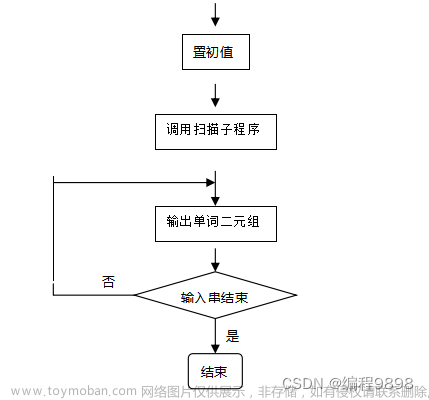
前言
来写语法分析器了,有可能是老师不一样也有可能是学校不一样,我要做的语法分析器复杂一点,额,现在想来也不复杂(可能)。
这一次的实验是要进行语法分析,是要用LL1或者递归下降分析法或LR分析法(LR0、LR1)设计语法分析程序。这次我也是先去百度看看别人的程序是怎么写的,开了几篇,原来就是实现一下文法啊,然后我纠结了一下,选了使用LR(1)文法,因为用这个文法不用对输入的文法进行处理(消除左递归、消除空串这些)(那时候没验收不知道原来文法可以自己手写出来再写进代码)。总而言之,就是比较容易实现(我以为)。结果求项目集闭包的时候把我难住了,要考虑很多问题,特别是,项目集可能会有回路,也就是自己到自己。不过修改了一下文法的存储结构后我也成功实现了。
后来我才知道,原来语法分析器要分析的是一段程序,而且需要和词法分析器结合在一起。所以,为了符合要求,又将存储结构改了一遍,然后才可以。
前面的前言主要是吐糟,可以不看哦。
这里简单提醒一下,因为我修改了原来实现LR1的代码,所以这篇文章可能不适合大部分人的语法分析器实验,是这样的:我的终结符全是数字(包括#也改为数字了),非终结符规定只会有一位。
设计思路
1、因为文法是自己设置的,所以可以自己规定文法的结构,所以规定,开始符的规则一定只有一条,所以不用补充开始符。因此所有非终结符就可以设置为一位的,就不用开二维数组来保存非终结符了。同时,因为用的VS编译器不支持输出ASCII码之外的阿拉伯符号,因此我用->表示规则中的箭头,.表示项目集中的点。
2、因为要对程序进行分析,然后词法分析器输出的是单词表中的种别码,所以,设置终结符全部为数字。因为语法分析器的输入应该是词法分析器的输出,所以,用一个全局一维数组来将词法分析输出的每个种别码保存,并记录个数,作为语法分析器的输入串。同时,因为将种别码对应的单词(关键字、标识符、运算符、界符、整型和浮点型)输出格式不好看,所以我直接对种别码进行分析,文法也是用种别码来当作终结符构造的。
3、LR(1)文法的难度主要是在如何构造项目集和分析表。我创建了一个结构体来保存并构建项目集。项目集和项目集的闭包都是用模拟算法求的,也就是直接模拟做题时的步骤将算法写出。同时,为了构造分析表,在每个项目集求完闭包之后,要将项目集与下一个项目集的联系保存。为了保存项目之间的联系,用pair定义了两个新的二元组类型CI和PII。


因为非终结符是单个大写字母,而终结符是整型数字,所以创建了两个二元组来分别保存,二元组第一个元素表示的时非终结符或终结符,第二个元素则表示下一个项目集的编号。
因为LR(1)分析法求闭包需要求向前搜索符,所以我单独写了个求first集的函数,但是这个求first的函数仅求一个终结符并且不能求太复杂的规则的first。此外,因为在求项目集时要判断点后面的字符是非终结符还是终结符,因此还写了判断点后面是否是非终结符以及求点后面的非终结符和终结符的函数。还写了规则中点移动的函数,因为保存项目集的结构体是定义为全局变量的,所以如果直接将规则传入函数的话,会将项目集中的规则改变,所以定义了一个临时变量来进行移动,点移动之后在将临时变量的值赋给下一个项目集的规则。

4.还有一个非常重要的问题,就是项目集可能会有回路(环路)的问题,这个问题不解决的话会导致函数会一直求下一个项目集知道结构体数组爆栈。所以一定要进行处理,解决的办法就是在求出下一个项目集的闭包后,遍历当前结构体中的项目,一一判断给项目集是否重复,如果重复,则将对应的联系保存。这样就不会导致结构体数组爆栈了。

将各个项目集的闭包和项目集之间的联系求出并保存到结构体之后,求分析表就比较简单了,因为分析表就是根据各个项目集及其之间的联系求出的。接下来就是栈的问题,一开始我们定义了两个栈,一个栈为整型栈,用来作为状态栈;另一个是字符串类型的栈,用来作为符号栈,因为终结符是整型,会有两位的整型。同时分别写了对应的输出栈的函数(用一个数组保存并倒叙进行输出)。之后按思路进行对应的分析即可。但是一直得不到想要的结果,进行调试发现在使用strcpy函数的时候,程序会毫无原因的改变原本符号栈的值。因此将符号栈也改为用整型表示,有一个问题就是,符号栈中不仅有整型,还有单个大写字母。用整型怎么表示它们呢,我发现我们的单词表中的种别码范围是1-87,而ASCII码中,第一个大写字母A的编号是65,第一个小写字母a是97,直接用大写字母的编号肯定会冲突,但是小写字母和大写字母的编号差是固定的32,而小写字母a开头便是97,不会和单词表中的终结符进行冲突,因此可以用小写字母的ASCII编号表示大写字母,在输出时,将小写字母的编号转为大写字母即可。这样,就解决了所有问题,成功的将结果输出。
程序存在的问题
其实也不能说是问题,只是一些不足罢了。
1、求first集存在一些问题,就是当点后面的非终结符后面是非终结符时,只进行了一轮遍历,比如说,在当一个项目集中只有[A->B.CD,#]时,要求闭包,点后面的非终结符是C,C后面还是一个非终结符,然后将左边非终结符为D的全部放进项目中,这个就叫求闭包,但是除了规则外还要有向前搜索符,这个向前搜索符就是first(D#)中的一个,所以只需要求first集中的一个就好,不用全部求完。但是问题就出现在这里,如果文法中D非终结符的左边第一个字符没有终结符的话,程序不会再对D左边的第一个非终结符进行求first,而是直接返回上一个规则的向前搜索符。
(越描越黑,文法左边第一个大都是终结符的可以不理了,毕竟只是一个实验的代码,没考虑那么全面。)
源代码
原本是用多文件编程的,但是为了方便,就放在一起了,是可以直接运行的,需要C++环境。运行不了可以私聊我。
需要注意的是,程序的输入是采用文件输入,test.txt文件放文法(尽量不要有空行且每行的末尾不要有空格,空行处理了但是末尾空格没有进行处理),test1.txt文件放要分析的代码。
且程序是可以输出项目集和分析表的,但是项目集超过15个分析表的显示就乱了,因为每行的输出太长了。不过输不输出项目集和分析表是可以控制的。具体看主函数的代码就好了。
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<algorithm>
#include<stack>//调用堆栈
using namespace std;
#define Maxline 124
const int N = 505; //定义数组大小
typedef pair<char, int>CI;//定义一个二元组来保存项目集之间的联系,是非终结符的联系
typedef pair<int, int>PII;//定义一个二元组来保存项目集之间的联系,是终结符之间的联系
//------语法分析的结构体------
struct GS { //用来保存文法的结构体
char gs[N][50]; //用来保存规则的数组
char vn[N]; //用来保存非终结符,文法确保都是一位的非终结符
int vt[N]; //用来保存终结符,用种别码来表示终结符,所以终结符都是数字
int nvn = 0, nvt = 0; //这两个变量分别用来记录非终结符数组、终结符数组中的个数
int ngs = 0; //这个变量用来记录规则数
};
struct IGS { //项目集里的规则
char igs[50]; //规则
int x; //作为向前搜索符
};
struct DFATree { //规则集的结构
int i; //项目集编号
IGS gather[N]; //这个项目下面的规则
int sum = 0; //该项目集中的规则数量
int nci = 0, npii = 0; //用来记录该项目的下一个项目集的个数
CI nextci[20]; //记录项目之间的非终结符联系
PII nextpii[20]; //记录项目之间的终结符联系
};
struct TABLE {
int i; //表示分析表中的状态
CI ci[20]; //非终结符的联系,也就是goto
PII pii[20]; //终结符的联系,也就是action
int nci = 0, npii = 0; //分别表示非终结符和终结符的个数
};
//------词法分析函数声明------
bool pd_integer(char ch); //判断是否是数字
bool pd_character(char ch); //判断是否是小写字母
bool pd_character2(char ch); //判断是否是大写字母
int pd_keyword(char s[]); //判断字符串是否是保留字(关键字)是则返回下标,否则返回-1
int pd_delimiter(char ch); //判断字符是否是界符,是返回下标,否则返回-1
int pd_calculation(char s[]); //判断字符串是否是运算符,是返回下标,否则返回-1
char* pd_spcode(int n); //根据种别码的范围判断类别
bool pd_int36(char s[]); //判断是否是int36类型的变量
int search_spcode(char s[]); //查询字符串s的种别码
void output(); //原来的词法分析器输出
//------语法分析函数声明------
bool pd_invn(char ch); //判断字符串是否已经在非终结符数组中
bool pd_invt(int n); //判断字符是否在终结符数组中
bool pd_pafter(char s[]); //判断输入的规则中.后面是否是非终结符,是则返回真
void add_vn(char ch); //将不在非终结符数组中的非终结符放入数组
void add_vt(int n); //将不在终结符数组中的终结符放入数组
char* add_point(char s[]); //给规则加点,放在右边第一位
char get_first(IGS st); //求first集,只返回一个字符作为向前搜索符
char get_pafter(char s[]); //求点后面的非终结符
int get_pafter2(char s[]); //求点后面的终结符(数字)
void get_closure(); //求全部项目以及闭包
int get_rule(char s[]); //获取输入的规则(带点.)在文法中的位置
char* get_i_input(char s[], int i); //获取第i个输入的数字
int get_strtoint(char s[]); //将输入的数字字符串转为整型返回
char* get_inttostr(int n); //将数字转为字符串
int get_number(char s[]); //求输入串中的终结符个数
int get_leftnumber(char s[]); //求规则左边的长度,实际就是终结符和非终结符的个数之和
char* move_point(char s[]); //将规则中的点.往后移动一个位置,并返回移动后的规则
void print_gs(); //输出非终结符和扩展后的文法
void print_dfa(); //输出DFA
void print_table(); //输出分析表
void print_stack(stack<int> ss); //将堆栈中的元素输出(要倒过来)
void open_file(); //打开文件,并将文件中的规则读入,并进行扩展
void analysis_table(); //生成分析表
void input_analysis(); //进行输入并进行分析
char* spcode_to_character(int n, char s[]);//将种别码转换为字符串返回
//#include"HeadAndStruct.h"
//-----词法分析全局变量------
char keyword[][10] = { "auto","bool","break","case","char","const","continue","default","do"
,"double","else","enum","extern","float","for","goto","if","int","long","main","register","return"
,"short","signed","sizeof","static","struct","switch","typedef","union","unsigned","void","volatile"
,"while","scanf","printf","include","define","int36" }; //39个保留字(关键字)
char delimiter[][10] = { "(",")","[","]","{","}",".",",",";","'","#","?",'"', };//13个界符
char calculation[][10] = { "[+]","[-]","[*]","[/]","[%]","[++]","[--]","[==]","[!=]","[>]","[<]","[>=]"
,"[<=]","[&&]","[||]","[!]","[=]","[+=]","[-=]","[*=]","[/=]","[%=]","[&=]","[^=]","[|=]","[&]","[|]"
,"[^]","[~]","[<<]","[>>]" };//31个运算符
int nk = 39, nd = 13, nc = 31;//分别表示关键字、界符、运算符的个数
//下面分别是关键字、界符、运算符、整型、浮点数和标识符在单词表中的偏移量,int36类型为87;
int ck = 1, cd = 71, cc = 40, ci = 84, cf = 85, cn = 86, cint36 = 87;
char int36[10][100]; //int36类型的变量标识符
int n_int36 = 0;
bool flag3 = false, flag4 = false;//用于标记
int the_spcode[N];//创建一个整型数组,将词法分析器的一行代码传到语法分析器
int nsp = 0;//记录数组中的种别码个数
//------函数实现------
bool pd_integer(char ch) //判断是否是整数
{
if (ch >= '0' && ch <= '9')return true;
return false;
}
bool pd_character(char ch) //判断是否是小写字母
{
return (ch >= 'a' && ch <= 'z');
}
bool pd_character2(char ch) //判断是否是大写字母
{
return ch >= 'A' && ch <= 'Z';
}
int pd_keyword(char s[]) //判断字符串是否是保留字(关键字)是则返回下标,否则返回-1
{
for (int i = 0; i < nk; i++)
if (strcmp(s, keyword[i]) == 0)return i;
return -1;
}
int pd_delimiter(char ch) //判断字符是否是界符,是返回下标,否则返回-1
{
for (int i = 0; i < nd; i++)
if (ch == delimiter[i][0])return i;
return -1;
}
int pd_calculation(char s[]) //判断字符是否是运算符,是返回下标,否则返回-1
{
for (int i = 0; i < nc; i++) {
if (strlen(calculation[i]) - 2 == strlen(s)) {//如果长度相等
bool flag = true;
for (int j = 1, k = 0; j < strlen(calculation[i]) - 1 && k < strlen(s); j++, k++)
if (calculation[i][j] != s[k]) {
flag = false;//有一个元素不等,标记后直接退出
break;
}
if (flag)return i;//返回下标
}
}
return -1;
}
bool pd_int36(char s[]) //判断是否是int36类型的变量
{
for (int i = 1; i < n_int36; i++)
if (strcmp(int36[i], s) == 0) return true;
return false;
}
char* pd_spcode(int n) //根据种别码的范围判断类别
{
static char name[20];//静态局部变量
if (n >= 1 && n <= nk) strcpy(name, "关键字");
else if (n >= cc && n < cd) strcpy(name, "运算符");
else if (n >= cd && n < ci) strcpy(name, "界符");
else if (n == ci) strcpy(name, "整型");
else if (n == cf)strcpy(name, "浮点型");
else if (n == cn) strcpy(name, "标识符");
else if (n == cint36) {
strcpy(name, "int36");
flag4 = false;//取消标记
}
else strcpy(name, "未识别");
return name;
}
int search_spcode(char s[]) //查询字符串s的种别码
{
if (pd_character2(s[0]))return cint36;
for (int i = 0; i < strlen(s); i++)
if (pd_character2(s[i])) return cint36;
if (pd_character(s[0])) { //如果第一个字符是小写字母,说明是关键字或标识符
if (pd_keyword(s) != -1) //说明是关键字
return pd_keyword(s) + ck;//下标从0开始,要+1
else return cn; //否则就是标识符(标识符可以有下划线)
}
if (s[0] == '_')return cn;//下划线开头一定是标识符
if (pd_integer(s[0])) {//开头是数字说明是整数或者浮点数
if (flag4) return cint36;//如果被做了标记,说明是int36类型
if (strstr(s, ".") != NULL)return cf;//如果有小数点说明是浮点型
return ci;//否则就是整型
}
if (strlen(s) == 1) { //长度为1,说明是界符或者运算符
char ch = s[0];
if (pd_delimiter(ch) != -1)//判断是否是界符
return pd_delimiter(ch) + cd;
}
if (pd_calculation(s) != -1)//如果是运算符
return pd_calculation(s) + cc;
return -1;//否则就是未标识符
}
void output() //原来的词法分析器输出
{
char test[N] = { 0 };
FILE* fp = fopen("test1.txt", "r");
if (fp == NULL) {
printf("打开文件失败!\n");
return;
}
while (fgets(test, Maxline, fp) != NULL) {
int i = 0, j = 0;//用kk来记录一行种别码的个数
while (i < strlen(test)) {
if (test[i] == ' ' || test[i] == '\n' || test[i] == '\t') {
i++;
continue;//遇到空格或换行符,跳过
}
bool flag = true;
char str[50] = { 0 };
j = 0;
if (test[i] == 'i' && test[i + 1] == 'n' && test[i + 2] == 't' && test[i + 3] == '3' && test[i + 4] == '6') {
str[j++] = test[i];
str[j++] = test[i + 1];
str[j++] = test[i + 2];
str[j++] = test[i + 3];
str[j] = test[i + 4];
i += 4;
}
else if (pd_character2(test[i])) {
while (pd_character2(test[i]) || pd_integer(test[i]))str[j++] = test[i++];
i--;
}
else if (pd_integer(test[i])) {
//如果是数字,循环读取,包括小数点,因为可能是浮点数
int k = i;
bool flag2 = false;
while (pd_integer(test[k]) || pd_character2(test[k])) {
if (pd_character2(test[k]))flag2 = true;
k++;
}
if (flag2) {
while (pd_integer(test[i]) || pd_character2(test[i])) {
if (test[i] == '.')flag = false;//浮点型只允许出现一个小数点
str[j++] = test[i++];
}
}
else {
while (pd_integer(test[i]) || (test[i] == '.' && flag)) {
if (test[i] == '.')flag = false;//浮点型只允许出现一个小数点
str[j++] = test[i++];
}
}
i--;
if (search_spcode(str) == ci) {//如果是整型,判断是否是int36类型
k = i;
int l = 0;
char str1[20] = { 0 }, str2[20] = { 0 };//用一个新建的变量来保存变量
while (test[k] != '=' || test[k] == ' ') k--;//test[k]=='=';
k--;
while (pd_integer(test[k]) || pd_character(test[k]) || test[k] == '_') {
str1[l++] = test[k];
k--;
}
//将变量名倒过来
int jj = 0;
for (int ii = 0; ii < l; ii++) {
str2[jj++] = str1[l - ii - 1];
}
if (pd_int36(str2)) flag4 = true;
}
}
else if (pd_character(test[i]) || test[i] == '_') {
//如果是字母或下划线或数字(标识符可以有数字)
while (pd_character(test[i]) || test[i] == '_' || pd_integer(test[i]))str[j++] = test[i++];
i--;
}
else if (test[i] == '+' || test[i] == '-' || test[i] == '*' || test[i] == '/'
|| test[i] == '%' || test[i] == '=' || test[i] == '!' || test[i] == '>'
|| test[i] == '<' || test[i] == '&' || test[i] == '|' || test[i] == '^') {
if (test[i + 1] == '=' || test[i] == test[i + 1]) {
str[0] = test[i], str[1] = test[i + 1];
i++;
}
else {
str[0] = test[i];
}
}
else {
str[0] = test[i];
}
i++;
if (strcmp(str, "int36") == 0 && !flag3)flag3 = true;
else if (str[0] == ';' && flag3)flag3 = false;
if (flag3 && (str[0] == '_' || pd_character(str[0]))) {
if (!pd_int36(str))strcpy(int36[n_int36++], str);//如果变量不在数组里面,就放进去
}
int a = search_spcode(str);//用一个变量临时保存种别码
//将种别码保存进数组
the_spcode[nsp++] = a;
//printf("( %s , %d )------%s\n", str, a, pd_spcode(a));
}
}
return;
}
//#include"Lexical_Analyzer.h"
//------语法分析全局变量------
DFATree dfa[N];//创建dfa
GS gs;//创建保存文法的结构体
int ni = 0;//项目集数目
TABLE table[N];//创建分析表的结构,table的个数就是项目集的个数
//------主函数------
int main()
{
output();//在词法分析器读取保存程序的文件,将程序换成种别码并保存进一个全局数组中
printf("输入串为:\n");
for (int i = 0; i < nsp; i++) //将每行代码的种别码输出
printf("%d ", the_spcode[i]);
printf("\n");
open_file();//打开并载入文件
//print_gs();//输出非终结符和扩展后的文法
get_closure();//求项目集闭包
//print_dfa();//输出项目集及其联系
analysis_table();//生成分析表
//print_table();//输出分析表
input_analysis();//进行输入并进行分析
return 0;
}
//------函数实现------
bool pd_invn(char ch)//判断字符串是否已经在非终结符数组中
{
for (int i = 0; i < gs.nvn; i++)//直接进行遍历
if (gs.vn[i] == ch) return true;
return false;
}
bool pd_invt(int n)//判断字符是否在终结符数组中
{
for (int i = 0; i < gs.nvt; i++)//直接遍历一遍
if (gs.vt[i] == n)return true;
return false;
}
bool pd_pafter(char s[])//判断输入的规则中.后面是否是非终结符,是则返回真
{
int i = 0;
while (s[i] != '.')i++;//找到.的位置
if (i == strlen(s) - 1)return false;//说明点在最后一位
i++;
while (s[i] == ' ')i++;//过滤空格
return pd_character2(s[i]);//直接将结果返回,如果是大写字母,则为真,否则为假
}
void add_vn(char ch)//将不在非终结符数组中的非终结符放入数组
{
gs.vn[gs.nvn] = ch;
gs.nvn++;//个数+1
}
void add_vt(int n)//将不在终结符数组中的终结符放入数组
{
gs.vt[gs.nvt] = n;
gs.nvt++;//个数+1
}
char* add_point(char s[])//给规则加点,放在第一位即箭头的后面
{
static char str[200] = { 0 };
memset(str, 0, sizeof str);//因为是静态变量,需要进行清空,不然上一次的str值会有残留
int i = 0, j = 0;
while (i < strlen(s)) {
if (s[i] == '-' && s[i + 1] == '>') {
str[j++] = '-';
str[j++] = '>';
str[j++] = '.';
i += 2;
}
else str[j++] = s[i++];
}
return str;
}
char get_first(IGS st)//求first集,只返回一个字符作为向前搜索符,要求first说明点后面一定是非终结符
{
char s[10] = { 0 }, ss[10] = { 0 };
int i = 0, n = strlen(st.igs);
while (st.igs[i] != '.')i++;
if (i == n - 1)return st.x;//说明点.是最后一个
i++;//否则移到下一位
while (st.igs[i] == ' ')i++;//过滤空格
//过滤玩空格后,i的位置就是点后面的非终结符的位置
if (i == n - 1) return st.x;//说明非终结符后面没有字符
i++;
//说明非终结符后面有字符
while (st.igs[i] == ' ')i++;//去掉空格
int thevt = 0;
if (pd_character2(st.igs[i])) {//如果点后面的非终结符后面的是一个非终结符
char t = st.igs[i];//取出非终结符
for (int j = 0; j < gs.ngs; j++) {//遍历文法中的规则
//这里不考虑规则右边第一个就是非终结符的情况
if (t == gs.gs[j][0] && pd_integer(gs.gs[j][3])) {//头部相等并且第一个字符是终结符
int k = 3;
while (pd_integer(gs.gs[j][k])) {
thevt = thevt * 10 + gs.gs[j][k] - '0';
k++;
}
return thevt;
}
}
return st.x;
}
while (pd_integer(st.igs[i])) {
thevt = thevt * 10 + st.igs[i] - '0';
i++;
}
return thevt;
}//求first还没写好
char get_pafter(char s[])//求点后面的非终结符,先使用pd_pafter()函数判断后面是不是非终结符
{
int i = 0;
while (s[i] != '.')i++;//找到.的位置
if (i == strlen(s) - 1)return '0';//说明点是最后的了
i++;
while (s[i] == ' ')i++;//过滤空格
return s[i];
}
int get_pafter2(char s[])//求点后面的终结符(数字)
{
int i = 0;
while (s[i] != '.')i++;//先找到点的位置
i++;
while (s[i] == ' ')i++;//过滤空格
int thevt = 0;
while (pd_integer(s[i])) {
thevt = thevt * 10 + s[i] - '0';
i++;
}
return thevt;
}
void get_closure()//求全部项目以及闭包
{
dfa[ni].i = ni;
dfa[ni].sum = 1;
strcpy(dfa[ni].gather[0].igs, add_point(gs.gs[0]));//给规则加点
dfa[ni].gather[0].x = 81;//赋值向前搜索符,#的种别码为81
int aj = 0;
while (aj < dfa[ni].sum) {
if (pd_pafter(dfa[ni].gather[aj].igs)) {//如果点后面是非终结符,说明需要进行扩充
for (int k = 1; k < gs.ngs; k++) {
if (get_pafter(dfa[ni].gather[aj].igs) == gs.gs[k][0]) {
strcpy(dfa[ni].gather[dfa[ni].sum].igs, add_point(gs.gs[k]));//将规则赋值到项目集中
dfa[ni].gather[dfa[ni].sum++].x = get_first(dfa[ni].gather[aj]);//获取向前搜索符并进行赋值
}
}
}
aj++;
}
ni++;
int now_i = 0, i = 0;//用now_i表示当前求到的项目号,i表示当前的项目号
while (i < ni) {
bool vis[N] = { 0 };//创建一个数组标记该项目中的某条规则是否已经遍历过
for (int j = 0; j < dfa[i].sum; j++) {//遍历该项目集
//如果这一条规则如果最后一位不是'.',说明可以往后移,并且没有进行移位过的规则才能进来
if (dfa[i].gather[j].igs[strlen(dfa[i].gather[j].igs) - 1] != '.' && !vis[j]) {
now_i++;//求到下一个项目号
bool flag = pd_pafter(dfa[i].gather[j].igs);//用来判断.点后面是非终结符还是终结符
char tci = { 0 };
int tpii = 0;
if (flag) {//如果是非终结符
tci = get_pafter(dfa[i].gather[j].igs);//将.后面的一个字符赋值给t,后面用来记录
dfa[i].nextci[dfa[i].nci].first = tci;
dfa[i].nextci[dfa[i].nci++].second = now_i;
}
else {//如果是终结符
tpii = get_pafter2(dfa[i].gather[j].igs);
dfa[i].nextpii[dfa[i].npii].first = tpii;
dfa[i].nextpii[dfa[i].npii++].second = now_i;
}
//取出点后面的一个符号(非终结符或终结符)
for (int k = j; k < dfa[i].sum; k++) {
char tm[50] = { 0 };//创建一个临时变量来进行移动,不然输入全局变量进行移动会使移动无法撤销
if (tci == get_pafter(dfa[i].gather[k].igs) && !vis[k] && flag) {//下一位是
//这里把.后面符号相同的放到同一个项目集
vis[k] = true;//进行标记
strcpy(tm, dfa[i].gather[k].igs);
strcpy(dfa[now_i].gather[dfa[now_i].sum].igs, move_point(tm));
dfa[now_i].gather[dfa[now_i].sum++].x = dfa[i].gather[k].x;
}
if (tpii == get_pafter2(dfa[i].gather[k].igs) && !vis[k] && !flag) {
vis[k] = true;//标记
strcpy(tm, dfa[i].gather[k].igs);
strcpy(dfa[now_i].gather[dfa[now_i].sum].igs, move_point(tm));
dfa[now_i].gather[dfa[now_i].sum++].x = dfa[i].gather[k].x;
}
}
//这里进行项目集的扩展(求闭包)
int k = 0;
while (k < dfa[now_i].sum) {//遍历新的项目集
if (pd_pafter(dfa[now_i].gather[k].igs)) {
for (int p = 0; p < gs.ngs; p++) {
if (get_pafter(dfa[now_i].gather[k].igs) == gs.gs[p][0]) {
//找到了.后面对应的非终结符,将该非终结符的规则放到当前求的项目集里面
//要先判断现有的项目集中是否已经有了该规则
char tm[50] = { 0 };
int gfirst = get_first(dfa[now_i].gather[k]);
bool nflag = true;
strcpy(tm, add_point(gs.gs[p]));
for (int kt = 0; kt < dfa[now_i].sum; kt++) {
if (dfa[now_i].gather[kt].x == gfirst &&
strcmp(dfa[now_i].gather[kt].igs, tm) == 0) {
nflag = false;
break;
}
}
if (nflag) {//如果该规则不存在现有项目集中s,则放入项目集中
strcpy(dfa[now_i].gather[dfa[now_i].sum].igs, tm);
dfa[now_i].gather[dfa[now_i].sum++].x = gfirst;
}
}
}
}
k++;
}
dfa[now_i].i = now_i;//给新的项目集赋予编号
//进行查重
bool nflag = true;
for (int j = 0; j < ni; j++) {//遍历所有项目集
int fsum = 0;
if (dfa[now_i].sum == dfa[j].sum) {//先判断项目集中的规则数量是否相等
for (int k = 0; k < dfa[j].sum; k++) {//规则数目相等则进行一一判断
if (dfa[now_i].gather[k].x == dfa[j].gather[k].x
&& strcmp(dfa[now_i].gather[k].igs, dfa[j].gather[k].igs) == 0) {
fsum++;
}
}
if (fsum == dfa[j].sum) {//如果两个项目集中的规则全部相等
nflag = false;//标记
dfa[now_i].sum = 0;//将该项目集的个数清零
if (flag) dfa[i].nextci[dfa[i].nci - 1].second = j;
else dfa[i].nextpii[dfa[i].npii - 1].second = j;
now_i--;//将项目集减回去
break;
}
}
}
if (nflag)ni++;//如果这个项目集前面没有出现过,那么项目集个数+1
}
}
i++;
}
}
int get_rule(char s[])//获取输入的规则(带点.)在文法中的位置
{
//输入的虽然是局部变量的形式,但是这个局部变量实际是一个全局变量,所以不要修改输入的变量
char ss[50] = { 0 };//而是创建一个新的数组来保存去掉.之后的规则
int j = 0;
for (int i = 0; s[i]; i++)
if (s[i] != '.')ss[j++] = s[i];
for (int i = 0; i < gs.ngs; i++) //遍历文法规则进行对比
if (strcmp(ss, gs.gs[i]) == 0)return i + 1;//返回下标+1,因为数组中是从0开始
}
char* get_i_input(char s[], int i)//获取第i个输入的数字
{
static char ss[10] = { 0 };
memset(ss, 0, sizeof ss);
int n = i, j = 0;
while (n--) {
int k = 0;
memset(ss, 0, sizeof ss);
while (pd_integer(s[j]))ss[k++] = s[j++];//翻过i个数字
while (s[j] == ' ')j++;//过滤空格
}
return ss;
}
int get_strtoint(char s[])//将输入的数字字符串转为整型返回
{
int thesum = 0, i = 0;
while (i < strlen(s)) {
thesum = thesum * 10 + s[i] - '0';
i++;
}
return thesum;
}
char* get_inttostr(int n)//将数字转为字符串
{
static char tss[20] = { 0 };
memset(tss, 0, sizeof tss);
int m = 0;
while (n != 0) {//先将数字倒过来
m = m * 10 + n % 10;
n /= 10;
}
int j = 0;
while (m != 0) {
tss[j++] = m % 10 + '0';
m /= 10;
}
return tss;
}
int get_number(char s[])//求输入串中的终结符个数
{
int n = 0, i = 0;
while (i < strlen(s)) {
while (pd_integer(s[i]))i++;
n++;//计数
while (s[i] == ' ')i++;//过滤空格
}
return n;
}
int get_leftnumber(char s[])//求规则左边的长度,实际就是终结符和非终结符的个数之和
{
int sum = 0, i = 0;
while (s[i] != '>')i++;
i++;
while (i < strlen(s)) {
while (s[i] == ' ')i++;
if (pd_character2(s[i]))i++;
else {
while (pd_integer(s[i]))i++;
}
sum++;
}
return sum;
}
char* move_point(char s[])//将规则中的点.往后移动一个位置,并返回移动后的规则
{
static char ss[50];
memset(ss, 0, sizeof ss);
int i = 0, j = 0;
while (s[i] != '.') ss[j++] = s[i++];//用while循环找到.的位置
int thep = i;//先记录点的位置
if (i != strlen(s) - 1) {//如果点不在最后一个
if (pd_pafter(s)) {//如果后面是非终结符
if (s[i + 1] == ' ') {//如果点后面是空格,将空格与点的位置进行交换
swap(s[i], s[i + 1]);
i++;
}
swap(s[i], s[i + 1]);
return s;
}
else {//如果后面是终结符
i++;
while (s[i] == ' ')i++;//先过滤空格
while (pd_integer(s[i]))i++;//移到下一个数字
//到这里i是下一个终结符后的位置,要把点加到当前位置
thep++;
while (thep < strlen(s)) {
if (thep != i)ss[j++] = s[thep++];
else ss[j++] = '.', i--;
}
if (strstr(ss, ".") == 0)ss[j++] = '.';//如果这时候还没有点,说明要加的点应该在最后一位
//printf("%s\n", ss);
return ss;
}
}
return s;
}
void open_file()//打开文件,并将文件中的规则读入
{
char test[N];//用来读取文件的数组
char gs_temp[N][50] = { 0 };//用来临时存放文法的数组,就是扩展之前的文法
int ngs_temp = 0;//临时存放文法的个数
FILE* fp = fopen("test.txt", "r");//以只读的方式打开文件
if (fp == NULL) {//如果文件指针为空,说明打开文件失败
printf("打开文件失败!!!\n");
return;
}
while (fgets(test, Maxline, fp) != NULL) {//以行为单位读取文件
int i = 0;
if (strcmp(test, "\n") != 0)strcpy(gs_temp[ngs_temp++], test);
while (i < strlen(test)) {
char str[10] = { 0 };//开一个数组来临时保存字符
if (test[i] == '-' && test[i + 1] == '>') {//如果是箭头
i += 2;
continue;//跳过箭头
}
else if (test[i] == '|' || test[i] == ' ' || test[i] == '\n' || test[i] == '\t') {
//如果是或运算或空格或换行
i++;
continue;//也跳过
}
else if (pd_character2(test[i])) {//如果是非终结符
if (!pd_invn(test[i]))add_vn(test[i]);//放入数组
}
else {//否则就是终结符,只占一位
int thevt = 0;
while (pd_integer(test[i])) {
thevt = thevt * 10 + test[i] - '0';
i++;
}
if (!pd_invt(thevt))add_vt(thevt);
}
i++;
}
}
for (int i = 0; i < ngs_temp; i++) {
//将放入文法的换行符去掉,因为是以行为单位读取文件,所以换行符也被读进来了
if (gs_temp[i][strlen(gs_temp[i]) - 1] == '\n')
gs_temp[i][strlen(gs_temp[i]) - 1] = gs_temp[i][strlen(gs_temp[i])];
}
//下面将文法进行扩展,并放到结构体里面
for (int i = 0; i < ngs_temp; i++) {
if (strstr(gs_temp[i], "|")) {//说明有或运算,需要拆开
char str[10] = { 0 }, str2[10] = { 0 };
//str用来保存箭头的左边以及箭头,也就是公共部分
//str2用来保存箭头后面的部分,后面将str2接到后面在放进结构体的文法gs中
int j = 0, k = 0;
while (1) {//拿到前面的部分
if (gs_temp[i][j] == '-' && gs_temp[i][j + 1] == '>') {
str[k++] = gs_temp[i][j];
str[k] = gs_temp[i][j + 1];
j += 2;
break;
}
else str[k++] = gs_temp[i][j];
j++;
}
while (1) {
k = 0;
while (gs_temp[i][j] != '|') {
if (j >= strlen(gs_temp[i]))break;
str2[k++] = gs_temp[i][j++];
}
strcpy(gs.gs[gs.ngs], str);
strcat(gs.gs[gs.ngs++], str2);//进行拼接
memset(str2, 0, sizeof str2);
if (j >= strlen(gs_temp[i]))break;
j++;
}
}
else {//否则直接赋值给新的文法
strcpy(gs.gs[gs.ngs++], gs_temp[i]);//没有或(|)运算
}
}
//下面判断开始符是否有多条,有则新加一个开始符
//文法自定义,自行确保输入的文法开始符只有一个即可
//然后这里对终结符进行一个简单的排序,主要是为了后面输出分析表的时候好看
for (int i = 0; i < gs.nvt; i++)
for (int j = i + 1; j < gs.nvt; j++)
if (gs.vt[i] > gs.vt[j]) swap(gs.vt[i], gs.vt[j]);
return;
}
void print_gs()//输出非终结符和扩展后的文法
{
printf("从文件读入并扩展后的文法为:\n");//输出从文件读入的文法
for (int i = 0; i < gs.ngs; i++)printf("\t%s\n", gs.gs[i]);
printf("\nVn集合:{ ");
for (int i = 0; i < gs.nvn; i++)printf("%c ", gs.vn[i]);//输出非终结符
printf("}\nVt集合:{ ");
for (int i = 0; i < gs.nvt; i++)printf("%d ", gs.vt[i]);//输出终结符
printf("}\n");
}
void print_dfa()//输出DFA
{
//输出各个项目及项目之间的联系
printf("------------------------------------------------------------------\n");
for (int i = 0; i < ni; i++) {
printf("I%d项目集:\n", i);
printf("\t-------------------------\n");
for (int j = 0; j < dfa[i].sum; j++) {
IGS g = dfa[i].gather[j];
printf("\t|\t[%s, %d]\t|\n", g.igs, g.x);
}
printf("\t-------------------------\n");
printf("\n\t与其他项目集的联系:\n");
for (int j = 0; j < dfa[i].nci; j++)
printf("\t\t<%c,I%d>\n", dfa[i].nextci[j].first, dfa[i].nextci[j].second);
for (int j = 0; j < dfa[i].npii; j++)
printf("\t\t<%d,I%d>\n", dfa[i].nextpii[j].first, dfa[i].nextpii[j].second);
}
printf("------------------------------------------------------------------\n");
}
void print_table()//输出分析表
{
printf("\n由DFA构建的LR(1)分析表如下:\n");
printf("----------------------------------------------------------------------------------\n");
add_vt(81);//将#号暂时放到终极符的数组里
printf("状态\tACTION");
for (int i = 0; i < gs.nvt; i++)printf("\t");
printf("GOTO\n");
printf("----------------------------------------------------------------------------------\n\t");
for (int i = 0; i < gs.nvt; i++) printf("%d\t", gs.vt[i]);//action
for (int i = 1; i < gs.nvn; i++) printf("%c\t", gs.vn[i]);//goto
printf("\n----------------------------------------------------------------------------------\n");
for (int i = 0; i < ni; i++) {
printf("%d\t", i);
for (int j = 0; j < gs.nvt; j++) {//遍历终结符
for (int k = 0; k < table[i].npii; k++) {
if (gs.vt[j] == table[i].pii[k].first) {
if (table[i].pii[k].second == 666) printf("acc");
else {
if (dfa[i].nci != 0 || dfa[i].npii != 0) printf("S%d", table[i].pii[k].second);//有移进就移进
else printf("r%d", table[i].pii[k].second);//没有移进就归约
}
}
}
printf("\t");
}
for (int j = 1; j < gs.nvn; j++) {//接着遍历非终结符,要去掉新加的S',所以从1开始
for (int k = 0; k < table[i].nci; k++) {
if (gs.vn[j] == table[i].ci[k].first) {
printf("%d", table[i].ci[k].second);
}
}
printf("\t");
}
printf("\n");
printf("----------------------------------------------------------------------------------\n");
}
}
void print_stack(stack<int> ss)//将堆栈中的元素输出(要倒过来输出)
{
int nss[200] = { 0 };
int k = 0;
while (ss.size()) {
nss[k++] = ss.top();
ss.pop();
}
for (int i = k - 1; i >= 0; i--)
if (nss[i] >= 97) printf("%c ", nss[i] - 32);//说明是要输出非终结符
else printf("%d ", nss[i]);
printf("\n");
}
void analysis_table()//生成分析表
{
for (int i = 0; i < ni; i++) {//遍历所有项目集
table[i].i = i;//获取当前的状态即当前项目集编号
if (dfa[i].nci != 0 || dfa[i].npii != 0) {//遍历当前项目集的所有联系
for (int j = 0; j < dfa[i].nci; j++) {//如果联系是非终结符
table[i].ci[table[i].nci].first = dfa[i].nextci[j].first;
table[i].ci[table[i].nci++].second = dfa[i].nextci[j].second;
}
for (int j = 0; j < dfa[i].npii; j++) {//否则就是终结符
table[i].pii[table[i].npii].first = dfa[i].nextpii[j].first;
table[i].pii[table[i].npii++].second = dfa[i].nextpii[j].second;
}
}
else {//没有下一个项目那就进行归约
for (int j = 0; j < dfa[i].sum; j++) {//遍历该项目下的所有规则
int k = get_rule(dfa[i].gather[j].igs);//找到该规则在文法中的位置
table[i].pii[table[i].npii].first = dfa[i].gather[j].x;//将该规则的向前搜索符获取
//如果k是1,说明是文法第一条规则,进行归约的时候要显示成功
if (k == 1) table[i].pii[table[i].npii++].second = 666;//用666表示acc
else table[i].pii[table[i].npii++].second = k;
}
}
}
}
void input_analysis()//进行输入并进行分析
{
int n = nsp, s[N] = { 0 };
for (int i = 0; i < n; i++)s[i] = the_spcode[i];
s[n++] = 81;//补充#号的种别码
stack<int> stack_state;//状态栈
stack<int> stack_symbol;//符号栈
printf("\n对输入串进行分析:\n");
/*printf("------------------------------------------------------------------------------------\n");
printf("步骤\t状态栈\t\t符号栈\t\t输入串\t\t\t产生式\t\tACTION\tGOTO\t\n");
printf("------------------------------------------------------------------------------------\n");*/
int step = 0, i = 0;
stack_state.push(0);//先将状态0入栈
stack_symbol.push(81);//先将#的种别码入栈
int np;//用来接收移进或归约的数字
while (i < n) {
printf("------------------------------------------------------------------------------------\n");
printf("\t步骤%d\n", step);//输出步骤
printf("状态栈:\t"); print_stack(stack_state);//输出状态栈
printf("符号栈:\t"); print_stack(stack_symbol);//输出符号栈
printf("输入串:\t");
for (int j = i; j < n; j++)printf("%d ", s[j]);//输出当前的输入串
printf("\n");
int k = stack_state.top();//取出状态栈的栈顶元素
//在分析表中找到对应的位置
for (int j = 0; j < table[k].npii; j++) {//输入栈里的元素都是终结符,所以遍历终结符action
if (table[k].pii[j].first == s[i]) {//找到对应的位置
np = table[k].pii[j].second;
break;
}
}
if (np == 666) {//说明是acc,成功接收
printf("action:\tacc\n");
break;//退出while循环
}
//下面这输出产生式以及后面的action和goto
if (dfa[k].nci != 0 || dfa[k].npii != 0) {//说明是移进
printf("动作:\t移进\n");
printf("产生式:\tNULL\n");//占一个产生式的位置
printf("action:\t"); printf("S%d\n", np);//输出action
printf("goto:\tNULL\n");
stack_state.push(np);//将下一个状态入栈
stack_symbol.push(s[i]);//将当前输入入栈
i++;
}
else {//否则就是进行归约
printf("动作:\t归约\n");
printf("产生式:\t"); printf("%s\n", gs.gs[np - 1]);//输出产生式,偏移量是-1
printf("action:\t"); printf("r%d\n", np);//输出action
//计算箭头后面的字符长度
int l = get_leftnumber(gs.gs[np - 1]), l2 = l;
while (l--)stack_state.pop();//将对应个数的状态栈元素弹出
while (l2--)stack_symbol.pop();//将对应个数的符号栈元素弹出
//然后接下来要找到对应的goto元素
int kt = 0;
kt = stack_state.top();
char temp[3] = { 0 };
temp[0] = gs.gs[np - 1][0];//取出头部
int n_goto;//作为goto的值
for (int j = 0; j < table[kt].nci; j++) {//遍历
if (temp[0] == table[kt].ci[j].first) {
n_goto = table[kt].ci[j].second;
break;
}
}
stack_state.push(n_goto);//将goto值入栈
stack_symbol.push(int(temp[0]) + 32);//将非终结符入栈
printf("goto:\t"); printf("%d\n", n_goto);//输出goto的值
}
printf("\n");//进行换行
step++;//以此循环结束,步骤+1
}
printf("\n------------------------------------------------------------------------------------\n");
}
char* spcode_to_character(int n, char s[])//将种别码转换为字符串返回,仅适合关键字、界符和运算符
{
memset(s, 0, sizeof s);
if (n >= 1 && n <= nk) strcpy(s, keyword[n - 1]);
else if (n >= cc && n < cd) strcpy(s, delimiter[n - nk - 1]);
else if (n >= cd && n < ci) strcpy(s, calculation[n - cd]);
return s;
}程序运行结果
将输出文法、项目集和分析表的代码注释了,只输出分析结果,因为输入串太长,所以换成了横着来输出。可以看到,最后的结果acc,也就是成功或接收了。
测试的文法(test.txt文件的内容):
P->A
A->BCH
A->BCD
A->BCG
B->39
C->86 56 87 78 C
C->86 56 87 79
D->17 71 E 72 H
D->17 71 E 72 G
D->17 71 E 72 F
G->34 71 E 72 F
G->34 71 E 72 H
G->34 71 E 72 D
E->86 I 87
F->86 56 87 79
F->86 56 86 J
H->15 71 B 86 56 87 79 E 79 86 45 72 75 D 76
H->15 71 B 86 56 87 79 E 79 86 45 72 D
H->15 71 B 86 56 87 79 E 79 86 45 72 75 H 76
H->15 71 B 86 56 87 79 E 79 86 45 72 H
H->15 71 B 86 56 87 79 E 79 86 45 72 75 G 76
H->15 71 B 86 56 87 79 E 79 86 45 72 G
H->15 71 B 86 56 87 79 E 79 86 45 72 F
I->50|47
J->40 87 J
J->40 86 J
J->40 87 79
J->40 86 79
测试的代码(test1.txt文件中的内容)(int36是要求自定义的一种类型,具体看词法分析器那篇文章):
int36 a=A7,b=5TU,z=0;
for(int36 i=0;i<5T;i++)
if(a==10)
z=z+1+2+a+4;


结语
因为程序有点复杂,很多地方也进行了注释了,所以就不解释太多了。文章来源:https://www.toymoban.com/news/detail-470598.html
写的废话有点多了,不管了我累了毁灭吧。文章来源地址https://www.toymoban.com/news/detail-470598.html
到了这里,关于编译原理语法分析器(C/C++)(LR1文法)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!