关注开发内功修炼,掌握硬核技术原理
大家好,我是飞哥!
在进行CPU性能优化的时候,我们经常先需要分析出来我们的应用程序中的CPU资源在哪些函数中使用的比较多,这样才能高效地优化。一个非常好的分析工具就是《性能之巅》作者 Brendan Gregg 发明的火焰图。

我们今天就来介绍下火焰图的使用方法,以及它的工作原理。
一、火焰图的使用
为了更好地展示火焰图的原理,我专门写了一小段代码,
int main() {
for (i = 0; i < 100; i++) {
if (i < 10) {
funcA();
} else if (i < 16) {
funcB();
} else {
funcC();
}
}
}完整的源码我放到了咱们开发内功修炼的Github上了:https://github.com/yanfeizhang/coder-kung-fu/blob/main/tests/cpu/test09/main.c。
接下来我们用这个代码实际体验一下火焰图是如何生成的。在本节中,我们只讲如何使用,原理后面的小节再展开。
# gcc -o main main.c
# perf record -g ./main这个时候,在你执行命令的当前目录下生成了一个perf.data文件。接下来咱们需要把Brendan Gregg的生成火焰图的项目下载下来。我们需要这个项目里的两个perl脚本。
# git clone https://github.com/brendangregg/FlameGraph.git接下来我们使用 perf script 解析这个输出文件,并把输出结果传入到 FlameGraph/stackcollapse-perf.pl 脚本中来进一步解析,最后交由 FlameGraph/flamegraph.pl 来生成svg 格式的火焰图。具体命令可以一行来完成。
# perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > out.svg这样,一副火焰图就生成好了。

之所以选择我提供一个 demo 代码来生成,是因为这个足够简单和清晰,方便大家理解。在上面这个火焰图中,可以看出 main 函数调用了 funcA、funcB、funcC,其中 funcA 又调用了 funcD、funcE,然后这些函数的开销又都不是自己花掉的,而是因为自己调用的一个 CPU 密集型的函数 caculate。整个系统的调用栈的耗时统计就十分清晰的展现在眼前了。
如果要对这个项目进行性能优化。在上方的火焰图中看虽然funcA、funcB、funcC、funcD、funcE这几个函数的耗时都挺长,但它们的耗时并不是自己用掉的。而且都花在执行子函数里了。我们真正应该关注的是火焰图最上方 caculate 这种又长又平的函数。因为它才是真正花掉 CPU 时间的代码。其它项目中也一样,拿到火焰图后,从最上方开始,把耗时比较长的函数找出来,优化掉。
另外就是在实际的项目中,可能函数会非常的多,并不像上面这么简单,很多函数名可能都被折叠起来了。这个也好办,svg 格式的图片是支持交互的,你可以点击其中的某个函数,然后就可以展开了只详细地看这个函数以及其子函数的火焰图了。
怎么样,火焰图使用起来是不是还挺简单的。接下来的小节中我们再来讲讲火焰图生成全过程的内部原理。理解了这个,你才能讲火焰图用的得心应手。
二、perf采样
2.1 perf 介绍
在生成火焰图的第一步中,就是需要对你要观察的进程或服务器进行采样。采样可用的工具有好几个,我们这里用的是 perf record。
# perf record -g ./main上面的命令中 -g 指的是采样的时候要记录调用栈的信息。./main 是启动 main 程序,并只采样这一个进程。这只是个最简单的用法,其实 perf record 的功能非常的丰富。
它可以指定采集事件。当前系统支持的事件列表可以用过 perf list 来查看。默认情况下采集的是 Hardware event 下的 cycles 这一事件。假如我们想采样 cache-misses 事件,我们可以通过 -e 参数指定。
# perf record -e cache-misses sleep 5 // 指定要采集的事件还可以指定采样的方式。该命令支持两种采样方式,时间频率采样,事件次数发生采样。-F 参数指定的是每秒钟采样多少次。-c参数指定的是每发生多少次采样一次。
# perf record -F 100 sleep 5 // 每一秒钟采样100次
# perf record -c 100 sleep 5 // 每发生100次采样一次还可以指定要记录的CPU核
# perf record -C 0,1 sleep 5 // 指定要记录的CPU号
# perf record -C 0-2 sleep 5 // 指定要记录的CPU范围还可以采集内核的调用栈
# perf record -a -g ./main在使用 perf record 执行后,会将采样到的数据都生成到 perf.data 文件中。在上面的实验中,虽然我们只采集了几秒,但是生成的文件还挺大的,有 800 多 KB。我们通过 perf script 命令可以解析查看一下该文件的内容。大概有 5 万多行。其中的内容就是采样 cycles 事件时的调用栈信息。
......
59848 main 412201 389052.225443: 676233 cycles:u:
59849 55651b8b5132 caculate+0xd (/data00/home/zhangyanfei.allen/work_test/test07/main)
59850 55651b8b5194 funcC+0xe (/data00/home/zhangyanfei.allen/work_test/test07/main)
59851 55651b8b51d6 main+0x3f (/data00/home/zhangyanfei.allen/work_test/test07/main)
59852 7f8987d6709b __libc_start_main+0xeb (/usr/lib/x86_64-linux-gnu/libc-2.28.so)
59853 41fd89415541f689 [unknown] ([unknown])
......除了 perf script 外,还可以使用 perf report 来查看和渲染结果。
# perf report -n --stdio
2.2 内核工作过程
我们来简单看一下内核是如何工作的。
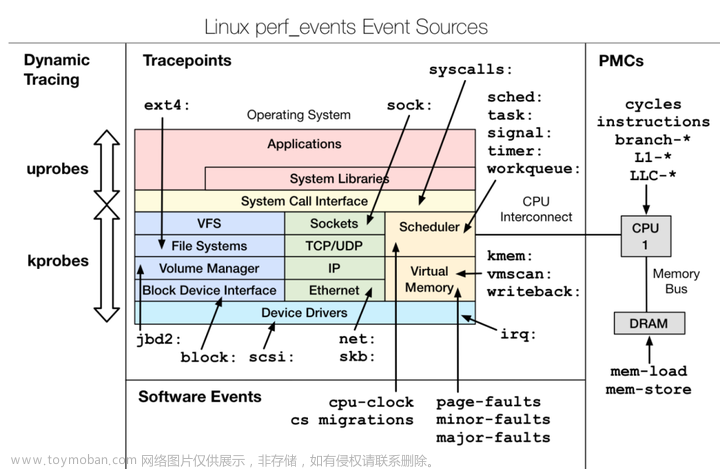
perf在采样的过程大概分为两步,一是调用 perf_event_open 来打开一个 event 文件,而是调用 read、mmap等系统调用读取内核采样回来的数据。整体的工作流程图大概如下

其中 perf_event_open 完成了非常重要的几项工作。
创建各种event内核对象
创建各种event文件句柄
指定采样处理回调
我们来看下它的几个关键执行过程。在 perf_event_open 调用的 perf_event_alloc 指定了采样处理回调函数为,比如perf_event_output_backward、perf_event_output_forward等
static struct perf_event *
perf_event_alloc(struct perf_event_attr *attr, ...)
{
...
if (overflow_handler) {
event->overflow_handler = overflow_handler;
event->overflow_handler_context = context;
} else if (is_write_backward(event)){
event->overflow_handler = perf_event_output_backward;
event->overflow_handler_context = NULL;
} else {
event->overflow_handler = perf_event_output_forward;
event->overflow_handler_context = NULL;
}
...
}当 perf_event_open 创建事件对象,并打开后,硬件上发生的事件就可以出发执行了。内核注册相应的硬件中断处理函数是 perf_event_nmi_handler。
//file:arch/x86/events/core.c
register_nmi_handler(NMI_LOCAL, perf_event_nmi_handler, 0, "PMI");这样 CPU 硬件会根据 perf_event_open 调用时指定的周期发起中断,调用 perf_event_nmi_handler 通知内核进行采样处理
//file:arch/x86/events/core.c
static int perf_event_nmi_handler(unsigned int cmd, struct pt_regs *regs)
{
ret = x86_pmu.handle_irq(regs);
...
}该终端处理函数的函数调用链经过 x86_pmu_handle_irq 到达 perf_event_overflow。其中 perf_event_overflow 是一个关键的采样函数。无论是硬件事件采样,还是软件事件采样都会调用到它。它会调用 perf_event_open 时注册的 overflow_handler。我们假设 overflow_handler 为 perf_event_output_forward
void
perf_event_output_forward(struct perf_event *event, ...)
{
__perf_event_output(event, data, regs, perf_output_begin_forward);
}在 __perf_event_output 中真正进行了采样处理
//file:kernel/events/core.c
static __always_inline int
__perf_event_output(struct perf_event *event, ...)
{
...
// 进行采样
perf_prepare_sample(&header, data, event, regs);
// 保存到环形缓存区中
perf_output_sample(&handle, &header, data, event);
}如果开启了 PERF_SAMPLE_CALLCHAIN,则不仅仅会把当前在执行的函数名采集下来,还会把整个调用链都记录起来。
//file:kernel/events/core.c
void perf_prepare_sample(...)
{
//1.采集IP寄存器,当前正在执行的函数
if (sample_type & PERF_SAMPLE_IP)
data->ip = perf_instruction_pointer(regs);
//2.采集当前的调用链
if (sample_type & PERF_SAMPLE_CALLCHAIN) {
int size = 1;
if (!(sample_type & __PERF_SAMPLE_CALLCHAIN_EARLY))
data->callchain = perf_callchain(event, regs);
size += data->callchain->nr;
header->size += size * sizeof(u64);
}
...
}这样硬件和内核一起协助配合就完成了函数调用栈的采样。后面 perf 工具就可以读取这些数据并进行下一次的处理了。
三、FlameGraph工作过程
前面我们用 perf script 解析是看到的函数调用栈信息比较的长。
......
59848 main 412201 389052.225443: 676233 cycles:u:
59849 55651b8b5132 caculate+0xd (/data00/home/zhangyanfei.allen/work_test/test07/main)
59850 55651b8b5194 funcC+0xe (/data00/home/zhangyanfei.allen/work_test/test07/main)
59851 55651b8b51d6 main+0x3f (/data00/home/zhangyanfei.allen/work_test/test07/main)
59852 7f8987d6709b __libc_start_main+0xeb (/usr/lib/x86_64-linux-gnu/libc-2.28.so)
59853 41fd89415541f689 [unknown] ([unknown])
......在画火焰图的前一步得需要对这个数据进行一下预处理。stackcollapse-perf.pl 脚本会统计每个调用栈回溯出现的次数,并将调用栈处理为一行。行前面表示的是调用栈,后面输出的是采样到该函数在运行的次数。
# perf script | ../FlameGraph/stackcollapse-perf.pl
main;[unknown];__libc_start_main;main;funcA;funcD;funcE;caculate 554118432
main;[unknown];__libc_start_main;main;funcB;caculate 338716787
main;[unknown];__libc_start_main;main;funcC;caculate 4735052652
main;[unknown];_dl_sysdep_start;dl_main;_dl_map_object_deps 9208
main;[unknown];_dl_sysdep_start;init_tls;[unknown] 29747
main;_dl_map_object;_dl_map_object_from_fd 9147
main;_dl_map_object;_dl_map_object_from_fd;[unknown] 3530
main;_start 273
main;version_check_doit 16041上面 perf script 5 万多行的输出,经过 stackcollapse.pl 预处理后,输出只有不到 10 行。数据量大大地得到了简化。在 FlameGraph 项目目录下,能看到好多 stackcollapse 开头的文件

这是因为各种语言、各种工具采样输出是不一样的,所以自然也就需要不同的预处理脚本来解析。
在经过 stackcollapse 处理得到了上面的输出结果后,就可以开始画火焰图了。flamegraph.pl 脚本工作原理是:将上面的一行绘制成一列,采样数得到的次数越大列就越宽。另外就是如果同一级别如果函数名一样,就合并到一起。比如现在有一下数据文件:
funcA;funcB;funcC 2
funcA; 1
funcD; 1我可以通过手工画一个类似的火焰图,如下:

其中 funcA 因为两行记录合并,所以占据了 3 的宽度。funcD 没有合并,占据就是1。另外 funcB、funcC都画在A上的上方,占据的宽度都是2。
总结
火焰图是一个非常好的用于分析热点函数的工具,只要你关注性能优化,就应该学会使用它来分析你的程序。我们今天的文章不光是介绍了火焰图是如何生成的,而且还介绍了其底层的工作原理。火焰图的生成主要分两步,一是采样,而是渲染。
在采样这一步,主要依赖的是内核提供的 perf_event_open 系统调用。该系统调用在内部进行了非常复杂的处理过程。最终内核和硬件一起协同合作,会定时将当前正在执行的函数,以及函数完整的调用链路都给记录下来。
在渲染这一步,Brendan Gregg 提供的脚本会出 perf 工具输出的 perf_data 文件进行预处理,然后基于预处理后的数据渲染成 svg 图片。函数执行的次数越多,在 svg 图片中的宽度就越宽。我们就可以非常直观地看出哪些函数消耗的 CPU 多了。文章来源:https://www.toymoban.com/news/detail-470146.html
最后再补充说一句是,我们的火焰图只是一个采样的渲染结果,并不一定完全代表真实情况,但也够用了。文章来源地址https://www.toymoban.com/news/detail-470146.html
到了这里,关于剖析CPU性能火焰图生成的内部原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!