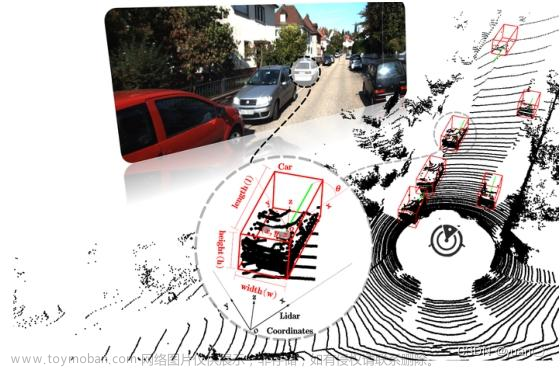
1.概述
AVOD(Aggregate View Object Detection)和MV3D类似,是一种融合3维点云和相机RGB图像的三维目标检测算法. 不同的是: MV3D中融合了相机RGB图像,点云BEV映射和FrontView映射,而AVOD则只融合相机RGB图像和点云BEV映射.
从网络结果来看,AVOD采用了基于两阶的检测网络,这让我们很容易想到同样是两阶检测网络结果的Faster RCNN物体检测网络. 一想到两阶,首先想到的就是检测精度高但检测速率慢,仅适用了是检测帧率要求不高且要求检测精度的场景.
下面是一张AVOD的网络结构图 AVOD

2. 网络结构
该网络先对输入数据经过特征提取、降维操作以及裁剪之后进行初步的融合,获取场景中包含前景的区域(进行初步的回归),然后将场景中的候选区域投影到鸟瞰图与RGB图后获得待裁剪区域进行裁剪与调整到统一的大小再经过融合获取场景中不同物体的检测类别及其3D物体检测框。
2.1 激光点云数据预处理
AVOD对于激光点云处理相对于MV3D进行了一些简化。去除了强度图,对于点云的高度图划分成M层,即z在(0,2.5)的范围内,以0.5为间隔取得5层,每层中的每个网格取高度最大的点云。
对于密度图的处理是 :

2.2特征提取
网络前端的Feature Extractor对输入数据进行了提取后获得特征图,对比MV3D中的特征提取器(改进的VGG-16),AVOD的特征提取器使用了FPN进行激光点云与RGB图像的特征提取,具有多尺度检测的能力(包含底层与高层的信息),在小物体检测方面相比于MV3D具有一定优势。

2.3 降低数据量
在经过各自的特征提取后,由通过了1*1的卷积操作降低了通道数。引用原论文中的话:
In some scenarios, the region proposal network isrequired to save feature crops for 100K anchors in GPUmemory. Attempting to extract feature crops directly from
high dimensional feature maps imposes a large memory overhead per input view. As an example, extracting 7 × 7 feature crops for 100K anchors from a 256-dimensional
feature map requires around 5 gigabytes1 of memory assuming 32-bit floating point representation. Furthermore, processing such high-dimensional feature crops with the RPN greatly increases its computational requirements.
AOVD的两阶体现在两个方面: 目标框检测, 数据级和特征级两步融合. 基本过程如下:
一. AVOD对RGB图像和点云BEV分两路使用FPN网络(关于FPN的细节不再阐述)进行特征提取,获取两种输入的全分辨率特征映射: 图像特征映射和BEV特征映射(高度图和密度图).
二.对于两种特征映射,为了对它们进行融合,需要调整到一致的尺寸, 分别对它们进行1x1卷积,进一步提取特征,然后调整同样尺寸后, 进行融合. 这是第一融合,相对于第二次融合,该次融合相当于数据级融合.
三. 经第一次融合后的特征,送入一个类似Faster RCNN的RPN网路,经全连接层和NMS后,经第一次分类和3DBBox回归后, 生成一些列区域建议框(候选框),
四. 生成的建议框分别和第一步生成的两路特征映射一起,经调整尺寸后,进行第二次融合(区域建议框融合).
五. 融合后的特征,经全连接层第二次分类和3DBBox回归运算后,经NMS后期处理,最终生成目标检测框.
2.5检测框编码
在AVOD中,算法采用两种方式来表达BEV数据: 高度图 和 密度图
高度图: 从BEV视角区域,划分为一定尺寸的网格,比如: MxN. 在每一个网忘格里,在从高度方向将0-2.5高的垂直空间划分为K层,这样就把BEV视角的点云空间划分为M x N x K的立体格(Voxel), 同时找出每个立体格内的最大高度H_max。这样,有这M x N x K个H_max就构成了高度图。
密度图: 基于上一步的M x N x K的立体格(Voxel), 计算每个立体格的点云点密度,计算公式为 ,由此M x N x K个密度值构成密度图。
创新性的3维边界框的向量表示形式:
一般的做法是: 对于2维检测框,采用4x2(x,y)共8个值,或中心点+尺寸表示法: 1(长)+1(宽)+2(x,y)共4个值. 而对于3维检测框,采用8x3(x,y,z)共24个值.
AVOD创新性的采用了底面边框+上下面离地高度形式,即; 4x2(x,y) + 2x高的形式,共10个值. 详细见下图, 图中左侧为MV3D的24值表示法,右侧为AVOD的10值表示法:

2.6朝向估计
在MV3D中对于物体朝向的估计是根据物体的长边来大致确定物体的朝向,但是这种方法无法区分相差±180°的情况,同时对于行人的检测这种方法也不太可行。文章来源:https://www.toymoban.com/news/detail-470351.html
因此,针对这种问题AVOD中使用了一种方法,在朝向估计中引入了,限制在。这样在朝向相差180°是就会不会出现分歧,都有各自特定的数值。
 文章来源地址https://www.toymoban.com/news/detail-470351.html
文章来源地址https://www.toymoban.com/news/detail-470351.html
到了这里,关于视觉与激光雷达融合3D检测(一)AVOD的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!