论文:2304.Segment Anything
代码: https://github.com/facebookresearch/segment-anything
官网与demo:https://segment-anything.com/
【扩展阅读】——分割一切模型(SAM)的全面调研:2305.A Comprehensive Survey on Segment Anything Model for Vision and Beyond
【应用】在stable-diffusion-webui中使用的插件:https://github.com/continue-revolution/sd-webui-segment-anything
概要:SAM是什么?
SAM(Segment Anything Model)是通用的分割模型
可以通过 点选择、文字输入、标注框对图片进行标注
图1 项目内容(发布模型、数据集):
图1:我们的目标是通过引入三个相互连接的组件来构建一个用于分割的基础模型:一个可提示(promptable)的分割任务,一个分割模型(SAM)用于数据标注( powers data annotation),并通过提示工程实现对各种任务的零样本转移,以及一个数据引擎用于收集SA-1B,我们超过10亿个掩码的数据集
模型概述 (SAM overview)
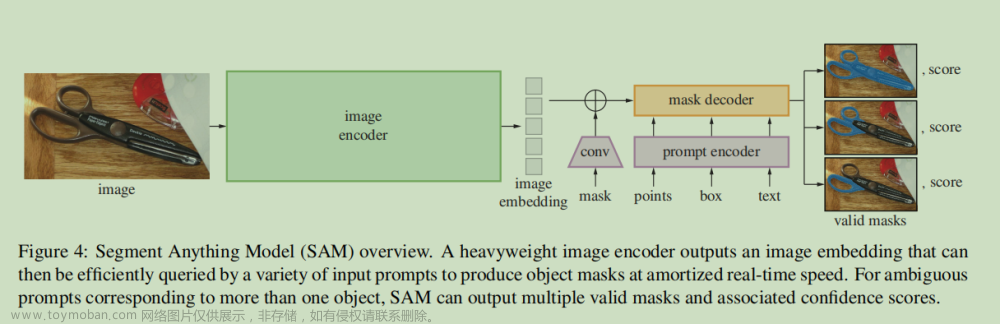
一个重量级的(heavyweight)图像编码器输出一个图像的特征编码,可以通过各种输入提示(a variety of input prompts)高效地查询,以实现分割目标掩码,并以摊销的实时速度进行处理。对于与多个对象对应的模糊提示,SAM可以输出多个有效的掩码,并附带置信度得分。
备注
(·
图像嵌入 image embedding是指将图像转换为固定长度高纬向量表示的过程。它是通过将图像输入到深度神经网络中的图像编码器(image
encoder)来实现的。图像编码器是一个经过训练的模型,它可以将图像转换为高维向量,其中每个维度代表图像的某种特征或语义信息。通过将图像转换为向量表示,我们可以使用向量空间中的距离度量来衡量图像之间的相似性或差异。这种向量表示还可以作为输入用于其他任务,例如图像分类、图像检索和图像生成等。)
部分效果图
一个模糊点提示的多结果输出
每一列显示由SAM从一个模糊点提示( ambiguous point prompt)(绿色圆圈)生成的3个有效掩码
在各种数据集的zero-shot 推理能力
“zero-shot”(零样本)通常指的是在没有接受特定任务训练的情况下,模型可以对该任务进行预测或处理的能力
零样本的边缘检测能力
Zero-shot edge prediction
基于文字提示的分割 ( Zero-shot text-to-mask)
SAM可以使用简单而微妙的文本提示(text prompts)。当SAM无法做出正确的预测时,一个额外的点提示(point prompt)可以提供帮助。
SAM潜在空间掩模嵌入相似性的可视化
( Visualization of thresholding the similarities of mask embeddings from SAM’s latent space)
查询由洋红色框(magenta box)表示;顶部行显示低阈值的匹配,下面一行显示高阈值的匹配。在同一图像中最相似的掩码嵌入通常可以在语义上与查询掩码嵌入相似,即使SAM没有通过显式的语义监督进行训练
使用
stable-diffusion-webui的安装与使用
本机启动sd-webui安装
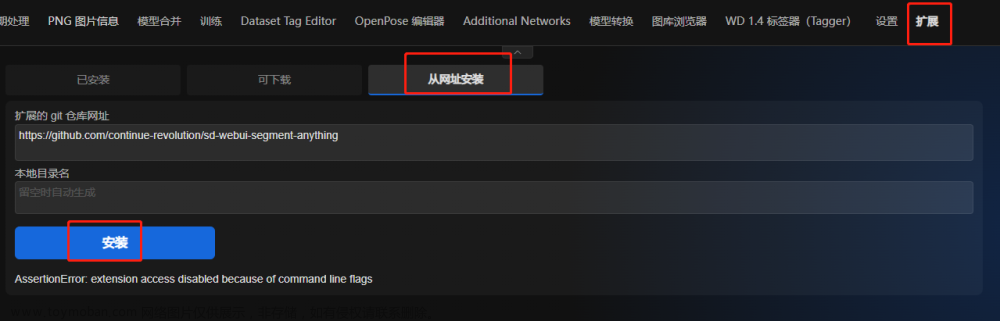
模型下载
分割模型下载后放到这个位置:.???/extension/sd-webui-segment-anything/models/sam下,
可以下载3个不同大小的模型,从大到小如下: vit_h 2.56GB, vit_l is 1.25GB, vit_b 375MB.。如果显存不够的话,可以考虑使用小模型。当然效果也可能会有损失。
经过上述步骤后,插件就安装好了。
服务器上安装环境(参考)
环境
pip install git+https://github.com/facebookresearch/segment-anything.git -i https://mirror.baidu.com/pypi/simple
插件下载
# cd your_path_sd-webui/extensions
git clone https://github.com/continue-revolution/sd-webui-segment-anything.git
同样模型手动下载,放到对应位置 文章来源:https://www.toymoban.com/news/detail-469391.html
文章来源:https://www.toymoban.com/news/detail-469391.html
原文阅读
论文原摘要
我们介绍 Segment Anything(SA)项目:一个用于图像分割的新任务、模型和数据集(dataset)。使用我们的高效模型在数据收集循环中(data collection loop),我们构建了迄今为止最大的分割数据集(by far),其中包含了在1100万张经过授权(licensed)且尊重隐私(privacy respecting)的图像上搜集超过10亿个掩码(masks)。
该模型经过设计和训练,可以根据提示(promptable)进行零样本转移(zero-shot),适用于新的图像分布和任务( to new image distributions and tasks)。我们对其在众多任务上进行评估,并发现它的零样本性能令人印象深刻(impressive),甚至优于以前的全监督方法(prior fully supervised results)相竞争(competitive)。发布了Segment Anything模型(SAM)和相应的·数据集(SA-1B),其中包含10亿个掩码(masks)和1100万张图像,以促进计(foster research)算机视觉基础模型的研究。文章来源地址https://www.toymoban.com/news/detail-469391.html
到了这里,关于【图像分割】SAM:Segment Anything论文学习V1的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!