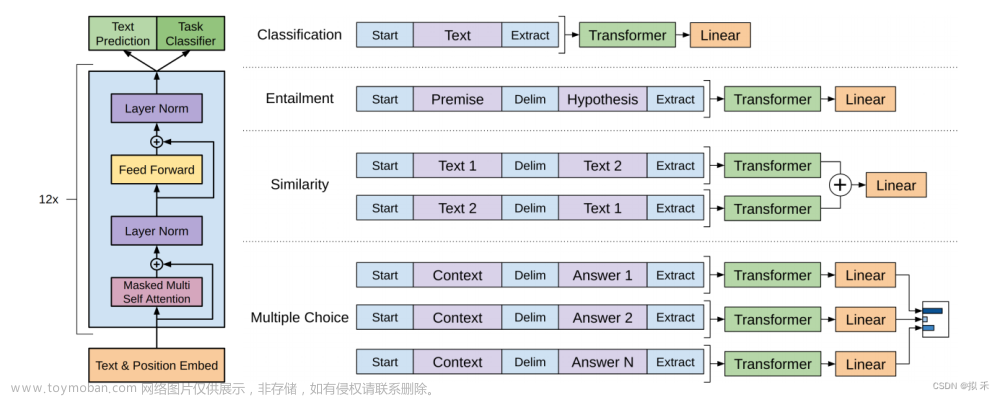
tidyverse 译 “洁净的宇宙” => “极乐净土”
以 iris 鸢尾花数据集为例
** 查看数据集**

** 查看维度dimention**
dim(iris)

iris 数据集有150个对象(observation),5列 ( Sepal.Length , Sepal.Width , Petal.Length , Petal.Width , Species )
数据太多,只想看一部分可以用 head 和 tail ,默认展示 6 个 observations
head(iris)
tail(iris)


想展示12行,设定展示的行数为12即可
head(iris,12)
tail(iris,12)


** 取 行 数据**
iris[1,] # 取第一行
iris[1:3,] # 取前三行

取 列 数据
iris[,1] # 取第一列全部150个数据
iris$Sepal.Length # 可以直接读取Sepal.Length列


在这里引入管道 pipe(%>%)
pipe 快捷键:
Windows: ctrl+shift+m
Mac: cmd+shift+m
(个人感觉将默认的pipe符号%>%设置为|>更方便)
设置如下:
在菜单栏中,选择 “Tools”(工具)。
在下拉菜单中,选择 “Global Options”(全局选项)。
在弹出的对话框中,选择 “Code”(代码)选项卡。
“Editing”(编辑)选项卡,勾选 Use Native Pipe operator|>。
单击 “Apply”,“OK”(确定)以保存更改。
添加 id 列

删除列
iris[,-6] # 删除掉第 6 列,即刚刚创建的 id 列

条件查询 行
subset , filter
#方法1
iris1 = iris |>
+ subset(Sepal.Length > 6.9 & Sepal.Width > 3.2)
# 查看iris1
iris1
#方法2
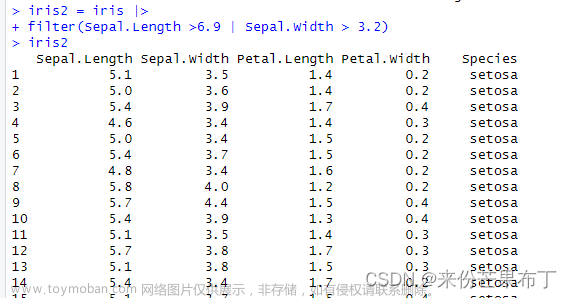
iris2 = iris |>
+ filter(Sepal.Length > 6.9 & Sepal.Width > 3.2)
# 查看iris2
iris2

subset 显示的是原来的 id, filter 显示的是筛选之后新的 id
subset 和 filter 的并集都用 |
条件查询 列
select
iris3 = iris |>
+ select(Sepal.Length , Sepal.Width)
# 查看
iris3

select 也可以删除某列
重命名 rename

pipe 的好处: 可以一次性处理多个任务,不用累赘的嵌套 iris1 , iris2…
iris_final = iris |>
+ rename(S.L = Sepal.Length , S.W = Sepal.Width) |>
+ mutate(id = row_number()) |>
+ filter(S.L > 6 & S.W >3) |>
+ select(S.L, S.W, Species)
iris_final

分组 group_by
iris1 = iris |>
group_by(Species) |>
summarise(PL_mean = mean(Petal.Length), PW_mean = mean(Petal.Width))
iris1
iris2 = iris |>
group_by(Species) |>
mutate(PL_mean = mean(Petal.Length), PW_mean = mean(Petal.Width)) |>
ungroup()
iris2
不想改变原来的数据集结构,可以用mutate加上新的一列, 一般mutate之后会加一个ungroup取消分组,方便后续继续对数据集进行操作

排序 arrange
iris3 = iris |>
arrange(Petal.Length, desc(Petal.Width)) # 根据前后优先级,先按 Petal.length 升序拍,当 Petal.length一样时,按 Petal.width 降序排序
head(iris3,10)

根据类别给新列赋值
iris4 = iris |>
mutate(Species.new = recode(Species, setosa = 1, versicolor = 2, virginica = 3))
head(iris4, 10)
table(iris4$Species) # 用 table 察看可以快速看出有没有赋值错误
table(iris4$Species.new)

用 if_else 也能实现 recode 的效果 if_else(if, then, else)
iris5 = iris |>
mutate(Species.new = if_else(Species == "setosa", 1,if_else(Species == "versicolor",2,3)))
head(iris5, 10)
table(iris5$Species)
table(iris5$Species.new)

去重,按 Species 给每个类别只保留一条数据
iris6 = iris |>
distinct(Species, .keep_all = TRUE)
iris6
最后只有三朵花,每个类别只有一朵,保留的是每个类别第一次出现的那条数据
由于 distinct 保留第一次出现的数据, 所以经常与 arrange 一起使用,先排序再保留一个文章来源:https://www.toymoban.com/news/detail-471138.html
iris7 = iris |>
arrange(Petal.Width) |>
distinct(Species, .keep_all = TRUE)
iris7
 文章来源地址https://www.toymoban.com/news/detail-471138.html
文章来源地址https://www.toymoban.com/news/detail-471138.html
到了这里,关于R语言 tidyverse系列学习笔记(系列1)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!