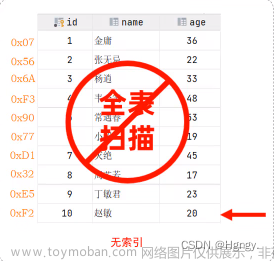
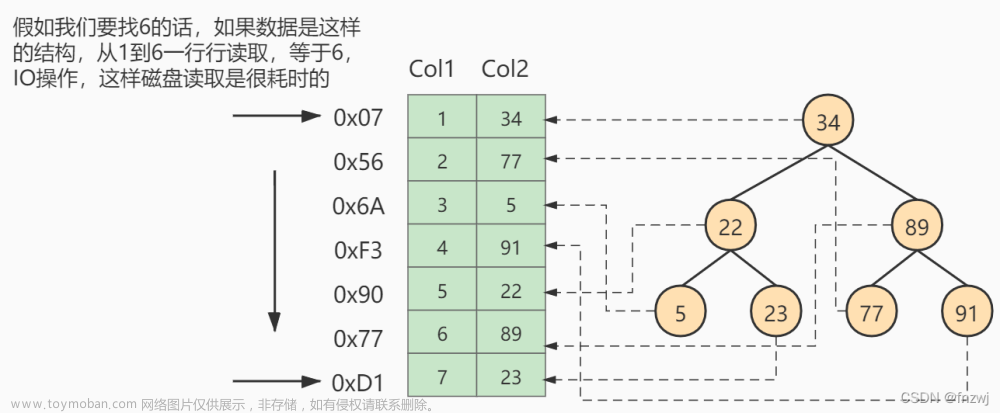
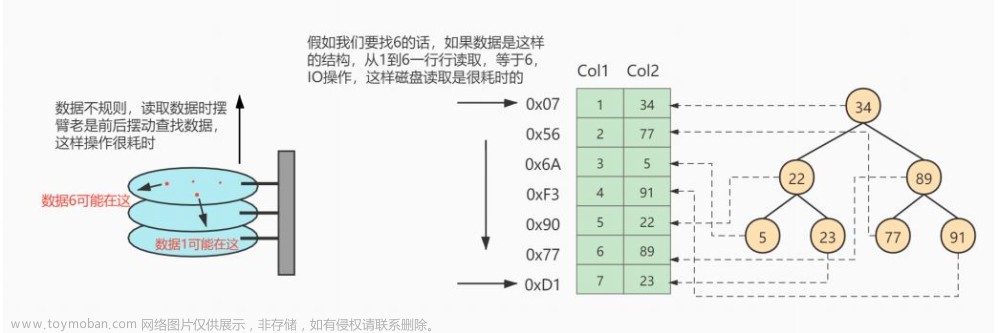
索引常见的有三种数据结构:哈希表,有序数组和二叉树。
MySQL使用了B+树。
下面分别介绍下三种数据结构
1、哈希表(散列表)
- 对索引的key进行一次hash计算就可以定位出数据存储的位置
- 很多时候Hash索引要比B+Tree索引更高效
- 仅能满足“=”,“in”,不支持范围查询
- 存在hash冲突
hash算法原理:hash计算后的数据都会进入到容器Hash桶内,桶内按照下标位置分配好了内存空间,如果通过hash()计算后得到的值为2,将该数据放到次下标对应的区域。如下图

仅通过一次hash计算就可以确定数据的存储位置,如查询李四:
① 通过hash(李四)=2
②把hash桶内的下标为2的数据load到内存,进行比较
hash仅使用了一次I/O就能拿到数据,B+Tree可能会有多次,所以一些场景hash索引会比B+Tree更高效。但是这种结构对范围查询不友好,所以MySQL底层基本用的是B+Tree。
2、有序数组
有序数组在范围查找中可以使用二分法,能大大缩短查询时间,时间复杂度是O(log(N))。如果在中间插入数据时,需要移动后续数组,成本很高,所以有序数组索引只适用于静态存储引擎。
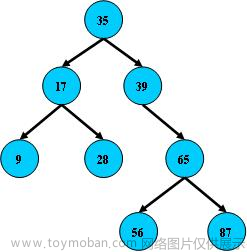
3、二叉树
二叉树:右侧元素大于父元素数据,左侧数据小于父元素数据
红黑树(平衡二叉树):与二叉树结构一样,但是在生成的过程中红黑树会自动平衡节点
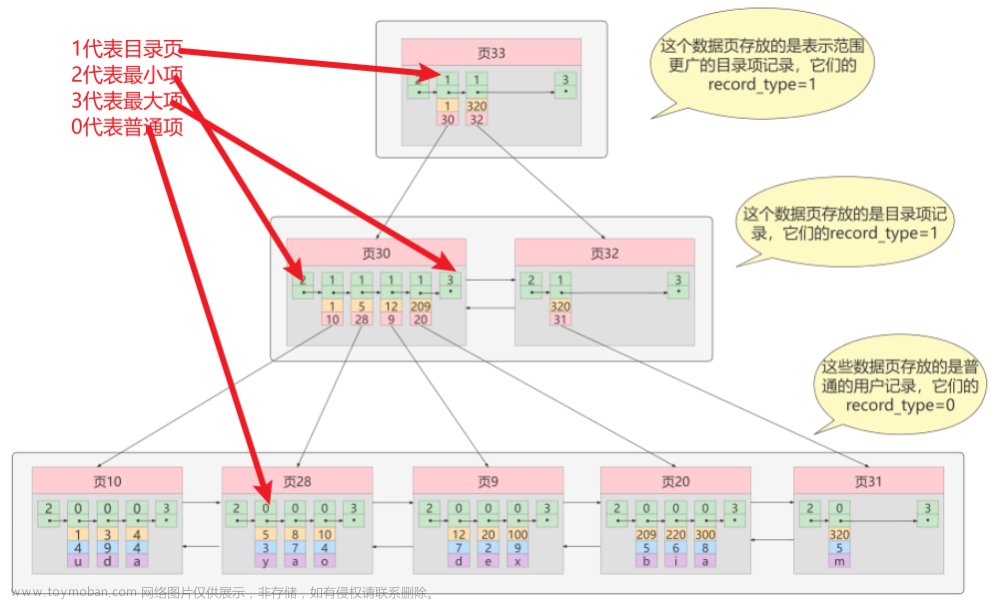
b-Tree:
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
- 节点中存储data数据

当索引结构以B-Tree数据结构创建时,查找Clo2 = 66 的数据:
1.将树的第一层所有数据load到内存,使用比对算法(如:二分查找)进行比对
a.如果有66则将对应的data数据从内存中读取出来
b.如果没有,则会找66对应的区间地址(35-80)
2.将35-80这一页的所有数据再拿出来与66做比较
a.如果有66则将对应的data数据从内存中读取出来
b.如果没有,则会找66对应的区间地址
以此类推,直到找到66或者这一系列的数据比对完毕。
使用了B-Tree数据结构后,我们查询Clo2=66的数据只做了两次的I/O,比红黑树的效率更高一些。
b+Tree:
- 非叶子节点不存储data,只存储索引,目的是可以放更多的索引。
- 叶子节点包含所有索引字段
- 叶子节点使用指针连接,提高区间访问的性能

面试相关问题:
问题1:为什么非叶子节点不存储data,可以放更多的索引?
通过 SHOW GLOBAL STATUS like 'Innodb_page_size';可以看到Mysql数据库中定义文件页大小是16384B(16KB)。
如果叶子节点不存储data,假设字段类型是BigInt,字段值占用8B,地址值占用6B,一层16KB大概可以存储1170个索引值。
如果叶子节点存储data,一般的data+字段值+地址值不会大于1KB,我们就按照平均1KB计算,一层16KB也就只能存储16个索引值
问题2:为什么MYSQL叶文件默认是16KB?
由问题1知道第一层一页数据可以存1170个索引值,如果再加一层,第一层的每一个地址值指向第二层的一页数据,我们就可以存储 1170X1170 个索引值,第二层每个地址值指向第三层的一页数据,第三层的叶子节点要带数据存储每一页只存16个数据,三层高的树可以存储 1170 X 1170 X 16 大约2千万左右的数据。
问题3:叶子节点指针的作用?

B+Tree有链接指针可以快速的找下一页的数据,B-Tree没有指针,当取完当前区域的数据后,还得回到根节点(第一层)查找大于28的数据再做对应的I/O。 所以B+Tree可以通过叶子节点指针提高区间访问的性能。
问题4:MySQL中存储索引用到的数据结构是B+树,B+树的查询时间跟树的高度有关,是log(n),如果用hash存储,那么查询时间是O(1)。既然hash比B+树更快,为什么mysql用B+树来存储索引呢?
1、从内存角度上说,数据库中的索引一般时在磁盘上,数据量大的情况可能无法一次性装入内存,B+树的设计可以允许数据分批加载。
2、从业务场景上说,如果只选择一个数据那确实是hash更快,但是数据库中经常会选中多条这时候由于B+树索引有序,并且又有链表相连,它的查询效率比hash就快很多了。
问题5:数据库索引为什么要用B+树而不是B-树和红黑树呢?
1、B-树和B+树最重要的一个区别就是B+树只有叶节点存放数据,其余节点用来索引,而B-树是每个索引节点都会有Data域。B-树增加了磁盘IO次数(磁盘IO一次读出的数据量大小是固定的,单个数据变大,每次读出的就少,IO次数增多,一次IO多耗时啊!),而B+树除了叶子节点其它节点并不存储数据,节点小,磁盘IO次数就少。B+树所有的Data域在叶子节点,一般来说都会进行一个优化,就是将所有的叶子节点用指针串起来。这样遍历叶子节点就能获得全部数据,这样就能进行区间访问啦。
2、从Mysql(Inoodb)的角度来看,B+树是用来充当索引的,一般来说索引非常大,尤其是关系性数据库这种数据量大的索引能达到亿级别,所以为了减少内存的占用,索引也会被存储在磁盘上。文章来源:https://www.toymoban.com/news/detail-469505.html
问题6:B树相对于红黑树的区别
在大规模数据存储的时候,红黑树往往出现由于树的深度过大而造成磁盘IO读写过于频繁,进而导致效率低下的情况。为什么会出现这样的情况,我们知道要获取磁盘上数据,必须先通过磁盘移动臂移动到数据所在的柱面,然后找到指定盘面,接着旋转盘面找到数据所在的磁道,最后对数据进行读写。磁盘IO代价主要花费在查找所需的柱面上,树的深度过大会造成磁盘IO频繁读写。根据磁盘查找存取的次数往往由树的高度所决定,所以,只要我们通过某种较好的树结构减少树的结构尽量减少树的高度,B树可以有多个子女,从几十到上千,可以降低树的高度。文章来源地址https://www.toymoban.com/news/detail-469505.html
到了这里,关于索引的数据结构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!