python数据分析练习,具体数据不放出。
分析实践很简单。目的不是做完,而是讲清楚每一步的目的和连带的知识点(所以才叫学习笔记)
0.数据准备
原始数据格式:csv文件
原始数据结构:
| 数据格式 | 字段名 |
| int(无用信息) | 无 |
| String | che300_brand_name |
| float | new_price |
| String | maker_type |
| float | lowest_price |
| String | car_level_name |
| int | age_month |
| String | brand |
| float | age |
| String | maker |
| int | cluster |
1.导包
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns"warnings" 是警告过滤器,没有实际作用。
"seaborn" 是一个基于 Matplotlib 的图形可视化库,可以用于绘制统计图表,如密度图、散点图、线性回归图等。
2.读取&初步处理
读数据:
data = pd.read_csv('二手车折旧分析.csv',encoding='gb2312')利用 pandas 读csv文件,第二个参数是设置编码,默认编码会使用 'utf-8' ,但这里的数据中有中文,需要使用支持简体中文的编码,如下图所示,可选择 'gb2312' 'gbk' 'gb18030'

查看更多详细编码:codecs — Codec registry and base classes — Python 3.11.3 documentation
查看数据:
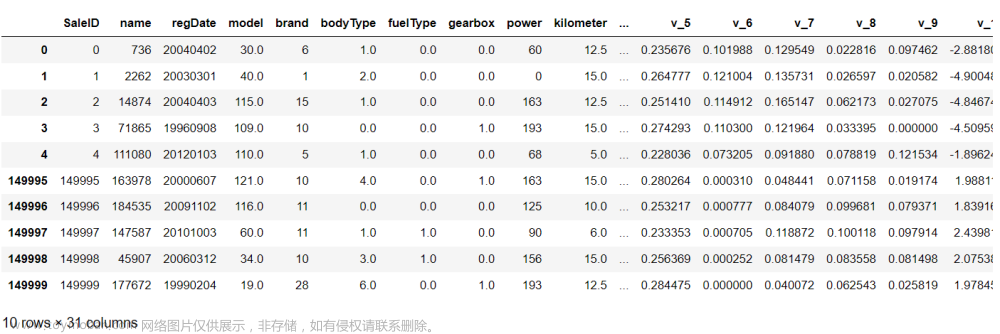
data.head(5) # 查看前五行
data.describe() # 查看数据描述这里的 describe() 函数会自动出每一列是数值的数据的计数、均值、标准差、四分位数、二分位数、最值。相当于一次性使用了8次聚合函数,非常便于初步总览数据。
初步处理:
模拟真实数据中有不需要的列/行,可以进行删除。
如本例中的第一列,没有列名,那么再上一步查看数据的时候列名会显示为 'Unnamed: 0'
data = data.drop('Unnamed: 0',axis = 1)drop 函数第一个参数是列名,第二个参数 axis = 0 :删除行 ; axis = 1 :删除列。
3.数据清洗——残值率计算:
假设现在我们需要关注一个值——残值率的准确性。
如果你恰巧学过会计学,对这个词应该不陌生。
在会计记账过程中,资产的价值是每年会降低的,这很好理解,因为任何有形资产(如机器设备、车辆)都有使用年限,它们会随着时间磨损、消耗,最终报废,也就是资产归零。而每年在计算它们的价值时,应当根据剩余使用年限计算一个当前剩余的价值。
比如一辆价值10万元的车,如果理论上使用10年就会报废,那么它在使用2年后的资产价值就是10-10/10*2=8万元,这里面损失的2万元就是折旧,剩余的8万元就是残值,也就是此处的lowest_price 字段。
资产原值(new_price)/资产残值(lowest_price)= 残值率
正常情况下,残值率肯定低于1。
那么残值率高于1的数据就是错误数据,需要处理:
data['残值率'] = data['lowest_price']/data['new_price']给 DataFrame 添加一列,计算残值率,命名为“残值率”;
question_data = data[data['残值率'] > 1]
question_data.head(5) # 查看异常数据
question_data.count() # 异常数据总数筛选残值率高于1的数据进行探查;
data = data[data['残值率'] < 1]去除异常数据,进行数据清洗。文章来源:https://www.toymoban.com/news/detail-470418.html
(未完待续)文章来源地址https://www.toymoban.com/news/detail-470418.html
到了这里,关于python笔记16_实例练习_二手车折旧分析p1的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!