https://dblab.xmu.edu.cn/post/8116/
问题
问题1 mysql登录需要密码
https://cloud.tencent.com/developer/beta/article/1142525
这个很神奇,我密码输1就进去了
为避免出问题,把解决方案放这里:
https://blog.csdn.net/qq_34771403/article/details/73927962

sudo cat /etc/mysql/debian.cnf

mysql -u debian-sys-maint -p
#密码wK9rLP0T1LtA0L08
mysql -u debian-sys-maint -wK9rLP0T1LtA0L08



alter user 'root'@'localhost' identified by '123456';

问题2 sqoop测试与mysql连接报错

https://blog.csdn.net/weixin_47580081/article/details/115472841
https://blog.csdn.net/Jing0921/article/details/109164378

解决问题1就完成了解决了问题2

问题3 Warning: /usr/local/sqoop/…/zookeeper does not exist! Accumulo imports will fail
问题4

解决方法:使用命令行
问题5 启动hive出现 ls: 无法访问/opt/module/spark/lib/spark-assembly-*.jar: 没有那个文件或目录


问题6 ./bin/hive: 行 116: /usr/local/spark/jars/aircompressor-0.10.jar: 权限不够

这个是由问题5改正而来的错误,
cd /usr/local/hive/bin
vi hive
把sparkAssemblyPath=`ls ${SPARK_HOME}lib/spark-assembly-*.jar`
修改为
sparkAssemblyPath=`ls ${SPARK_HOME}/jars/*.jar`
修改加上引号就可以了。
完成之后只有问题7的报错。
问题7 Cannot find hadoop installation: $HADOOP_HOME or $HADOOP_PREFIX must be set or hadoop must be in the path
https://blog.csdn.net/Victory_Lei/article/details/82469794
问题解决
问题8 Exception in thread “main” java.lang.ExceptionInInitializerError
Exception in thread “main” java.lang.ExceptionInInitializerError at
org.apache.hadoop.hive.common.LogUtils.initHiveLog4j(LogUtils.java:58)

https://blog.csdn.net/qq_45044615/article/details/120873502
hive 启动时出现 java.lang.ExceptionInInitializerError
原因:安装的hive版本与hadoop版本不兼容
我当时安装的hadoop版本是3.1.3,然后找的hive版本是2.7.2,后来换成了hive3.1.2就好了
具体的hive和hadoop兼容关系可以看: https://hive.apache.org/downloads.html.
问题9 Job for mysql.service failed because the control process exited with error code.
See “systemctl status mysql.service” and “journalctl -xe” for details.
解决方法:
问题10
https://blog.csdn.net/qq_28790663/article/details/90640843
sqoop list-databases --connect jdbc:mysql://192.168.46.129:3306/ --username root -P
sqoop list-databases -connect jdbc:mysql://localhost:3306/ -username root -password 123456

环境配置
mysql的安装
sudo apt-get update #更新软件源
sudo apt-get install mysql-server #安装mysql
上述命令会安装以下包:
apparmor
mysql-client-5.7
mysql-common
mysql-server
mysql-server-5.7
mysql-server-core-5.7
因此无需再安装mysql-client等。安装过程会提示设置mysql root用户的密码,设置完成后等待自动安装即可。默认安装完成就启动了mysql。
启动和关闭mysql服务器:
service mysql start
service mysql stop
确认是否启动成功,mysql节点处于LISTEN状态表示启动成功:
sudo netstat -tap | grep mysql

解决利用sqoop导入MySQL中文乱码的问题(可以插入中文,但不能用sqoop导入中文)
导致导入时中文乱码的原因是character_set_server默认设置是latin1。
在[mysqld]下添加一行character_set_server=utf8。如下图
(3)重启MySQL服务。service mysql restart
(4)登陆MySQL,并查看MySQL目前设置的编码。show variables like “char%”;

Sqoop的安装

cd ~ #进入当前用户的用户目录
cd 下载 #sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz文件下载后就被保存在该目录下面
sudo tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /usr/local #解压安装文件
cd /usr/local
sudo mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop #修改文件名
sudo chown -R hadoop:hadoop sqoop #修改文件夹属主,如果你当前登录用户名不是hadoop,请修改成你自己的用户名

cd sqoop/conf/
cat sqoop-env-template.sh >> sqoop-env.sh #将sqoop-env-template.sh复制一份并命名为sqoop-env.sh
vim sqoop-env.sh #编辑sqoop-env.sh

修改sqoop-env.sh的如下信息
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop
export HBASE_HOME=/usr/local/hbase
export HIVE_HOME=/usr/local/hive
#export ZOOCFGDIR= #如果读者配置了ZooKeeper,也需要在此配置ZooKeeper的路径


配置环境变量
打开当前用户的环境变量配置文件:
vim ~/.bashrc
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SBT_HOME/bin:$SQOOP_HOME/bin
export CLASSPATH=$CLASSPATH:$SQOOP_HOME/lib
保存该文件,退出vim编辑器。
然后,执行下面命令让配置文件立即生效:
source ~/.bashrc
将mysql驱动包拷贝到 S Q O O P H O M E / l i b 下面要把 M y S Q L 驱动程序拷贝到 SQOOP_HOME/lib 下面要把MySQL驱动程序拷贝到 SQOOPHOME/lib下面要把MySQL驱动程序拷贝到SQOOP_HOME/lib目录下,首先请在Linux系统的浏览器中请点击mysql驱动包下载地址下载驱动包。下载后,一般文件会被浏览器默认放置在当前用户的下载目录下,本教程采用hadoop用户登录Linux系统,因此,下载文件被默认放置在“/home/hadoop/下载”目录下面。

下面执行命令拷贝文件:
cd ~/下载 #切换到下载路径,如果你下载的文件不在这个目录下,请切换到下载文件所保存的目录
sudo tar -zxvf mysql-connector-java-5.1.40.tar.gz #解压mysql驱动包
ls #这时就可以看到解压缩后得到的目录mysql-connector-java-5.1.40
cp ./mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/sqoop/lib

测试与MySQL的连接
首先请确保mysql服务已经启动了,如果没有启动,请执行下面命令启动:
service mysql start
然后就可以测试sqoop与MySQL之间的连接是否成功:
sqoop list-databases --connect jdbc:mysql://127.0.0.1:3306/ --username root -P
mysql的数据库列表显示在屏幕上表示连接成功,如下图:
Hive的安装
下载并解压hive源程序
sudo tar -zxvf ./apache-hive-1.2.2-bin.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv apache-hive-1.2.2-bin hive # 将文件夹名改为hive
sudo chown -R hadoop:hadoop hive # 修改文件权限

配置环境变量
为了方便使用,我们把hive命令加入到环境变量中去,
请使用vim编辑器打开.bashrc文件,命令如下:
vim ~/.bashrc
在该文件最前面一行添加如下内容:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export HADOOP_HOME=/usr/local/hadoop

HADOOP_HOME需要被配置成你机器上Hadoop的安装路径,比如这里是安装在/usr/local./hadoop目录。
保存退出后,运行如下命令使配置立即生效:
source ~/.bashrc
修改/usr/local/hive/conf下的hive-site.xml
执行如下命令:
cd /usr/local/hive/conf
mv hive-default.xml.template hive-default.xml
上面命令是将hive-default.xml.template重命名为hive-default.xml;
然后,使用vim编辑器新建一个配置文件hive-site.xml,命令如下:
cd /usr/local/hive/conf
vim hive-site.xml
在hive-site.xml中添加如下配置信息:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>

然后,按键盘上的“ESC”键退出vim编辑状态,再输入:wq,保存并退出vim编辑器。
安装并配置mysql
下载mysql jdbc 包
tar -zxvf mysql-connector-java-5.1.40.tar.gz #解压
cp mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/hive/lib #将mysql-connector-java-5.1.40-bin.jar拷贝到/usr/local/hive/lib目录下
启动并登陆mysql shell
service mysql start #启动mysql服务
mysql -u root -p #登陆shell界面
新建hive数据库。
mysql> create database hive; #这个hive数据库与hive-site.xml中localhost:3306/hive的hive对应,用来保存hive元数据
配置mysql允许hive接入:
mysql> grant all on *.* to hive@localhost identified by 'hive'; #将所有数据库的所有表的所有权限赋给hive用户,后面的hive是配置hive-site.xml中配置的连接密码
mysql> flush privileges; #刷新mysql系统权限关系表

start-all.sh #启动hadoop
hive #启动hive
进度:https://dblab.xmu.edu.cn/blog/1080/
重装hive 改为hive3.1.2
sudo tar -zxvf ./apache-hive-3.1.2-bin.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv apache-hive-3.1.2-bin hive # 将文件夹名改为hive
sudo chown -R hadoop:hadoop hive # 修改文件权限

步骤一:本地数据集上传到数据仓库Hive
实验数据集的下载
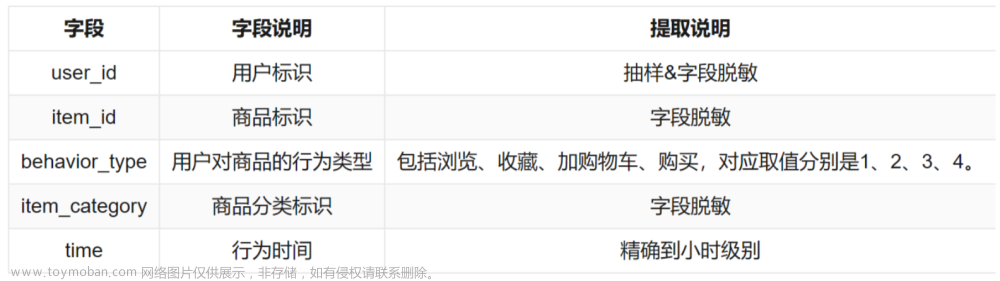
用户行为日志user_log.csv,日志中的字段定义如下:
- user_id | 买家id
- item_id | 商品id
- cat_id | 商品类别id
- merchant_id | 卖家id
- brand_id | 品牌id
- month | 交易时间:月
- day | 交易事件:日
- action | 行为,取值范围{0,1,2,3},0表示点击,1表示加入购物车,2表示购买,3表示关注商品
- age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
- gender | 性别:0表示女性,1表示男性,2和NULL表示未知
- province| 收获地址省份
回头客训练集train.csv和回头客测试集test.csv,训练集和测试集拥有相同的字段,字段定义如下:
user_id | 买家id
age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
gender | 性别:0表示女性,1表示男性,2和NULL表示未知
merchant_id | 商家id
label | 是否是回头客,0值表示不是回头客,1值表示回头客,-1值表示该用户已经超出我们所需要考虑的预测范围。NULL值只存在测试集,在测试集中表示需要预测的值。
cd /home/hadoop/下载
ls
cd /usr/local
ls
sudo mkdir dbtaobao
//这里会提示你输入当前用户(本教程是hadoop用户名)的密码
//下面给hadoop用户赋予针对dbtaobao目录的各种操作权限
sudo chown -R hadoop:hadoop ./dbtaobao
cd dbtaobao
//下面创建一个dataset目录,用于保存数据集
mkdir dataset
//下面就可以解压缩data_format.zip文件
cd ~ //表示进入hadoop用户的目录
cd 下载
ls
unzip data_format.zip -d /usr/local/dbtaobao/dataset
cd /usr/local/dbtaobao/dataset
ls

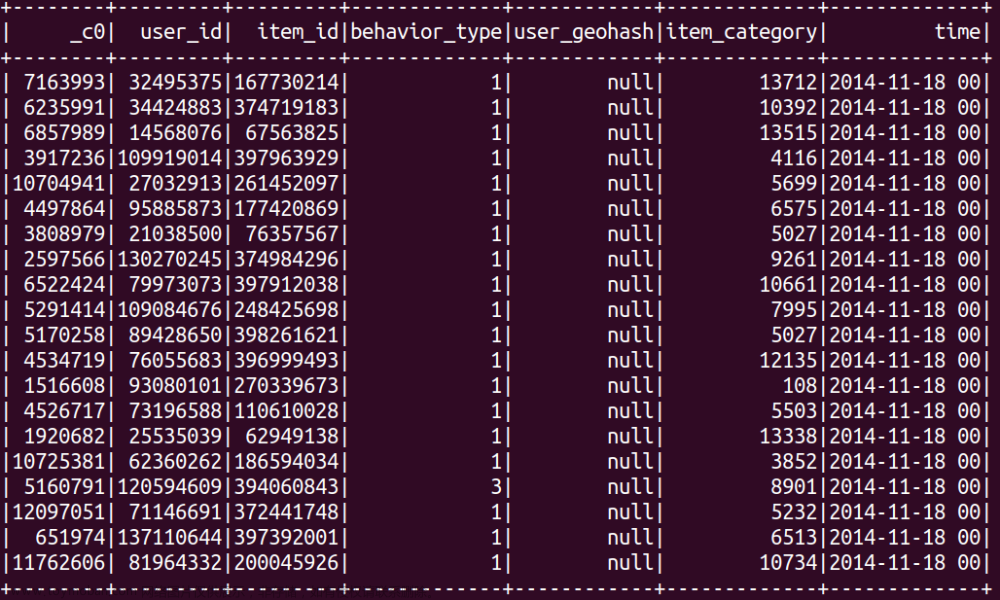
我们执行下面命令取出user_log.csv前面5条记录看一下
执行如下命令:
head -5 user_log.csv
可以看到,前5行记录如下:
数据集的预处理
1.删除文件第一行记录,即字段名称
user_log.csv的第一行都是字段名称,我们在文件中的数据导入到数据仓库Hive中时,不需要第一行字段名称,因此,这里在做数据预处理时,删除第一行
cd /usr/local/dbtaobao/dataset
//下面删除user_log.csv中的第1行
sed -i '1d' user_log.csv //1d表示删除第1行,同理,3d表示删除第3行,nd表示删除第n行
//下面再用head命令去查看文件的前5行记录,就看不到字段名称这一行了
head -5 user_log.csv

2.获取数据集中双11的前100000条数据
由于数据集中交易数据太大,这里只截取数据集中在双11的前10000条交易数据作为小数据集small_user_log.csv
下面我们建立一个脚本文件完成上面截取任务,请把这个脚本文件放在dataset目录下和数据集user_log.csv:
cd /usr/local/dbtaobao/dataset
vim predeal.sh
上面使用vim编辑器新建了一个predeal.sh脚本文件,请在这个脚本文件中加入下面代码:
#!/bin/bash
#下面设置输入文件,把用户执行predeal.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($6==11 && $7==11){
id=id+1;
print $1","$2","$3","$4","$5","$6","$7","$8","$9","$10","$11
if(id==10000){
exit
}
}
}' $infile > $outfile
下面就可以执行predeal.sh脚本文件,截取数据集中在双11的前10000条交易数据作为小数据集small_user_log.csv,命令如下:
chmod +x ./predeal.sh
./predeal.sh ./user_log.csv ./small_user_log.csv

3.导入数据库
下面要把small_user_log.csv中的数据最终导入到数据仓库Hive中。为了完成这个操作,我们会首先把这个文件上传到分布式文件系统HDFS中,然后,在Hive中创建两个个外部表,完成数据的导入。
启动HDFS
cd /usr/local/hadoop
./sbin/start-dfs.sh
然后,执行jps命令看一下当前运行的进程:
jps

把user_log.csv上传到HDFS中
现在,我们要把Linux本地文件系统中的user_log.csv上传到分布式文件系统HDFS中,存放在HDFS中的“/dbtaobao/dataset”目录下。
首先,请执行下面命令,在HDFS的根目录下面创建一个新的目录dbtaobao,并在这个目录下创建一个子目录dataset,如下:
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /dbtaobao/dataset/user_log
然后,把Linux本地文件系统中的small_user_log.csv上传到分布式文件系统HDFS的“/dbtaobao/dataset”目录下,命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -put /usr/local/dbtaobao/dataset/small_user_log.csv /dbtaobao/dataset/user_log
下面可以查看一下HDFS中的small_user_log.csv的前10条记录,命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -cat /dbtaobao/dataset/user_log/small_user_log.csv | head -10

在Hive上创建数据库
首先启动MySQL数据库:
service mysql start #可以在Linux的任何目录下执行该命令
由于Hive是基于Hadoop的数据仓库,使用HiveQL语言撰写的查询语句,最终都会被Hive自动解析成MapReduce任务由Hadoop去具体执行,因此,需要启动Hadoop,然后再启动Hive。由于前面我们已经启动了Hadoop,所以,这里不需要再次启动Hadoop。下面,在这个新的终端中执行下面命令进入Hive:
cd /usr/local/hive
./bin/hive # 启动Hive
启动成功以后,就进入了“hive>”命令提示符状态,可以输入类似SQL语句的HiveQL语句。
下面,我们要在Hive中创建一个数据库dbtaobao,命令如下:
hive> create database dbtaobao;
hive> use dbtaobao;
创建外部表
这里我们要分别在数据库dbtaobao中创建一个外部表user_log,它包含字段(user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province),请在hive命令提示符下输入如下命令:
hive> CREATE EXTERNAL TABLE dbtaobao.user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT,gender INT,province STRING) COMMENT 'Welcome to xmu dblab,Now create dbtaobao.user_log!' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '/dbtaobao/dataset/user_log';

查询数据
上面已经成功把HDFS中的“/dbtaobao/dataset/user_log”目录下的small_user_log.csv数据加载到了数据仓库Hive中,我们现在可以使用下面命令查询一下:
hive> select * from user_log limit 10;

步骤二:Hive数据分析
操作Hive
因为需要借助于MySQL保存Hive的元数据,所以,请首先启动MySQL数据库,请在终端中输入下面命令:
service mysql start # 可以在Linux的任何目录下执行该命令
由于Hive是基于Hadoop的数据仓库,使用HiveQL语言撰写的查询语句,最终都会被Hive自动解析成MapReduce任务由Hadoop去具体执行,因此,需要启动Hadoop,然后再启动Hive。
请执行下面命令启动Hadoop(如果你已经启动了Hadoop就不用再次启动了):
cd /usr/local/hadoop
./sbin/start-dfs.sh
下面,继续执行下面命令启动进入Hive:
cd /usr/local/hive
./bin/hive //启动Hive
通过上述过程,我们就完成了MySQL、Hadoop和Hive三者的启动。
启动成功以后,就进入了“hive>”命令提示符状态,可以输入类似SQL语句的HiveQL语句。
然后,在“hive>”命令提示符状态下执行下面命令
hive> use dbtaobao; -- 使用dbtaobao数据库
hive> show tables; -- 显示数据库中所有表。
hive> show create table user_log; -- 查看user_log表的各种属性;

可以执行下面命令查看表的简单结构:
hive> desc user_log;

简单查询分析
先测试一下简单的指令:
hive> select brand_id from user_log limit 10; -- 查看日志前10个交易日志的商品品牌
执行结果如下:
hive> select month,day,cat_id from user_log limit 20;
如果要查出每位用户购买商品时的多种信息,输出语句格式为 select 列1,列2,….,列n from 表名;
比如我们现在查询前20个交易日志中购买商品时的时间和商品的种类
有时我们在表中查询可以利用嵌套语句,如果列名太复杂可以设置该列的别名,以简化我们操作的难度,以下我们可以举个例子:
hive> select ul.at, ul.ci from (select action as at, cat_id as ci from user_log) as ul limit 20;

查询条数统计分析
经过简单的查询后我们同样也可以在select后加入更多的条件对表进行查询,下面可以用函数来查找我们想要的内容。
(1)用聚合函数count()计算出表内有多少条行数据
hive> select count(*) from user_log; -- 用聚合函数count()计算出表内有多少条行数据
执行结果如下:
在函数内部加上distinct,查出uid不重复的数据有多少条
下面继续执行操作:
hive> select count(distinct user_id) from user_log; -- 在函数内部加上distinct,查出user_id不重复的数据有多少条

查询不重复的数据有多少条(为了排除客户刷单情况)
hive> select count(*) from (select user_id,item_id,cat_id,merchant_id,brand_id,month,day,action from user_log group by user_id,item_id,cat_id,merchant_id,brand_id,month,day,action having count(*)=1)a;

关键字条件查询分析
1.以关键字的存在区间为条件的查询
使用where可以缩小查询分析的范围和精确度,下面用实例来测试一下。
(1)查询双11那天有多少人购买了商品
hive> select count(distinct user_id) from user_log where action='2';

关键字赋予给定值为条件,对其他数据进行分析
取给定时间和给定品牌,求当天购买的此品牌商品的数量
hive> select count(*) from user_log where action='2' and brand_id=2661;

根据用户行为分析
从现在开始,我们只给出查询语句,将不再给出执行结果。
1.查询一件商品在某天的购买比例或浏览比例
hive> select count(distinct user_id) from user_log where action='2'; -- 查询有多少用户在双11购买了商品

根据上面语句得到购买数量和点击数量,两个数相除即可得出当天该商品的购买率。
2.查询双11那天,男女买家购买商品的比例
hive> select count(*) from user_log where gender=0; --查询双11那天女性购买商品的数量
hive> select count(*) from user_log where gender=1; --查询双11那天男性购买商品的数量

上面两条语句的结果相除,就得到了要要求的比例。
3.给定购买商品的数量范围,查询某一天在该网站的购买该数量商品的用户id
hive> select user_id from user_log where action='2' group by user_id having count(action='2')>5; -- 查询某一天在该网站购买商品超过5次的用户id

用户实时查询分析
不同的品牌的浏览次数
hive> create table scan(brand_id INT,scan INT) COMMENT 'This is the search of bigdatataobao' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE; -- 创建新的数据表进行存储
hive> insert overwrite table scan select brand_id,count(action) from user_log where action='2' group by brand_id; --导入数据
hive> select * from scan; -- 显示结果

步骤三:将数据从Hive导入到MySQL
Hive预操作
然后,在“hive>”命令提示符状态下执行下面命令:
1、创建临时表inner_user_log和inner_user_info
hive> create table dbtaobao.inner_user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT,gender INT,province STRING) COMMENT 'Welcome to XMU dblab! Now create inner table inner_user_log ' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
这个命令执行完以后,Hive会自动在HDFS文件系统中创建对应的数据文件“/user/hive/warehouse/dbtaobao.db/inner_user_log”。
2、将user_log表中的数据插入到inner_user_log,
在[大数据案例-步骤一:本地数据集上传到数据仓库Hive(待续)]中,我们已经在Hive中的dbtaobao数据库中创建了一个外部表user_log。下面把dbtaobao.user_log数据插入到dbtaobao.inner_user_log表中,命令如下:
hive> INSERT OVERWRITE TABLE dbtaobao.inner_user_log select * from dbtaobao.user_log;
请执行下面命令查询上面的插入命令是否成功执行:
hive> select * from inner_user_log limit 10;

使用Sqoop将数据从Hive导入MySQL
登录 MySQL
请在Linux系统中新建一个终端,执行下面命令:
mysql –u root –p
为了简化操作,本教程直接使用root用户登录MySQL数据库,但是,在实际应用中,建议在MySQL中再另外创建一个用户。
执行上面命令以后,就进入了“mysql>”命令提示符状态。
(2)创建数据库
mysql> show databases; #显示所有数据库
mysql> create database dbtaobao; #创建dbtaobao数据库
mysql> use dbtaobao; #使用数据库

mysql> show variables like "char%";

下面在MySQL的数据库dbtaobao中创建一个新表user_log,并设置其编码为utf-8:
mysql> CREATE TABLE `dbtaobao`.`user_log` (`user_id` varchar(20),`item_id` varchar(20),`cat_id` varchar(20),`merchant_id` varchar(20),`brand_id` varchar(20), `month` varchar(6),`day` varchar(6),`action` varchar(6),`age_range` varchar(6),`gender` varchar(6),`province` varchar(10)) ENGINE=InnoDB DEFAULT CHARSET=utf8;

导入数据
注意,刚才已经退出MySQL,回到了Shell命令提示符状态。下面就可以执行数据导入操作,
cd /usr/local/sqoop
bin/sqoop export --connect jdbc:mysql://localhost:3306/dbtaobao --username root --password 123456 --table user_log --export-dir '/user/hive/warehouse/dbtaobao.db/inner_user_log' --fields-terminated-by ',';
步骤四:利用Spark预测回头客行为(python版)
预处理test.csv和train.csv数据集
这里列出test.csv和train.csv中字段的描述,字段定义如下:
user_id | 买家id
age_range | 买家年龄分段:1表示年龄小于18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄大于等于50,0和NULL则表示未知
gender | 性别:0表示女性,1表示男性,2和NULL表示未知
merchant_id | 商家id
label | 是否是回头客,0值表示不是回头客,1值表示回头客,-1值表示该用户已经超出我们所需要考虑的预测范围。NULL值只存在测试集,在测试集中表示需要预测的值。
这里需要预先处理test.csv数据集,把这test.csv数据集里label字段表示-1值剔除掉,保留需要预测的数据.并假设需要预测的数据中label字段均为1.
cd /usr/local/dbtaobao/dataset
vim predeal_test.sh
上面使用vim编辑器新建了一个predeal_test.sh脚本文件,请在这个脚本文件中加入下面代码:
#!/bin/bash
#下面设置输入文件,把用户执行predeal_test.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal_test.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && !$5){
id=id+1;
print $1","$2","$3","$4","1
if(id==10000){
exit
}
}
}' $infile > $outfile

下面就可以执行predeal_test.sh脚本文件,截取测试数据集需要预测的数据到test_after.csv,命令如下:
chmod +x ./predeal_test.sh
./predeal_test.sh ./test.csv ./test_after.csv
train.csv的第一行都是字段名称,不需要第一行字段名称,这里在对train.csv做数据预处理时,删除第一行
sed -i '1d' train.csv
然后剔除掉train.csv中字段值部分字段值为空的数据。
cd /usr/local/dbtaobao/dataset
vim predeal_train.sh

上面使用vim编辑器#新建了一个predeal_train.sh脚本文件,请在这个脚本文件中加入下面代码:
#!/bin/bash
#下面设置输入文件,把用户执行predeal_train.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal_train.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && ($5!=-1)){
id=id+1;
print $1","$2","$3","$4","$5
if(id==10000){
exit
}
}
}' $infile > $outfile

下面就可以执行predeal_train.sh脚本文件,截取测试数据集需要预测的数据到train_after.csv,命令如下:
chmod +x ./predeal_train.sh
./predeal_train.sh ./train.csv ./train_after.csv
预测回头客
请先确定Spark的运行方式,如果Spark是基于Hadoop伪分布式运行,那么请先运行Hadoop。
如果Hadoop没有运行,请执行如下命令:
cd /usr/local/hadoop/
sbin/start-dfs.sh
将两个数据集分别存取到HDFS中
bin/hadoop fs -mkdir -p /dbtaobao/dataset
bin/hadoop fs -put /usr/local/dbtaobao/dataset/train_after.csv /dbtaobao/dataset
bin/hadoop fs -put /usr/local/dbtaobao/dataset/test_after.csv /dbtaobao/dataset

启动MySQL服务
service mysql start
mysql -uroot -p #会提示让你输入数据库密码
输入密码后,你就可以进入“mysql>”命令提示符状态,然后就可以输入下面的SQL语句完成表的创建:
use dbtaobao;
create table rebuy (score varchar(40),label varchar(40));

启动pyspark
cd ~/下载/
unzip mysql-connector-java-5.1.40.zip -d /usr/local/spark/jars
接下来正式启动pyspark
cd /usr/local/spark
./bin/pyspark --jars /usr/local/spark/jars/mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar --driver-class-path /usr/local/spark/jars/mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar
支持向量机SVM分类器预测回头客
1.导入需要的包
首先,我们导入需要的包:
from pyspark import SparkContext
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.linalg import Vectors,Vector
from pyspark.mllib.classification import SVMModel, SVMWithSGD
from pyspark.python.pyspark.shell import spark
from pyspark.sql.types import Row
from pyspark.sql.types import *
2.读取训练数据
首先,读取训练文本文件;然后,通过map将每行的数据用“,”隔开,在数据集中,每行被分成了5部分,前4部分是用户交易的3个特征(age_range,gender,merchant_id),最后一部分是用户交易的分类(label)。把这里我们用LabeledPoint来存储标签列和特征列。LabeledPoint在监督学习中常用来存储标签和特征,其中要求标签的类型是double,特征的类型是Vector。
sc = SparkContext.getOrCreate()
train_data = sc.textFile("/dbtaobao/dataset/train_after.csv")
test_data = sc.textFile("/dbtaobao/dataset/test_after.csv")
构建模型
def GetParts(line):
parts = line.split(',')
return LabeledPoint(float(parts[4]),Vectors.dense(float(parts[1]),float(parts[2]),float(parts[3])))
train = train_data.map(lambda line: GetParts(line))
test = test_data.map(lambda line: GetParts(line))
接下来,通过训练集构建模型SVMWithSGD。这里的SGD即著名的随机梯度下降算法(Stochastic Gradient Descent)。设置迭代次数为1000,除此之外还有stepSize(迭代步伐大小),regParam(regularization正则化控制参数),miniBatchFraction(每次迭代参与计算的样本比例),initialWeights(weight向量初始值)等参数可以进行设置。
numIterations = 1000
model = SVMWithSGD.train(train, numIterations)
评估模型
接下来,我们清除默认阈值,这样会输出原始的预测评分,即带有确信度的结果。
def Getpoint(point):
score = model.predict(point.features)
return str(score) + " " + str(point.label)
model.clearThreshold()
scoreAndLabels = test.map(lambda point: Getpoint(point))
scoreAndLabels.foreach(lambda x : print(x))

如果我们设定了阀值,则会把大于阈值的结果当成正预测,小于阈值的结果当成负预测。
model.setThreshold(0.0)
scoreAndLabels.foreach(lambda x : print(x))
把结果添加到mysql数据库中
现在我们将上面没有设定阀值的测试集结果存入到MySQL数据中。
def Getpoint(point):
score = model.predict(point.features)
return str(score) + " " + str(point.label)
model.clearThreshold()
scoreAndLabels = test.map(lambda point: Getpoint(point))
//设置回头客数据
rebuyRDD = scoreAndLabels.map(lambda x: x.split(" "))
//下面要设置模式信息
schema = StructType([StructField("score", StringType(), True),StructField("label", StringType(), True)])
//下面创建Row对象,每个Row对象都是rowRDD中的一行
rowRDD = rebuyRDD.map(lambda p : Row(p[0].strip(), p[1].strip()))
//建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
rebuyDF = spark.createDataFrame(rowRDD, schema, True)
//下面创建一个prop变量用来保存JDBC连接参数
prop = {}
prop['user'] = 'root' //表示用户名是root
prop['password'] = '123' //表示密码是123
prop['driver'] = "com.mysql.jdbc.Driver" 、、//表示驱动程序是com.mysql.jdbc.Driver
//下面就可以连接数据库,采用append模式,表示追加记录到数据库dbtaobao的rebuy表中
rebuyDF.write.jdbc("jdbc:mysql://localhost:3306/dbtaobao",'dbtaobao.rebuy','append', prop)
bin/hadoop fs -put /usr/local/dbtaobao/dataset/train_after.csv /dbtaobao/dataset
bin/hadoop fs -put /usr/local/dbtaobao/dataset/test_after.csv /dbtaobao/dataset
train_data = sc.textFile("/dbtaobao/dataset/train_after.csv")
test_data = sc.textFile("/dbtaobao/dataset/test_after.csv")
hdfs://localhost:8020/dbtaobao/dataset/train_after.csv
hdfs://localhost:8020/dbtaobao/dataset/test_after.csv

步骤五:利用ECharts进行数据可视化分析
搭建tomcat+mysql+JSP开发环境
下载tomcat
java -version

解压apache-tomcat-8.0.41.zip到用户目录~下,执行如下命令:
cd ~/下载/
unzip apache-tomcat-8.5.88.zip -d ~
Oxygen - http://download.eclipse.org/releases/oxygen

利用Eclipse 新建可视化Web应用
打开Eclipse,点击“File”菜单,或者通过工具栏的“New”创建Dynamic Web Project,弹出向导对话框
填入Project name后,并点击"New Runtime"

出现New Server Runtime Environment向导对话框,选择“Apache Tomcat v8.0”,点击next按钮,如下图:
选择Tomcat安装文件夹。
返回New Server Runtime Environment向导对话框,点击finish即可。
这样新建一个Dynamic Web Project就完成了。在Eclipse中展开新建的MyWebApp项目,初始整个项目框架如下:
mysql-connector-java-*.zip是Java连接MySQL的驱动包,默认会下载到"~/下载/"目录
执行如下命令:
cd ~/下载/
unzip unzip mysql-connector-java-5.1.40.zip -d ~
cd ~/mysql-connector-java-5.1.40/
mv ./mysql-connector-java-5.1.40-bin.jar ~/workspace/MyWebApp/WebContent/WEB-INF/lib/mysql-connector-java-5.1.40-bin.jar
利用Eclipse 开发Dynamic Web Project应用
整个项目开发完毕的项目结构,如下:
首次运行MyWebApp,请按照如下操作,才能启动项目:
双击打开index.jsp文件,然后顶部Run菜单选择:Run As–>Run on Server
重要代码解析
整个项目,Java后端从数据库中查询的代码都集中在项目文件夹下/Java Resources/src/dbtaobao/connDb.java
package dbtaobao;
import java.sql.*;
import java.util.ArrayList;
public class connDb {
private static Connection con = null;
private static Statement stmt = null;
private static ResultSet rs = null;
//连接数据库方法
public static void startConn(){
try{
Class.forName("com.mysql.jdbc.Driver");
//连接数据库中间件
try{
con = DriverManager.getConnection("jdbc:MySQL://localhost:3306/dbtaobao","root","root");
}catch(SQLException e){
e.printStackTrace();
}
}catch(ClassNotFoundException e){
e.printStackTrace();
}
}
//关闭连接数据库方法
public static void endConn() throws SQLException{
if(con != null){
con.close();
con = null;
}
if(rs != null){
rs.close();
rs = null;
}
if(stmt != null){
stmt.close();
stmt = null;
}
}
//数据库双11 所有买家消费行为比例
public static ArrayList index() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select action,count(*) num from user_log group by action desc");
while(rs.next()){
String[] temp={rs.getString("action"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//男女买家交易对比
public static ArrayList index_1() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select gender,count(*) num from user_log group by gender desc");
while(rs.next()){
String[] temp={rs.getString("gender"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//男女买家各个年龄段交易对比
public static ArrayList index_2() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select gender,age_range,count(*) num from user_log group by gender,age_range desc");
while(rs.next()){
String[] temp={rs.getString("gender"),rs.getString("age_range"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//获取销量前五的商品类别
public static ArrayList index_3() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select cat_id,count(*) num from user_log group by cat_id order by count(*) desc limit 5");
while(rs.next()){
String[] temp={rs.getString("cat_id"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//各个省份的总成交量对比
public static ArrayList index_4() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select province,count(*) num from user_log group by province order by count(*) desc");
while(rs.next()){
String[] temp={rs.getString("province"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
}
前端页面想要获取服务端的数据,还需要导入相关的包,例如:/WebContent/index.jsp部分代码如下:
<%@ page language="java" import="dbtaobao.connDb,java.util.*" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%
ArrayList<String[]> list = connDb.index();
%>
前端JSP页面使用ECharts来展现可视化。每个JSP页面都需要导入相关ECharts.js文件,如需要中国地图的可视化,还需要另外导入china.js文件。
那么如何使用ECharts的可视化逻辑代码,我们在每个jsp的底部编写可视化逻辑代码。这里展示index.jsp中可视化逻辑代码:
<script>
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
option = {
backgroundColor: '#2c343c',
title: {
text: '所有买家消费行为比例图',
left: 'center',
top: 20,
textStyle: {
color: '#ccc'
}
},
tooltip : {
trigger: 'item',
formatter: "{a} <br/>{b} : {c} ({d}%)"
},
visualMap: {
show: false,
min: 80,
max: 600,
inRange: {
colorLightness: [0, 1]
}
},
series : [
{
name:'消费行为',
type:'pie',
radius : '55%',
center: ['50%', '50%'],
data:[
{value:<%=list.get(0)[1]%>, name:'特别关注'},
{value:<%=list.get(1)[1]%>, name:'购买'},
{value:<%=list.get(2)[1]%>, name:'添加购物车'},
{value:<%=list.get(3)[1]%>, name:'点击'},
].sort(function (a, b) { return a.value - b.value}),
roseType: 'angle',
label: {
normal: {
textStyle: {
color: 'rgba(255, 255, 255, 0.3)'
}
}
},
labelLine: {
normal: {
lineStyle: {
color: 'rgba(255, 255, 255, 0.3)'
},
smooth: 0.2,
length: 10,
length2: 20
}
},
itemStyle: {
normal: {
color: '#c23531',
shadowBlur: 200,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
},
animationType: 'scale',
animationEasing: 'elasticOut',
animationDelay: function (idx) {
return Math.random() * 200;
}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
代码本地实现:
结果:
 文章来源:https://www.toymoban.com/news/detail-471513.html
文章来源:https://www.toymoban.com/news/detail-471513.html
 文章来源地址https://www.toymoban.com/news/detail-471513.html
文章来源地址https://www.toymoban.com/news/detail-471513.html
到了这里,关于【大数据基础】淘宝双11数据分析与预测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!