(q, k, v, mask=mask)
# 4. concat and pass to linear layer
out = self.concat(out)
out = self.w_concat(out)
# 5. visualize attention map
# TODO : we should implement visualization
return out
def split(self, tensor):
"""
split tensor by number of head
:param tensor: [batch_size, length, d_model]
:return: [batch_size, head, length, d_tensor]
"""
batch_size, length, d_model = tensor.size()
d_tensor = d_model // self.n_head
tensor = tensor.view(batch_size, length, self.n_head, d_tensor).transpose(1, 2)
# it is similar with group convolution (split by number of heads)
return tensor
def concat(self, tensor):
"""
inverse function of self.split(tensor : torch.Tensor)
:param tensor: [batch_size, head, length, d_tensor]
:return: [batch_size, length, d_model]
"""
batch_size, head, length, d_tensor = tensor.size()
d_model = head * d_tensor
tensor = tensor.transpose(1, 2).contiguous().view(batch_size, length, d_model)
return tensor
ScaleDotProductAttention

class ScaleDotProductAttention(nn.Module):
"""
compute scale dot product attention
Query : given sentence that we focused on (decoder)
Key : every sentence to check relationship with Qeury(encoder)
Value : every sentence same with Key (encoder)
"""
def __init__(self):
super(ScaleDotProductAttention, self).__init__()
self.softmax = nn.Softmax(dim=-1)
def forward(self, q, k, v, mask=None, e=1e-12):
# input is 4 dimension tensor
# [batch_size, head, length, d_tensor]
batch_size, head, length, d_tensor = k.size()
# 1. dot product Query with Key^T to compute similarity
k_t = k.transpose(2, 3) # transpose
score = (q @ k_t) / math.sqrt(d_tensor) # scaled dot product
# 2. apply masking (opt)
if mask is not None:
score = score.masked_fill(mask == 0, -10000)
# 3. pass them softmax to make [0, 1] range
score = self.softmax(score)
# 4. multiply with Value
v = score @ v
return v, score

LayerNorm
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-12):
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
var = x.var(-1, unbiased=False, keepdim=True)
# '-1' means last dimension.
out = (x - mean) / torch.sqrt(var + self.eps)
out = self.gamma * out + self.beta
return out
FFN

class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, hidden, drop_prob=0.1):
super(PositionwiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, hidden)
self.linear2 = nn.Linear(hidden, d_model)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=drop_prob)
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.linear2(x)
return x
Encoder

class EncoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm1 = LayerNorm(d_model=d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
def forward(self, x, src_mask):
# 1. compute self attention
_x = x
x = self.attention(q=x, k=x, v=x, mask=src_mask)
# 2. add and norm
x = self.dropout1(x)
x = self.norm1(x + _x)
# 3. positionwise feed forward network
_x = x
x = self.ffn(x)
# 4. add and norm
x = self.dropout2(x)
x = self.norm2(x + _x)
return x
class Encoder(nn.Module):
def __init__(self, enc_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
max_len=max_len,
vocab_size=enc_voc_size,
drop_prob=drop_prob,
device=device)
self.layers = nn.ModuleList([EncoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
def forward(self, x, src_mask):
x = self.emb(x)
for layer in self.layers:
x = layer(x, src_mask)
return x
Decoder
class DecoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(DecoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm1 = LayerNorm(d_model=d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.enc_dec_attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm3 = LayerNorm(d_model=d_model)
self.dropout3 = nn.Dropout(p=drop_prob)
def forward(self, dec, enc, trg_mask, src_mask):
# 1. compute self attention
_x = dec
x = self.self_attention(q=dec, k=dec, v=dec, mask=trg_mask)
# 2. add and norm
x = self.dropout1(x)
x = self.norm1(x + _x)
if enc is not None:
# 3. compute encoder - decoder attention
_x = x
x = self.enc_dec_attention(q=x, k=enc, v=enc, mask=src_mask)
# 4. add and norm
x = self.dropout2(x)
x = self.norm2(x + _x)
# 5. positionwise feed forward network
_x = x
x = self.ffn(x)
# 6. add and norm
x = self.dropout3(x)
x = self.norm3(x + _x)
return x
class Decoder(nn.Module):
def __init__(self, dec_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
drop_prob=drop_prob,
max_len=max_len,
vocab_size=dec_voc_size,
device=device)
self.layers = nn.ModuleList([DecoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
self.linear = nn.Linear(d_model, dec_voc_size)
def forward(self, trg, src, trg_mask, src_mask):
trg = self.emb(trg)
for layer in self.layers:
trg = layer(trg, src, trg_mask, src_mask)
# pass to LM head
output = self.linear(trg)
return output
Train
import math
import time
from torch import nn, optim
from torch.optim import Adam
from data import *
from models.model.transformer import Transformer
from util.bleu import idx_to_word, get_bleu
from util.epoch_timer import epoch_time
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
def initialize_weights(m):
if hasattr(m, 'weight') and m.weight.dim() > 1:
nn.init.kaiming_uniform(m.weight.data)
model = Transformer(src_pad_idx=src_pad_idx,
trg_pad_idx=trg_pad_idx,
trg_sos_idx=trg_sos_idx,
d_model=d_model,
enc_voc_size=enc_voc_size,
dec_voc_size=dec_voc_size,
max_len=max_len,
ffn_hidden=ffn_hidden,
n_head=n_heads,
n_layers=n_layers,
drop_prob=drop_prob,
device=device).to(device)
print(f'The model has {count_parameters(model):,} trainable parameters')
model.apply(initialize_weights)
optimizer = Adam(params=model.parameters(),
lr=init_lr,
weight_decay=weight_decay,
eps=adam_eps)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
verbose=True,
factor=factor,
patience=patience)
criterion = nn.CrossEntropyLoss(ignore_index=src_pad_idx)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg[:, :-1])
output_reshape = output.contiguous().view(-1, output.shape[-1])
trg = trg[:, 1:].contiguous().view(-1)
loss = criterion(output_reshape, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
print('step :', round((i / len(iterator)) * 100, 2), '% , loss :', loss.item())
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
batch_bleu = []
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg[:, :-1])
output_reshape = output.contiguous().view(-1, output.shape[-1])
trg = trg[:, 1:].contiguous().view(-1)
loss = criterion(output_reshape, trg)
epoch_loss += loss.item()
total_bleu = []
for j in range(batch_size):
try:
trg_words = idx_to_word(batch.trg[j], loader.target.vocab)
output_words = output[j].max(dim=1)[1]
output_words = idx_to_word(output_words, loader.target.vocab)
bleu = get_bleu(hypotheses=output_words.split(), reference=trg_words.split())
total_bleu.append(bleu)
except:
pass
total_bleu = sum(total_bleu) / len(total_bleu)
batch_bleu.append(total_bleu)
batch_bleu = sum(batch_bleu) / len(batch_bleu)
return epoch_loss / len(iterator), batch_bleu
def run(total_epoch, best_loss):
train_losses, test_losses, bleus = [], [], []
for step in range(total_epoch):
start_time = time.time()
train_loss = train(model, train_iter, optimizer, criterion, clip)
valid_loss, bleu = evaluate(model, valid_iter, criterion)
end_time = time.time()
if step > warmup:
scheduler.step(valid_loss)
train_losses.append(train_loss)
test_losses.append(valid_loss)
bleus.append(bleu)
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_loss:
best_loss = valid_loss
torch.save(model.state_dict(), 'saved/model-{0}.pt'.format(valid_loss))
f = open('result/train_loss.txt', 'w')
f.write(str(train_losses))
f.close()
f = open('result/bleu.txt', 'w')
f.write(str(bleus))
f.close()
f = open('result/test_loss.txt', 'w')
f.write(str(test_losses))
f.close()
print(f'Epoch: {step + 1} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\tVal Loss: {valid_loss:.3f} | Val PPL: {math.exp(valid_loss):7.3f}')
print(f'\tBLEU Score: {bleu:.3f}')
if __name__ == '__main__':
run(total_epoch=epoch, best_loss=inf)
Transformer 变体
ViT & Swin Transformer


- ViT 与 NLP的不同


- 4 stage的切分,这是在干嘛呢?
- 感受野在不断的扩大,局部到全局,使Transfomer有层级结构


- 感受野在不断的扩大,局部到全局,使Transfomer有层级结构
Shifted Window
 文章来源:https://www.toymoban.com/news/detail-468609.html
文章来源:https://www.toymoban.com/news/detail-468609.html
- 旋转取代滑动
 文章来源地址https://www.toymoban.com/news/detail-468609.html
文章来源地址https://www.toymoban.com/news/detail-468609.html
- shift + mask 取代 padding + mask




到了这里,关于注意力&Transformer的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!