1. 前言
1.1. 为什么要进行自监督学习
我们知道,标注数据总是有限的,就算ImageNet已经很大,但是很难更大,那么它的天花板就摆在那,就是有限的数据总量。NLP领域目前的经验应该是:自监督预训练使用的数据量越大,模型越复杂,那么模型能够吸收的知识越多,对下游任务效果来说越好。这可能是自从Bert出现以来,一再被反复证明的真理,如果它不是唯一的真理,那也肯定是最大的真理。图像领域如果技术想要有质的提升,可能也必须得走这条路,就是充分使用越来越大量的无标注数据,使用越来越复杂的模型,采用自监督预训练模式,来从中吸取图像本身的先验知识分布,在下游任务中通过Fine-tuning,来把预训练过程习得的知识,迁移给并提升下游任务的效果。
1.2. 什么是自监督学习
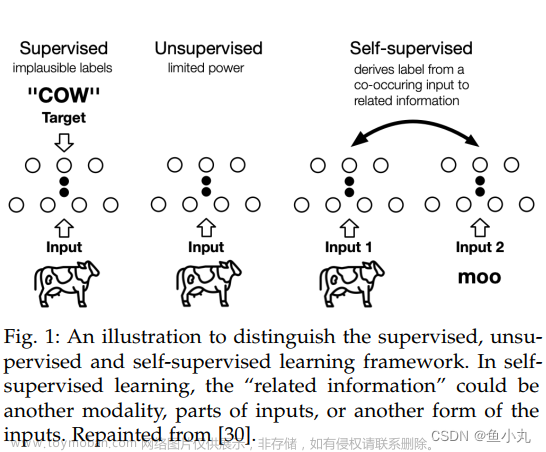
利用代理任务(pretext task)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。
1.3. 自监督学习分类
- 生成式的方法(Generative Methods) :这类方法以自编码器为代表,主要关注pixel label的loss。即在自编码器中对数据样本编码成特征再解码重构,这类型的任务难度相对比较高,要求像素级的重构,中间的图像编码必须包含很多细节信息举例来说,这里认为重构的效果比较好则说明模型学到了比较好的特征表达,而重构的效果通过pixel label的loss来衡量。如VAE、GAN。

- 对比式的方法(Contrastive Learning):也称判别式的方法,通过自动构造相似实例和不相似实例,要求习得一个表示学习模型,通过这个模型,使得相似的实例在投影空间中比较接近,而不相似的实例在投影空间中距离比较远。而如何构造相似实例,以及不相似实例,如何构造能够遵循上述指导原则的表示学习模型结构,以及如何防止模型坍塌(Model Collapse),这几个点是其中的关键。如对比学习。

2.对比学习(Contrastive Learning)
2.1. 什么是对比学习
对比学习有的paper中称之为自监督学习,有的paper称之为无监督学习,自监督学习是无监督学习的一种形式,现有的文献中没有正式的对两者进行区分定义,这两种称呼都可以用。



上面有三张图,图1和图2是🐶,图3是🐱。对于有监督学习的分类问题,我们希望分类模型识别出来图1和图2都是🐶,图3是🐱。但对于无监督的对比学习来说,我们希望模型能识别出图1和图2是一个类别,图3与图1图2不是一个类别,也就是说,对比学习不需要知道图1图2是🐶以及图3是🐱,即对比学习不需要知道每张图的真实标签,只需要知道到谁与谁相似,谁与谁不相似。假设三张图都通过一个网络,得到三张图片对应的特征f1、f2、f3,我们希望对比学习可以做到在特征空间中把f1和f2拉进,且远离f3。也就是说,对比学习要达到的目标是所有相似的物体在特征空间相邻的区域,而不相似的物体都在不相邻的区域。
上面说到,对比学习需要知道谁与谁相似,谁与谁不相似,那言外之意就是,对比学习不还得需要标签信息去做有监督学习吗?对比学习之所以被认为是一种无监督的训练方式,是因为人们可以使用代理任务(pretext task)来定义谁与谁相似,谁与谁不相似,代理任务通常是人为设定的一些规则,这些规则定义了哪张图与哪张图相似,哪张图与哪张图不相似,从而提供了一个监督信号去训练模型,这就是所谓的自监督。
2.2. 对比学习的范式是什么
对比学习的典型范式就是:代理任务+目标函数。代理任务和目标函数也是对比学习与有监督学习最大的区别。回忆一下有监督学习的流程,输入x,通过模型输出得到y,输出的y和真实label(ground truth)通过目标函数计算损失,以此进行模型训练。而对于无监督学习或自监督学习来说,是没有ground truth的,那怎么办呢?代理任务就是来解决这个问题的,我们用代理任务来定义对比学习的正负样本,无监督学习一旦有了输出y和label,就可以通过一个目标函数来计算两者的损失从而指导模型的学习方向。
2.3. 代理任务
下面简单介绍几个对比学习常用的代理任务。
2.3.1.个体判别
InstDist提出了个体判别这个代理任务。作者是受到有监督学习的启发,比如将一张豹子的图片输入到一个有监督数据训练的分类器中,排名前几的都是和豹子相关的,比如美洲豹、雪豹,而靠后的都是毫不相关的。作者认为这些图片聚集在一起的原因,并不是因为给了它们相似的语义标签,而是这些图片在视觉上非常相似。因此,作者把这种按类别的有监督任务发挥到极致,提出了个体判别任务,把每张图片都看作一个类别,希望模型可以学习到图片的表征,从而把图片都区分开来。
对于对比学习来说,正样本一般是通过数据增强的方式得到的,负样本是同batch中的其它样本及数据增强后的图片或者memory bank中的样本。

2.3.2. 序列预测
序列预测属于生成式的代理任务,是在CPC中提出来的。假设有一个输入序列 x,将t-3,t-2,t-1,t 时刻z的值输入到编码器,再将编码后的特征输入给自回归模型 Gar ,得到上下文表示ct 。如果上下文表示足够好,包含了之前及现在的所有信息,它应该可以用来预测未来时刻的特征,这个预测的特征就可以当做query。未来时刻的输入编码后的特征作为正样本, 负样本的定义比较广泛,可以用任意输入编码之后的特征。

2.3.3. 多模态多视角
多模态多视角的任务在CMC中提出的,主要思想是一个物体的很多视角都可以被作为正样本。人在观察物体时,会综合视觉、听觉等多个视角的信号,这些视角可能是不完整且带有噪声的,但最重要的信息是在所有视角中共享的。CMC的目标就是通过增大不同视角之间的互信息,学习到视角不变的特征。所以这里正样本来自同一图片的不同视角,负样本是其它不同的任意视角。

2.4. 目标函数
在通过代理任务确定了正负样本之后,我们需要给模型信号,激励他们拉近正样例间的距离,拉远负样例间的距离,这就要通过设计对比损失来完成。
2.4.1. 原始对比损失

2.4.2. 三元组损失(triplet loss)

2.4.3. InfoNCE(Noise Contrastive Estimation)
 文章来源:https://www.toymoban.com/news/detail-471449.html
文章来源:https://www.toymoban.com/news/detail-471449.html
参考:
https://zhuanlan.zhihu.com/p/471018370
https://zhuanlan.zhihu.com/p/367290573
https://zhuanlan.zhihu.com/p/491996973
https://blog.csdn.net/weixin_43869415/article/details/120678146文章来源地址https://www.toymoban.com/news/detail-471449.html
到了这里,关于【自监督学习】对比学习(Contrastive Learning)介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!