目录
一、前言
二、使用coco128数据集进行训练
2.1 数据集准备
2.2 进行训练
三、使用自己制作的数据集进行训练和测试
3.1制作自己的数据集
3.2 开始训练
3.3 模型测试
四、让输入图片显示标签数量
一、前言
1.本文的目的在于帮助读者实现yolov5的训练,测试以及使用,偏重应用,将有较少代码讲解
2.本文将首先示范使用coco128数据集进行训练,向读者展示整个模型的使用过程,之后介绍如何制作自己的数据集并进行训练,最后一部分讲解如何让输出图片显示各个标签数量
3.本文使用的数据集coco128放在网盘里了,如果没有这个数据集的话可以去网盘上下载,yolov5的环境配置可以参考站内其他文章。
链接:https://pan.baidu.com/s/1MYSzPkPVUxpE1wt7zUxO0g
提取码:8r4i
二、使用coco128数据集进行训练
2.1 数据集准备
下好的数据集应该是如下图所示
 images文件夹里存放的是我们要训练的图片,labels文件夹里存放的是打过标签的图片
images文件夹里存放的是我们要训练的图片,labels文件夹里存放的是打过标签的图片
目标检测需要手动进行打标签,这个我会在后面介绍使用自己数据集时进行详细介绍
2.2 进行训练
编译器这里我使用的Pycharm,打开项目如下图

这里我们需要知道两个yaml文件
第一个是data文件夹下的coco128.yaml 数据集参数文件

打开这个文件如下图,这个文件里是我们需要更改训练集以及测试集路径的地方,下面的names是每一个标签,可以看到coco128数据集里的标签数量是非常大的,我们平时自己玩的时候一般不会用到这么多标签。

接着我们需要了解的另一个文件是models文件夹下的从yolov5l到yolov5s的训练权重

我们打开yolov5s这个文件,如下图。这里nc是我们的标签数量。

以上两个文件我们目前都不用改,只是了解一下方便我们后面使用自己数据集进行测试时讲解
接着我们打开train.py文件,找到这个位置

--weights 初始训练权重
--cfg 模型参数位置
--data 数据集参数文件
直接开始运行train.py

慢慢等他跑完,最后的结果会存放在

exp到exp10都是你每次训练的结果,我这里训练了10次,所以有10个存放结果的文件夹
打开你最新的结果

weights是训练后模型的权重,随便点开val_batch1_pred.jpg可以看到训练后的效果

三、使用自己制作的数据集进行训练和测试
3.1制作自己的数据集
制作自己的数据集需要用到工具labelimg,直接在命令行输入下面这行代码进行下载
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple然后在yolov5项目的文件夹同级建立一个新的文件夹,文件夹名称可以自取,我这里使用DATA

并在DATA文件夹下创建如下两个文件夹和一个predefined_classes.txt文件

predefined_classes.txt是用来存放你的标签名称,我这里打三个标签分别是hair,eye,hands

接着,将你想要训练的图片放到images文件夹下(数据集100张以上才有一定效果,我这里拿105张动漫图片作演示)

命令行转到DATA文件夹

输入以下指令打开labelimg
labelimg images predefined_classes.txt打开效果如下(右下角是文件列表,之前截图时候只放了三张所以列表里只有三张,训练时候有105张)

点击Change Save Dir选择DATA下的labels文件夹
点击SAVE下的yolo将其切换成yolo(如果刚开始不是yolo就切换成yolo,是的话就不用动)
点击Create RectBox开始画框(打标签)

你会看到下面已经有了几个你之前保存的标签

打完一张图片的标签可以按“D”键自动保存并进入下一张

我们可以在labels文件夹里看到自动生成的文件,上面三个是以图片名字命名的用来存放你在该图片中画框坐标位置的文件,最后一个classes是存放标签的文件。
3.2 开始训练
数据集准备好了,现在我们到之前提到的项目文件中
data/coco128.yaml,复制一个这个文件并改名成你自己喜欢的我这里起名any.yaml

打开这个文件,修改path,train和val后的地址,path就是DATA文件地址,train是DATA文件下的images地址,val是测试集,由于我这里数据量较小我就都用images了,读者可以自行添加测试集,方法是在images和labels文件夹下分别创建train和test文件夹分别放入图片

接着来到我们之前提到的models文件夹下的yolov5s.yaml文件

复制该文件,并命名为5s_any.yaml,并打开,将nc修改为3(因为有三个标签)

最后打开train.py,修改如下地址

只需要改上图三行的地址就可以了,点击运行开始训练
等待训练结束后在runs/train文件夹中可以看到结果,下图是训练效果

3.3 模型测试
首先在DATA文件夹下创建test文件夹,在其中放入你想要测试的图片

我们来到项目文件里的detect.py文件,打开,找到如图所示位置

改--weights后面的地址为runs/train/exp10/weights/last.pt
这里exp10是我第十次训练结果,读者根据自己训练的文件夹名改写,我们打开这个weights文件夹
发现有如下两个文件

best.pt和last.pt这些都是你训练好的模型权重,你可以理解为这就是你训练好的模型
best.pt是看起来最好的一次,last.pt是最后一次,虽然best是看起来最好的一次但是可能泛化能力不强,所以我这里选择last
我们回到detect.py中继续修改地址

这里--source后的地址要改成你在DATA文件夹下的test文件地址
--data后的地址改成data/any.yaml
点击运行开始detect
结果存放在runs/detect/exp中,可以到这个文件夹查看
四、让输入图片显示标签数量
该部分参考YOLOv5_6.1检测界面显示计数结果-CSDN博客
在detect.py文件中修改如下代码
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
Results = "Results: "
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += '\n'+f"{n} {names[int(c)]}{'s' * (n > 1)}" # add to string
Results += '\n'+f"{n} {names[int(c)]}" # TODO 加了一个变量Results
#s += f"{n} {names[int(c)]}{'s' * (n > 1)}, +" # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # TODO # Add bbox to image
c = int(cls) # integer class分类数
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f} {(det[:, -1] == c).sum()}') # TODO 标签计数展示加在了末尾
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
# Stream results
im0 = annotator.result()
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
# 需用循环的方式显示多行,因为cv2.putText对换行转义符'\n'显示为'?'
y0, dy = 50, 40
for i, txt in enumerate(Results.split('\n')):
y = y0 + i * dy
cv2.putText(im0, txt, (50, y), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 255, 0), 2, 2)
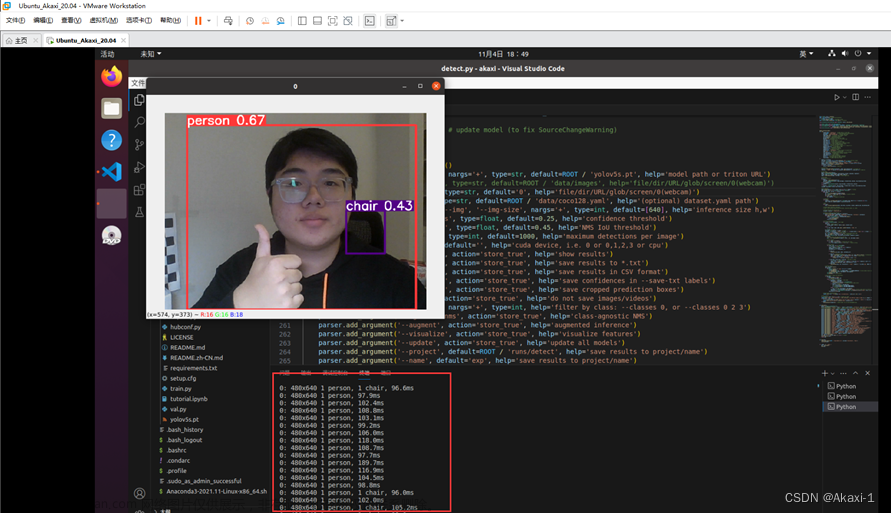
#cv2.putText(im0, Results, (10, 10), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 0, 255), 3) # TODO 左上角显示检测标签和数量运行detect.py即可得到如下效果,绿色的1 hair显示了标签数量 文章来源:https://www.toymoban.com/news/detail-469484.html
 文章来源地址https://www.toymoban.com/news/detail-469484.html
文章来源地址https://www.toymoban.com/news/detail-469484.html
到了这里,关于YOLOV5实战教程(超级详细图文教程)!!!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!