01|修改Win用户名
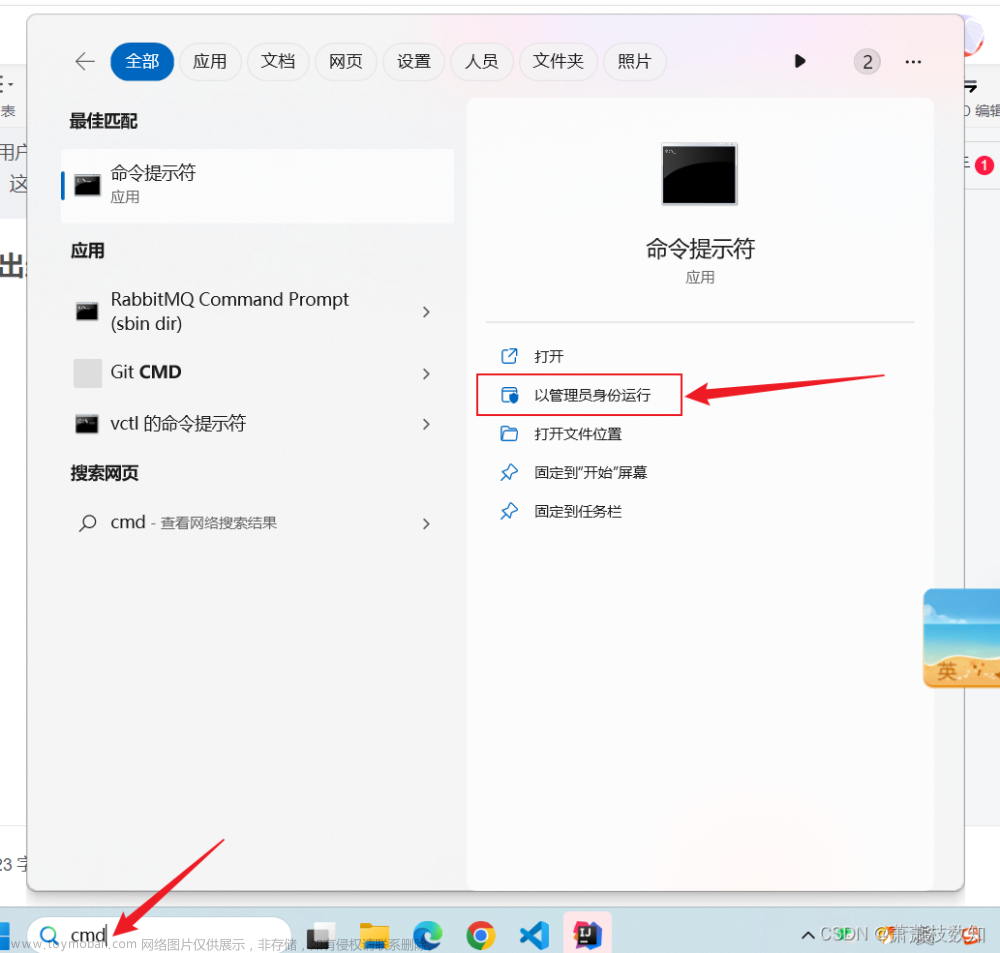
打开运行,输入cmd,回车;
输入control userpasswords2,回车;
点击属性,修改用户名,点击确定;
打开运行,输入regedit,回车;
定位到HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\ProfileList;
选中下面名字最长的项,双击右侧的ProfileImagePath,修改 C:\Users\ 后的用户名,点击确定;
注销并重新登录;
打开 C:\User\,将新的用户名文件夹删除,再将原来的的用户名文件夹重命名为新的用户名;
再次注销并重新登录。
02|修的内核bug如何推进
发patch
-
克隆最新代码,确定问题还存在
-
新建本地分支,修改要修改的部分
git add 修改的文件 git commit -s commit-log 《标题》:修改的大类:简短的patch主要描述 《空行》 《详细描述》 git format-patch -1(可以在三小短线下写点东西) -
使用get-maintainer获取当前文件的维护者,发给子系统(可以使用git自带的send-mail命令)
03|cl(VS ToolChain)编译ffmpeg
lame: ./configure --enable-shared --prefix=/mnt/Mp3/Out/ --host=x86_64-pc-windows CC=cl.exe
ffmpeg: ./configure --prefix=Out --toolchain=msvc --enable-w32threads --enable-x86asm --disable-doc --disable-ffprobe --enable-small --disable-runtime-cpudetect --disable-network --disable-debug
x264: ./configure --enable-static --enable-shared
lame: ./configure --prefix=/usr/local --enable-static --enable-shared
ffmpeg: ./configure --prefix=Out --enable-x86asm --enable-network --enable-protocol=https --enable-optimizations --enable-gpl --enable-libx264 --enable-libmp3lame --enable-small --enable-static --disable-shared --disable-ffprobe --disable-doc --extra-cflags=/usr/local/include --extra-ldflags=/usr/local/lib
04|WSA on Win10
New-NetFirewallRule -DisplayName "WSL" -Direction Inbound -InterfaceAlias "vEthernet (WSL)" -Action Allow
https://github.com/cinit/WSAPatch/
05|Docker Commands on Win
www.docker.com
learn.microsoft.com/en-us/windows/wsl/wsl-config#configuration-setting-for-wslconfig
learn.microsoft.com/zh-cn/windows/wsl/wsl-config#configuration-setting-for-wslconfig
mklink /j "C:\Program Files\Docker" "K:\Vmachine\Docker"
wsl --export dis_name dest
wsl --unregister dis_name
wsl --import dis_dest dis_export --version 2
06|CheatEngine PVZ 0cd
[ENABLE]
//code from here to '[DISABLE]' will be used to enable the cheat
alloc(newmem,2048)
label(returnhere)
label(originalcode)
label(exit)
newmem: //this is allocated memory, you have read,write,execute access
//place your code here
originalcode:
add dword ptr [edi+24],10000
mov eax,[edi+24]
exit:
jmp returnhere
"PVZ原版启动程序.exe"+8728C:
jmp newmem
nop 2
returnhere:
[DISABLE]
//code from here till the end of the code will be used to disable the cheat
dealloc(newmem)
"PVZ原版启动程序.exe"+8728C:
add dword ptr [edi+24],01
mov eax,[edi+24]
//Alt: db 83 47 24 01 8B 47 24
<?xml version="1.0" encoding="utf-8"?>
<CheatTable CheatEngineTableVersion="38">
<CheatEntries>
<CheatEntry>
<ID>0</ID>
<Description>"No description"</Description>
<LastState Value="0" RealAddress="1566453C"/>
<VariableType>4 Bytes</VariableType>
<Address>1566453C</Address>
</CheatEntry>
<CheatEntry>
<ID>1</ID>
<Description>"0cd script"</Description>
<LastState Activated="1"/>
<VariableType>Auto Assembler Script</VariableType>
<AssemblerScript>[ENABLE]
//code from here to '[DISABLE]' will be used to enable the cheat
alloc(newmem,2048)
label(returnhere)
label(originalcode)
label(exit)
newmem: //this is allocated memory, you have read,write,execute access
//place your code here
originalcode:
add dword ptr [edi+24],10000
mov eax,[edi+24]
exit:
jmp returnhere
"PVZ原版启动程序.exe"+8728C:
jmp newmem
nop 2
returnhere:
[DISABLE]
//code from here till the end of the code will be used to disable the cheat
dealloc(newmem)
"PVZ原版启动程序.exe"+8728C:
add dword ptr [edi+24],01
mov eax,[edi+24]
//Alt: db 83 47 24 01 8B 47 24
</AssemblerScript>
</CheatEntry>
</CheatEntries>
<UserdefinedSymbols/>
</CheatTable>
07|CCL反软件查杀
multiCCL定位原理图示
by niu-cow in NE365
2996-04-22
1.假设一种比较极端的情况:
某杀毒软件针对某样本
抽取了如下 a b c d e 的五个特征码片段
而其中的任何一个单独的片段都不构成完整的特征码
更极端的情况是可能有两套这样的组合。
却以其中任何两处来识别。(见 图1)
这样,如果用原来的CCL就很难定位了,就算能定位,操作也
变得很复杂。
(图1)
..............................aaaaaaaaa........................
...............................................................
.............bbbbbbb.........ccc...............................
...............................................................
...................ddddddddd...............eeeee...............
2.针对这种情况
有个思路是从一端开始盖零(考虑到PE文件文件头的重要性
multiCCL选择了从尾端开始往前盖)。
直到如图2所示时,杀毒软件才不能识别
(b片段被破坏了一个字节)
这样b尾端就出来了。
(图2)
..............................aaaaaaaaa.........................
................................................................
.............bbbbbb000000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
------------------------------------------------------------------
下面是定b片段的头端了
看看图3 图4 图5 ,注意看b片段中间那个字节的零的移动
(图3)
..............................aaaaaaaaa.........................
................................................................
.............bbbb0bbb0000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
----------------------------------
(图4)
..............................aaaaaaaaa.........................
................................................................
.............0bbbbbb00000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
----------------------------------------------------------------------
(图5)
..............................aaaaaaaaa.........................
................................................................
............0bbbbbbb00000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
--------------上图的a 和 b 两个片段都暴露了--------------------------
图5 中,暴露出完整的a b 两个片段,这下又被杀毒软件认出来了
这样就定位出b段了。
接下来把b希用0盖掉作为新的样本,用杀毒软件检测一下是否被杀,还杀就
重复前面的步骤定 c 段,如图6
(图6)
..............................aaaaaaaaa........................
...............................................................
.............0000000.........ccc...............................
...............................................................
...................ddddddddd...............eeeee...............
-----------------------------------------------------------------------
如果定好c段盖掉后还是被杀就再定 d 段
如图7
(图7)
..............................aaaaaaaaa........................
...............................................................
.............0000000.........000...............................
...............................................................
...................ddddddddd...............eeeee...............
-----------------------------------------------------------------------
这样重复,直到片段d e ……都被找出盖掉后,杀毒软件再也不认了
-----------------------------------
一个字节一个字节来显然太费时间,效率很低的,一次性
生成上千个文件也是不现实的。
所以考虑先用二分法粗定。到范围小时再逐字节替换。
-----------------------------------
从尾端开始数,以1.2.4.6.8……的大小往前盖
即取2的指数阶 , 2^n < 文件尺寸就行了。
一次生成20个左右的样本文件,用杀毒软件检测
以例图说明吧(见 图8图9)
下面这个盖了128 bytes 的还被识别
(图8)
..............................aaaaaaaaa........................
...............................................................
.............bbbbbbb.........ccc...............................
000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000
-----------上面这个盖了128 bytes的还被识别-------------
--------------下面这个盖了256 bytes 的不被识别了--------------------
(图9)
..............................aaaaaaaaa........................
000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000
--------------------------------------------------------------------
那就说明距文件末尾256--128之间有个特征码片段,
下一步就以图8为样本,
定位的范围是 图10 中经XXXX标记的区域
(图10)
..............................aaaaaaaaa........................
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000
---------------------------------
如此反复,当范围缩小到32字节或更小,二分法就显得效率低下了,
改用逐字节替换法,一次生成最多32个文件。
-----------
另外,
图8 图9 图10 之外,还有一种情况,
就是某次用二分法生成的所有文件
杀毒软件都不识别,那就说明特征码集中在最大盖0范围之前
即图9中 未盖0的区域,这时只要以图9为样本,
定位图11中以YYYY标记的区域
(图11)
YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000
------------
尾端定出后,再用 图3图4图5 所示的方法把0还字节前移,一次生成32个
文件用杀毒软件检测,如果32个全不被杀时,就取这32个字节作为定位结果
对于这种大尺寸的片段,没必要完全定位出片段的头端。
(因为一个片段中只要修改一个字节就够了)
----------------------------------
==================================
----------------------------------
基本原理就如上面所述,其实就什么简单。
不管杀毒软件用几套组合,用复合还是单一特征码,都照样搞定它。
当然,以后杀毒软件使出什么新招就说不准。~~~~~~~~~~~~~~~~~
(本文仅作思路上的探讨,若有人因应用本文的思路带来某些后果,均与
本文作者无关。)
若有不当之处,请各位指正,谢谢
----------------------------------------------------------
补充说明:
2006-04-24 :
刚刚发现有的杀毒软件开始用检测文件的某几处是否被填充0来反定位了,
一旦被检测到某几处被盖0 ,就把位置更先前的干扰码激活。这时就算
牺牲效率一直往前盖,也只能定位出干扰码(假的特征码)。
现在暂时可用随机数据串填充应付,不知道以后还会有什么招。
另外,NDD32的特征码用的是代码与输入表关联,对付这种特征码的方法是,
先普通定位,然后把找到的输入表上的特征码片段保护起来再定位,
这样就能找到代码里的特征码片段了。
2005-05-22 :
通过实际测试发现等分法比二分法效率更高,于是又改用等分法了。
08|pnpm的存储配置
nodejs的包管理器很多,自带的npm,增加镜像支持的cnpm、企业推荐的yarn、性能推荐的pnpm等等,总结这些包管理器特点,我更推荐pnpm。
- npm:官方+自带,但使用不方便,界面和报错不友好。
- cnpm:一行命令能解决非要再下载个服务器?
- yarn:听说企业级用的多,小巧稳定。但上述三个都会摊平导致幽灵引用,个人项目不常见。
- pnpm:使用软硬链接,不摊平就解决幽灵引用,IO性能也上去了,同时全局存储没有多余的磁盘占用。
在用户文件夹创建.npmrc文件,写入下列配置内容,注意更换,Linux通用。文章来源:https://www.toymoban.com/news/detail-469978.html
registry=http://registry.npmmirror.com/ #阿里npm镜像的新Url
prefix=npm包通过npm i -g安装时候脚本存放位置,因此需要加入环境变量path
cache=npm包本体的存放位置
pnpm-prefix=pnpm的主目录,下述目录都应是这个目录的子目录
global-dir=全局安装时包的存储位置
global-bin-dir=全局安装时脚本的存放位置
cache-dir=缓存位置,存放一些镜像的元信息,类似apt使用apt update时更新的东西
state-dir=pnpm本体的更新状态
store-dir=非全局包的存储位置,其它地方安装时npm包的链接目标
如何清理:可以直接删除,pnpm8自带了 pnpm store prune命令,是用来清除非全局包即store-dir的。文章来源地址https://www.toymoban.com/news/detail-469978.html
到了这里,关于[Kyana]Windows使用小技巧的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!