前言
最近笔者为了捡回以前自学的ES知识,准备重新对ES的一些基础使用做个大致学习总结。然后在摸鱼逛开源社区时无意中发现了一款不错的ElasticSearch插件-Easy-ES,可称之为“ES界的MyBatis-Plus”。联想到之前每次用RestHighLevelClient写一些DSL操作时都很麻烦(复杂点的搜索代码量确实不少),加之用过MyBatisPlus,深感其对于简化开发、提高效率确实有一套,不知道这个Easy-ES能高效到什么水平,因此抱着学习的心态结合其文档一探究竟。
Easy-ES介绍
Easy-Es(简称EE)是一款基于ElasticSearch(简称Es)官方提供的RestHighLevelClient打造的ORM开发框架,在 RestHighLevelClient 的基础上,只做增强不做改变,为简化开发、提高效率而生,属于由国内开发者打造并完全开源的ElasticSearch-ORM框架!
因为它采用和Mybatis-Plus一致的语法设计,一定程度上能够显著降低ElasticSearch搜索引擎使用门槛,和额外学习成本,并大幅减少开发者工作量,帮助企业降本提效。如果有用过Mybatis-Plus(简称MP),那么基本可以零学习成本直接上手EE,EE是MP的Es平替版,在有些方面甚至比MP更简单,同时也融入了更多Es独有的功能,助力咱们快速实现各种场景的开发.
优势点
-
全自动索引托管: 全球开源首创的索引托管模式,开发者无需关心索引的创建更新及数据迁移等繁琐步骤,索引全生命周期皆可托管给框架,由框架自动完成,过程零停机,用户无感知,彻底解放开发者
-
智能字段类型推断: 根据索引类型和当前查询类型上下文综合智能判断当前查询是否需要拼接.keyword后缀,减少小白误用的可能
-
屏蔽语言差异: 开发者只需要会MySQL语法即可使用Es,真正做到一通百通,无需学习枯燥易忘的Es语法,Es使用相对MySQL较低频,学了长期不用也会忘,没必要浪费这时间,开发就应该专注于业务
-
代码量极少: 与直接使用RestHighLevelClient相比,相同的查询平均可以节省3-5倍左右的代码量
-
零魔法值: 字段名称直接从实体中获取,无需输入字段名称字符串这种魔法值,提高代码可读性,杜绝因字段名称修改而代码漏改带来的Bug
-
零额外学习成本: 开发者只要会国内最受欢迎的Mybatis-Plus语法,即可无缝迁移至EE,EE采用和前者相同的语法,消除使用者额外学习成本,直接上手,爽
-
降低开发者门槛: Es通常需要中高级开发者才能驾驭,但通过接入EE,即便是只了解ES基础的初学者也可以轻松驾驭ES完成绝大多数需求的开发,可以提高人员利用率,降低企业成本
主要特点
-
无侵入:只做增强不做改变,引入它不会对现有工程产生影响
-
损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
-
强大的 CRUD 操作:内置通用 Mapper,仅仅通过少量配置即可实现大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
-
支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错段
-
支持主键自动生成:支持2 种主键策略,可自由配置,完美解决主键问题
-
支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
-
支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
-
内置分页插件:基于RestHighLevelClient 物理分页,开发者无需关心具体操作,且无需额外配置插件,写分页等同于普通 List 查询,且保持和PageHelper插件同样的分页返回字段,无需担心命名影响
-
ES功能全覆盖:ES中支持的功能通过EE都可以轻松实现
-
支持ES高阶语法:支持高亮搜索,分词查询,权重查询,Geo地理位置查询,IP查询,聚合查询等高阶语法
-
良好的拓展性:底层仍使用RestHighLevelClient,可保持其拓展性,开发者在使用EE的同时,仍可使用RestHighLevelClient的功能
……
与Spring Data的功能对比
由于ES本身的高复杂性和高门槛,以及相比MySQL更少的用户群体,这块领域高投入,低回报,因此像ES这类的ORM框架并不多,截止目前除了Springdata-Es几乎没有竞对,两者在使用体感上可以类比Mybait-Plus与SpringData-JPA,由于双方底层都是ES官方套件,所以对比ES官方套件本身就支持的原生查询功能毫无意义,于是笔者根据Easy-ES汇总的功能对比如下:
| Easy-ES | SpringData-ES | |
|---|---|---|
| 语法 | 支持 | 支持 |
| 索引自动创建 | 支持 | 不支持 |
| 索引自动更新 | 支持 | 不支持 |
| 索引手动创建及更新 | 支持 | 不支持 |
| 简单CRUD | 支持 | 支持 |
| 复杂CRUD | 支持 | 不支持 |
| 父子查询 | 支持 | 不支持 |
| 嵌套查询 | 支持 | 不支持 |
| 排序及权重 | 支持 | 不支持 |
| 分页查询 | 支持全部三种模式 | 仅支持一种 |
| GEO地理位置查询 | 支持 | 不支持 |
| 聚合查询 | 支持 | 不支持 |
| 字段类型及查询推断 | 支持 | 不支持 |
| 数据自动平滑迁移 | 支持 | 不支持 |
| 性能 | 高(优于SpringData20%) | 高 |
| 代码量 | 极低 | 中低 |
与原生查询的语法对比
再回头看看传统的原生查询操作:
// ES原生的RestHighLevel语法
List<Integer> values = Arrays.asList(2, 3);
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.termQuery("business_type", 1));
boolQueryBuilder.must(QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("state", 9))
.should(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("state", 8))
.must(QueryBuilders.termQuery("bidding_sign", 1))));
boolQueryBuilder.should(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("business_type", 2))
.must(QueryBuilders.termsQuery("state", values)));在对比Easy-Es的简化后:
// Easy-Es及Mybatis-Plus语法
wrapper.eq("business_type", 1)
.and(a -> a.eq("state", 9).or(b -> b.eq("state", 8).eq("bidding_sign", 1)))
.or(i -> i.eq("business_type", 2).in("state", 2, 3));综合看来,Easy-ES基本实碾压的姿态...可能有夸大嫌疑哈,不过文末笔者也会根据自己的一些了解做点简单总结~ 下面接着看~
使用注意
官方文档很早就把这块放在使用手册前面了,并且明确说明了,该框架在使用时需要避坑的地方:由于开发者开发Easy-ES时底层用了ES官方的RestHighLevelClient,所以对ES版本有要求,要求ES和RestHighLevelClient JAR依赖版本必须为7.14.0,至于es客户端,实际7.X任意版本都可以很好的兼容。
值得注意的是,由于SpringData-ElasticSearch的存在,Springboot它内置了和ES及RestHighLevelClient依赖版本,这导致了不同版本的Springboot实际引入的ES及RestHighLevelClient 版本不同,而ES官方的这两个依赖在不同版本间的兼容性非常差,进一步导致很多用户无法正常使用Easy-Es。可谓非常良心,也就是说在使用时必须指定ES和RestHighLevelClient JAR依赖版本必须为7.14.0,其实笔者也试了一下,因为笔者本地ES是7.6.1的,在不排除依赖冲突的时候,其实也可以正常运行项目的,并且执行一些基础操作也是可以的(低版本的没试过)。但是会报错:

部分操作是正常的,但是总有这个异常看着也很难受,因此在后续实践中也改为了7.14.0,不知道随着ES8.0出现后,这个框架会不会优化更新,敬请期待~
排除依赖冲突也很容易,直接照着避坑指南重新引入7.14.0依赖即可:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</exclusion>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.14.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.14.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.dromara.easy-es/easy-es-boot-starter -->
<dependency>
<groupId>org.dromara.easy-es</groupId>
<artifactId>easy-es-boot-starter</artifactId>
<version>2.0.0-beta2</version>
</dependency>后续简单配置一些基础配置后运行就正常了,客户端保持7.6.1版本也不影响使用。
基础配置介绍
这里主要是在yml文件中对ES的一些基础配置,如果并没有太多需求,只要配置个地址即可,如果ES设置了账号密码认证,相应配置上账号密码即可。
easy-es:
banner: true
address: 127.0.0.1:9200 # es连接地址+端口 格式必须为ip:port,如果是集群则可用逗号隔开
connect-timeout: 5000
# username: zhangsan
# password: 123456另外如果为了提高生产环境性能,也持支按需配置:
easy-es:
keep-alive-millis: 1000 # 心跳策略时间 单位:ms
connect-timeout: 2000 # 连接超时时间 单位:ms
socket-timeout: 3000 # 通信超时时间 单位:ms
request-timeout: 4000 # 请求超时时间 单位:ms
connection-request-timeout: 5000 # 连接请求超时时间 单位:ms
max-conn-total: 20 # 最大连接数 单位:个
max-conn-per-route: 20 # 最大连接路由数 单位:个
#其他全局配置----------------------------------------------------
enable: true # 是否开启Easy-ES自动配置 默认开启,为false时则不启用该框架
schema: http # 默认为http 可缺省
banner: true # 默认为true 打印banner 若您不期望打印banner,可配置为false
global-config:
process-index-mode: smoothly #索引处理模式,smoothly:平滑模式,默认开启此模式, not_smoothly:非平滑模式, manual:手动模式
print-dsl: true # 开启控制台打印通过本框架生成的DSL语句,默认为开启,测试稳定后的生产环境建议关闭,以提升少量性能
distributed: false # 当前项目是否分布式项目,默认为true,在非手动托管索引模式下,若为分布式项目则会获取分布式锁,非分布式项目只需synchronized锁.
reindexTimeOutHours: 72 # 重建索引超时时间 单位小时,默认72H 可根据ES中存储的数据量调整
async-process-index-blocking: true # 异步处理索引是否阻塞主线程 默认阻塞 数据量过大时调整为非阻塞异步进行 项目启动更快
active-release-index-max-retry: 4320 # 分布式环境下,平滑模式,当前客户端激活最新索引最大重试次数,若数据量过大,重建索引数据迁移时间超过4320/60=72H,可调大此参数值,此参数值决定最大重试次数,超出此次数后仍未成功,则终止重试并记录异常日志
active-release-index-fixed-delay: 60 # 分布式环境下,平滑模式,当前客户端激活最新索引最大重试次数 分布式环境下,平滑模式,当前客户端激活最新索引重试时间间隔 若您期望最终一致性的时效性更高,可调小此值,但会牺牲一些性能
db-config:
map-underscore-to-camel-case: false # 是否开启下划线转驼峰 默认为false
index-prefix: daily_ # 索引前缀,可用于区分环境 默认为空 用法和MP的tablePrefix一样的作用和用法
id-type: customize # id生成策略 customize为自定义,id值由用户生成,比如取MySQL中的数据id,如缺省此项配置,则id默认策略为es自动生成
field-strategy: not_empty # 字段更新策略 默认为not_null
enable-track-total-hits: true # 默认开启,开启后查询所有匹配数据,若不开启,会导致无法获取数据总条数,其它功能不受影响,若查询数量突破1W条时,需要同步调整@IndexName注解中的maxResultWindow也大于1w,并重建索引后方可在后续查询中生效(不推荐,建议分页查询).
refresh-policy: immediate # 数据刷新策略,默认为不刷新,若对数据时效性要求比较高,可以调整为immediate,但性能损耗高,也可以调整为折中的wait_until
batch-update-threshold: 10000 # 批量更新接口的阈值 默认值为1万,突破此值需要同步调整enable-track-total-hits=true,@IndexName.maxResultWindow > 1w,并重建索引.
smartAddKeywordSuffix: true # 是否智能为字段添加.keyword后缀 默认开启,开启后会根据当前字段的索引类型及当前查询类型自动推断本次查询是否需要拼接.keyword后缀如果需要实时记录DSL的执行日志,也可以进行相应的日志信息打印配置:
#开启es的DSL日志
logging:
level:
trace: trace核心注解使用介绍
在Easy-ES中也有相对于MyBatisPlus那样的注解支持。比较重点的注解有如下4个:
-
@EsMapperScan
-
@IndexName
-
@IndexId
-
@IndexField
@EsMapperScan
这个注解类似于Mybatis框架的mapper扫描注解。在ES项目中只要我们的mapper接口继承BaseEsMapper<>就能调用内部封装的可供直接使用的方法。
package com.yy.config.mapper;
import com.yy.config.pojo.TestUser;
import org.dromara.easyes.core.core.BaseEsMapper;
import org.springframework.stereotype.Component;
/**
* @author young
* Date 2023/5/25 16:01
* Description: springboot-demo08-elasticsearch
*/
@Component
public interface TestMapper extends BaseEsMapper<TestUser> {
}但是前提是需要@EsMapperScan扫描到改包,在SpringBoot项目启动类上标明mapper接口所在包的位置@EsMapperScan("com.yy.config.mapper")即可,否则是会出错的。另外为了区别于MyBatis的扫描注解扫描mapper(dao)接口,因为两个框架彼此独立,扫描的时候没办法隔离,所以格外需要注意将MyBatis扫描的包与Easy-ES扫描的包区分开来,不能共用一个,否则也会报错!
@IndexName
同MyBatisPlus中的@TableName注解一样,主要是在实体类中标识对应的索引名称,因为ES中没有表的概念,而是对应的Index。其字段功能如下表所示:
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 索引名,可简单理解为MySQL表名 |
| shardsNum | int | 否 | 1 | 索引分片数 |
| replicasNum | int | 否 | 1 | 索引副本数 |
| aliasName | String | 否 | "" | 索引别名 |
| keepGlobalPrefix | boolean | 否 | false | 是否保持使用全局的 tablePrefix 的值,与MP用法一致 |
| child | boolean | 否 | false | 是否子文档 |
| childClass | Class | 否 | DefaultChildClass.class | 父子文档-子文档类 |
| maxResultWindow | int | 否 | 10000 | 分页返回的最大数据量,默认值为1万条,超出推荐使用searchAfter或滚动查询等方式,详见拓展功能章节. 当此值调整至大于1W后,需要重建索引并同步开启配置文件中的enable-track-total-hits=true方可生效 |
| routing | String | 否 | "" | 路由,CRUD作用的路由 |
如果在实体类上不使用该注解,则ES会默认将实体类名作为索引名。如果有全局配置或者自动生成过索引名,但是也用注解指定了,则优先级排序: 注解索引>全局配置索引前缀>自动生成。另外Easy-ES也支持动态索引名称,可以调用mapper或者CRUD中的wrapper修改索引名称。
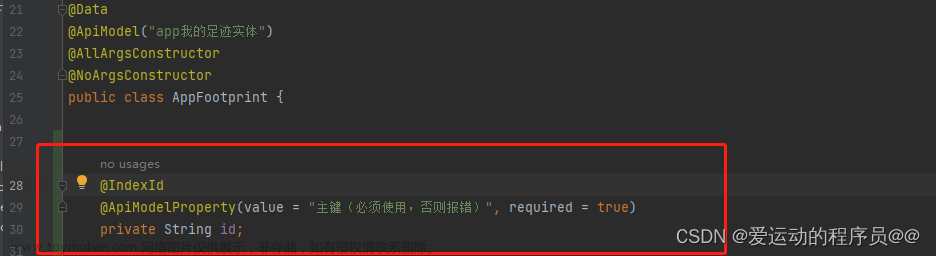
@IndexId
这个同样对应@TableId,可以指定id的生成类型并且标识索引id。在ES中如果实体类中有一个类型为String的id,在不添加该注解的条件下,会默认将该id识别为ES中的_id。如果是其他名称(比如ids),则会新建ids的索引字段。此时如果用@IndexId注解标识该ids,则不会创建新字段,而是映射为 _id。
@IndexField
用于实体类字段的注解。标识实体类中被作为ES索引字段的字段,参数功能如下:
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 字段名 |
| exist | boolean | 否 | true | 字段是否存在 |
| fieldType | Enum | 否 | FieldType.NONE | 字段在es索引中的类型 |
| fieldData | boolean | 否 | false | text类型字段是否支持聚合 |
| analyzer | String | 否 | Analyzer.NONE | 索引文档时用的分词器 |
| searchAnalyzer | String | 否 | Analyzer.NONE | 查询分词器 |
| strategy | Enum | 否 | FieldStrategy.DEFAULT | 字段验证策略 |
| dateFormat | String | 否 | "" | es索引中的日期格式,如yyyy-MM-dd |
| nestedClass | Class | 否 | DefaultNestedClass.class | 嵌套类 |
| parentName | String | 否 | "" | 父子文档-父名称 |
| childName | String | 否 | "" | 父子文档-子名称 |
| joinFieldClass | Class | 否 | JoinField.class | 父子文档-父子类型关系字段类 |
| ignoreCase | boolean | 否 | false | keyword类型字段是否忽略大小写 |
可根据自己不同场景的应用需求灵活配置:
public class TestUser {
private String stephen;
// 场景一:标记es中不存在的字段
@IndexField(exist = false)
private String token;
// 场景二:更新时,此字段非空字符串才会被更新
@IndexField(strategy = FieldStrategy.NOT_EMPTY)
private String description;
// 场景三: 指定fieldData
@IndexField(fieldType = FieldType.TEXT, fieldData = true)
private String content;
// 场景四:自定义字段名
@IndexField("my_music")
private String music;
// 场景五:支持日期字段在es索引中的format类型
@IndexField(fieldType = FieldType.DATE, dateFormat = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis")
private String createTime;
// 场景六:支持指定字段在es索引中的分词器类型
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART, searchAnalyzer = Analyzer.IK_MAX_WORD)
private String username;
// 场景七:支持指定字段在es的索引中忽略大小写,以便在term查询时不区分大小写,仅对keyword类型字段生效,es的规则,并非框架限制.
@IndexField(fieldType = FieldType.KEYWORD, ignoreCase = true)
private String title;
}额外需要注意的是strategy = FieldStrategy.NOT_EMPTY,它有三个可选配置:
-
not_null: 非Null判断,字段值为非Null时,才会被更新
-
not_empty: 非空判断,字段值为非空字符串时才会被更新
-
ignore: 忽略判断,无论字段值为什么,都会被更新
并且该配置是可以在yml配置文件中全局配置的,但是也可以通过该注解个性化配置,不过此时:全局配置的优先级是小于注解配置
索引模式介绍
在ES中,索引的创建和更新不仅复杂,而且难于维护,一旦索引有变动,就必须面对索引重建带来的服务停机和数据丢失等问题... 尽管ES官方提供了索引别名机制来解决问题,但门槛依旧很高,步骤繁琐,在生产环境中由人工操作非常容易出现失误带来严重的问题. 为了解决这些痛点,Easy-Es提供了多种策略,将用户彻底从索引的维护中解放出来,并提供了多种索引处理策略,来满足不同用户的个性化需求。
其中它支持三种索引托管模式可供我们使用:自动平滑模式、自动非平滑模式和手动模式。
自动平滑模式
该模式相当于将索引的创建、更新、数据迁移等操作全部交由Easy-Es自动完成,过程零停机,连索引类型都可以自动推断,这个方式也是目前Easy-Es默认支持的方式之一。其核心处理流程如下图(来源于Easy-Es官网-索引托管模式):

需要注意的是:在自动托管模式下,系统会自动生成一条名为ee-distribute-lock的索引,该索引为框架内部使用,用户可忽略,若不幸因断电等其它因素极小概率下发生死锁,可删除该索引即可。另外,在使用时如碰到索引变更,原索引名称可能会被追加后缀s0或s1。关于s0和s1后缀,在此模式下无法避免,因为要保留原索引数据迁移,又不能同时存在两个同名索引。
自动非平滑模式
该模式下,索引额创建及更新由EE全自动异步完成,但不处理数据迁移工作,适合在开发及测试环境使用,当然如果使用logstash等其它工具来同步数据,亦可在生产环境开启此模式,在此模式下不会出现s0和s1后缀,索引会保持原名称。其核心流程如下图所示:

以上两种自动模式中,索引信息主要依托于实体类,如果用户未对该实体类进行任何配置,Easy-Es依然能够根据字段类型智能推断出该字段在ES中的存储类型。当然,仅靠框架自动推断是不够的,我们仍然建议您在使用中尽量进行详细的配置,以便框架能自动创建出生产级的索引。
ES的自动推断映射表如下:
| JAVA | ES |
|---|---|
| byte | byte |
| short | short |
| int | integer |
| long | long |
| float | float |
| double | double |
| BigDecimal | keyword |
| char | keyword |
| String | keyword_text |
| boolean | boolean |
| Date | date |
| LocalDate | date |
| LocalDateTime | date |
| List | text |
| ... | ... |
手动模式
在此模式下,索引的所有维护工作Easy-Es框架均不介入,由用户自行处理,Easy-Es提供了开箱即用的索引CRUD相关API,我们可以选择使用该API手动维护索引,由于API高度完善,就算自己创建也比原生简单。

在手动模式下,我们可以通过注解+mapper接口提供的createIndex方法创建索引。也可以通过api创建,每个需要被索引的字段都需要处理,比较繁琐,但灵活性最好,支持所有es能支持的所有索引创建,供0.01%场景使用(不推荐)
@Test
public void testCreatIndex() {
LambdaEsIndexWrapper<TestUser> wrapper = new LambdaEsIndexWrapper<>();
wrapper.indexName(TestUser.class.getSimpleName().toLowerCase());
// 此处将文章标题映射为keyword类型(不支持分词),文档内容映射为text类型,可缺省
// 支持分词查询,内容分词器可指定,查询分词器也可指定,,均可缺省或只指定其中之一,不指定则为ES默认分词器(standard)
wrapper.mapping(TestUser::getTitle, FieldType.KEYWORD)
.mapping(TestUser::getContent, FieldType.TEXT,Analyzer.IK_MAX_WORD,Analyzer.IK_MAX_WORD);
// 如果上述简单的mapping不能满足你业务需求,可自定义mapping
Map<String, Object> map = new HashMap<>();
Map<String, Object> prop = new HashMap<>();
Map<String, String> field = new HashMap<>();
field.put("type", FieldType.KEYWORD.getType());
prop.put("this_is_field", field);
map.put("properties", prop);
wrapper.mapping(map);
// 设置分片及副本信息,2个shards,1个replicas,可缺省
wrapper.settings(2,1);
// 如果上述简单的settings不能满足你业务需求,可自定义settings
// 设置别名信息,可缺省
String aliasName = "user";
wrapper.createAlias(aliasName);
// 创建索引
boolean isOk = testUserMapper.createIndex(wrapper);
}Tips:在使用手动模式时需要手动在yml文件中配置该模式:
easy-es:
global-config:
process_index_mode: manual #索引处理模式,smoothly:平滑模式,默认开启此模式, not_smoothly:非平滑模式, manual:手动模式测试项目准备
完成这些基础了解后可以试着使用Easy-ES的功能了。
Step1:导入依赖
在自己的项目中根据要求导入7.14.0的ES依赖(不影响7.x的客户端使用),并配置yml文件中的ES服务地址信息,上面也说过,如果只用RestHighLevelClient不配置也无所谓,但是这个Easy-Es需要手动配置。
Step2:配置yml文件中的ES地址
server:
port: 8080
easy-es:
banner: true
address: 127.0.0.0:9200
global-config:
distributed: false
# connect-timeout: 5000
#开启es的DSL日志
logging:
level:
trace: trace
spring:
application:
name: Easy-Es_Test当然,配置这个好处就是不用我们手动再去配置RestHighLevelClient了,并且同样可以使用RestHighLevelClient来自定义需要的功能,保证了其扩展性。
Step3:创建ES独立的mapper接口
根据使用要求需要一个类MyBatis中的数据层接口继承Easy-Es的功能,这样就能使用其封装的功能了。但是不同之处在于省掉了service接口,相比MyBatisPlus更简洁了,功能全集中在mapper接口中。
package com.yy.config.mapper;
import com.yy.config.pojo.TestUser;
import org.dromara.easyes.core.core.BaseEsMapper;
import org.springframework.stereotype.Component;
/**
* @author young
* Date 2023/5/25 16:01
* Description: 继承Easy-Es功能的mapper接口
*/
@Component
public interface TestMapper extends BaseEsMapper<TestUser> {
}Step4:扫描mapper接口
为了让mapper层功能正常使用,需要在SpringBoot项目启动类上扫描ES接口,并将其所在的包与MyBatis中的扫描包区分,不能将接口建在同一个扫描包路径下。
package com.yy;
import org.dromara.easyes.starter.register.EsMapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@EsMapperScan("com.yy.config.mapper")
public class SpringbootDemo08ElasticsearchApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootDemo08ElasticsearchApplication.class, args);
}
}功能使用
搭建好Easy-Es的基础使用框架后现在就可以试一下这个框架的功能咋样了。
数据CRUD
在Easy-Es中推荐了两种条件封装方式以便我们进行数据操作:创建LambdaEsQueryWrapper对象以及通过EsWrappers创建对象。第一种与MyBatisPlus中的QueryWrapper类似,而EsWrappers这个类更像一个工具类,方便创建不同的包装对象以及链式调用的对象,并在索引和数据的查询、更新中发挥包装执行条件的作用。
新增操作
@Test
void testAdd(){
//添加数据,可在数据同步时使用
TestUser lebron = new TestUser().setAge(38).setName("勒布朗詹姆斯").setTeam("Los Angeles Lakers").setDescription("历史得分王");
TestUser stephen = new TestUser().setAge(35).setName("斯蒂芬库里").setTeam("Golden State Warriors").setDescription("历史三分王");
TestUser young = new TestUser().setAge(17).setName("斯蒂芬young").setTeam("yy").setDescription("yy");
ArrayList<TestUser> testUsers = new ArrayList<>();
testUsers.add(lebron);
testUsers.add(stephen);
testUsers.add(young);
// 批量插入多条记录
System.out.println(testMapper.insertBatch(testUsers));
}这里测试的是一个批量插入操作,向ES中插入数据,用过MyBatisPlus的应该很熟悉,方法名称都是一致的。
2023-05-31 21:33:31.468 INFO 18292 --- [ main] easy-es : Elasticsearch jar version:7.14.0
2023-05-31 21:33:31.665 INFO 18292 --- [ main] easy-es : Elasticsearch client version:7.6.1
2023-05-31 21:33:31.665 WARN 18292 --- [ main] easy-es : Elasticsearch clientVersion:7.6.1 not equals jarVersion:7.14.0, It does not affect your use, but we still recommend keeping it consistent!
2023-05-31 21:33:32.535 INFO 18292 --- [ main] gbootDemo08ElasticsearchApplicationTests : Started SpringbootDemo08ElasticsearchApplicationTests in 4.123 seconds (JVM running for 5.533)
2023-05-31 21:33:32.604 INFO 18292 --- [ main] easy-es : ===> Smoothly process index mode activated
2023-05-31 21:33:32.711 INFO 18292 --- [onPool-worker-1] easy-es : ===> Index not exists, automatically creating index by easy-es...
2023-05-31 21:33:33.155 INFO 18292 --- [onPool-worker-1] easy-es : ===> Congratulations auto process index by Easy-Es is done !
3在没有索引时,由于我们使用的是自动平滑模式生成索引,因此会在日志中生成相应提示以及插入操作成功返回的数据数3。
查看Es-head后即可看见相应的索引创建成功以及里面的数据成功插入:

修改操作
@Test
void testUpdate(){
TestUser newDate = new TestUser().setDescription("明年会退役吗?");
Integer update1 = EsWrappers.lambdaChainUpdate(testMapper).eq(TestUser::getName, "勒布朗詹姆斯").update(newDate);
System.out.println(update1>0?"修改成功!":"修改失败!");
}这里笔者为了方便也是使用了链式调用一步完成的,修改name为“勒布朗詹姆斯”的数据:
2023-05-31 21:38:00.460 INFO 5616 --- [ main] easy-es : Elasticsearch jar version:7.14.0
2023-05-31 21:38:00.672 INFO 5616 --- [ main] easy-es : Elasticsearch client version:7.6.1
2023-05-31 21:38:00.672 WARN 5616 --- [ main] easy-es : Elasticsearch clientVersion:7.6.1 not equals jarVersion:7.14.0, It does not affect your use, but we still recommend keeping it consistent!
2023-05-31 21:38:01.547 INFO 5616 --- [ main] gbootDemo08ElasticsearchApplicationTests : Started SpringbootDemo08ElasticsearchApplicationTests in 4.097 seconds (JVM running for 5.374)
2023-05-31 21:38:01.607 INFO 5616 --- [ main] easy-es : ===> Smoothly process index mode activated
2023-05-31 21:38:01.688 INFO 5616 --- [onPool-worker-1] easy-es : ===> Index exists, automatically updating index by easy-es...
2023-05-31 21:38:02.095 INFO 5616 --- [onPool-worker-1] easy-es : ===> index has nothing changed
2023-05-31 21:38:02.095 INFO 5616 --- [onPool-worker-1] easy-es : ===> Congratulations auto process index by Easy-Es is done !
2023-05-31 21:38:02.367 INFO 5616 --- [ main] easy-es : ===> Execute By Easy-Es:
index-name: test_user
DSL:{"size":10000,"query":{"bool":{"must":[{"term":{"name.keyword":{"value":"勒布朗詹姆斯","boost":1.0}}}],"adjust_pure_negative":true,"boost":1.0}},"_source":{"includes":["_id"],"excludes":[]},"track_total_hits":2147483647}
修改成功!控制台成功打印了相应的DSL日志及操作执行结果。
查询操作
@Test
void testQuery(){
//new构建查询条件,基础写法
LambdaEsQueryWrapper<TestUser> wrapper = new LambdaEsQueryWrapper<>();
//EsWrappers封装查询条件
//LambdaEsQueryWrapper<TestUser> queryWrapper = EsWrappers.lambdaQuery(TestUser.class).like(TestUser::getDescription, "历史");
wrapper.like(TestUser::getDescription,"历史");
wrapper.orderByDesc(TestUser::getAge);
//用EsWrappers创建链式写法并模糊匹配查询
TestUser one = EsWrappers.lambdaChainQuery(testMapper).likeLeft(TestUser::getName, "库里").one();
SearchResponse search1 = testMapper.search(wrapper);
System.out.println(Arrays.toString(search1.getHits().getHits()));
System.out.println(one);
}查看执行结果:
index-name: test_user
DSL:{"size":10000,"query":{"bool":{"must":[{"wildcard":{"name.keyword":{"wildcard":"*库里","boost":1.0}}}],"adjust_pure_negative":true,"boost":1.0}},"track_total_hits":2147483647}
2023-05-31 21:52:56.800 INFO 812 --- [ main] easy-es : ===> Execute By Easy-Es:
index-name: test_user
DSL:{"size":10000,"query":{"bool":{"must":[{"wildcard":{"description":{"wildcard":"*历史*","boost":1.0}}}],"adjust_pure_negative":true,"boost":1.0}},"sort":[{"age":{"order":"desc"}}],"track_total_hits":2147483647}
[{
"_index" : "test_user",
"_type" : "_doc",
"_id" : "irYVcogBrMcQl9SRH46R",
"_score" : null,
"_source" : {
"age" : 38,
"description" : "历史得分王",
"name" : "勒布朗詹姆斯",
"team" : "Los Angeles Lakers"
},
"sort" : [
38
]
}, {
"_index" : "test_user",
"_type" : "_doc",
"_id" : "i7YVcogBrMcQl9SRH46R",
"_score" : null,
"_source" : {
"age" : 35,
"description" : "历史三分王",
"name" : "斯蒂芬库里",
"team" : "Golden State Warriors"
},
"sort" : [
35
]
}]
TestUser(id=i7YVcogBrMcQl9SRH46R, name=斯蒂芬库里, description=历史三分王, age=35, team=Golden State Warriors)可以基于like的模糊查询以及左匹配模糊查询结果也正确返回。
删除操作
@Test
void testDelete(){
Integer delete = testMapper.delete(EsWrappers.lambdaQuery(TestUser.class).filter(age -> age.le(TestUser::getAge, 30)));
System.out.println(delete>0?"删除成功!":"删除失败!");
}这里通过filter过滤删除一条年龄小于30的数据:
……
2023-05-31 22:01:06.816 INFO 872 --- [onPool-worker-1] easy-es : ===> index has nothing changed
2023-05-31 22:01:06.817 INFO 872 --- [onPool-worker-1] easy-es : ===> Congratulations auto process index by Easy-Es is done !
删除成功!结果也显而易见。
 整体上,确实相比于原生写操作简单了不少。当然,以上只是些基础的功能而已,高阶的功能还要慢慢看~
整体上,确实相比于原生写操作简单了不少。当然,以上只是些基础的功能而已,高阶的功能还要慢慢看~
高阶查询
通常在ES的使用中,在业务中的操作可能远不止简简单单的基础增删该查而已,因此Easy-Es也扩展了很多高阶功能,以便大家灵活使用。官网介绍了很多,但是这里笔者仅介绍几个我个人比较感兴趣的记录一下使用方法,其他读者可自行参照官网去学习。
高亮显示
高亮显示应该是ES作为数据搜索引擎用得最多的地方,但是在原生高亮使用中需要通过HighlightBuilder这个类来配置,但是在Easy-Es中,只需要在对应的实体类上添加高亮注解@HighLight就行了。并且省去了通过类配置自定义高亮样式的操作,只需要在注解对应的属性上设置就行了。
@Data
@AllArgsConstructor
@NoArgsConstructor
@IndexName(value = "test_user",aliasName = "测试EasyEs")
@Accessors(chain = true)
public class TestUser {
private String id;
private String name;
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART, searchAnalyzer = Analyzer.IK_MAX_WORD)
@HighLight(preTag = "<span style='color:red;'>",postTag = "</span>")
private String description;
//省略其他字段
……
}这样当查询这些数据信息时,返回的对应字段上就有自己自定义的高亮显示。
index-name: test_user
DSL:{"size":10000,"query":{"bool":{"must":[{"wildcard":{"description":{"wildcard":"*历史*","boost":1.0}}}],"adjust_pure_negative":true,"boost":1.0}},"track_total_hits":2147483647,"highlight":{"pre_tags":["<span style='color:red;'>"],"post_tags":["</span>"],"fragment_size":100,"fields":{"description":{"type":"unified"}}}}
TestUser(id=vSr3dYgBC5UsEDPvj4oQ, name=勒布朗詹姆斯, description=<span style='color:red;'>历史</span>得分王, age=38, team=Los Angeles Lakers)
TestUser(id=vir3dYgBC5UsEDPvj4oQ, name=斯蒂芬库里, description=<span style='color:red;'>历史</span>三分王, age=35, team=Golden State Warriors)如果你并不想改变原有查询出来的信息的样式结果,也可以在实体类上新建一个映射属性,将返回结果映射到该属性上即可。
在实体类上新添加一个用于接收映射结果的属性,并在@HighLight上指定它。
public class TestUser {
private String id;
private String name;
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART, searchAnalyzer = Analyzer.IK_MAX_WORD)
@HighLight(preTag = "<span style='color:red;'>",postTag = "</span>",mappingField = "highMapping")
private String description;
//省略其他字段
……
}再次进行模糊查询后返回的结果:
index-name: test_user
DSL:{"size":10000,"query":{"bool":{"must":[{"wildcard":{"description":{"wildcard":"*历史*","boost":1.0}}}],"adjust_pure_negative":true,"boost":1.0}},"track_total_hits":2147483647,"highlight":{"pre_tags":["<span style='color:red;'>"],"post_tags":["</span>"],"fragment_size":100,"fields":{"description":{"type":"unified"}}}}
TestUser(id=vSr3dYgBC5UsEDPvj4oQ, name=勒布朗詹姆斯, description=历史得分王, highMapping=<span style='color:red;'>历史</span>得分王, age=38, team=Los Angeles Lakers)
TestUser(id=vir3dYgBC5UsEDPvj4oQ, name=斯蒂芬库里, description=历史三分王, highMapping=<span style='color:red;'>历史</span>三分王, age=35, team=Golden State Warriors)这样原来的查询的description并不会被我们自定的样式渲染,而是全部映射到新加的highMapping属性上。
分词匹配
在Easy-Es中需要分词匹配的字段索引类型必须为text或keyword_text(不指定时默认为此类型),并为其指定分词器,所需分词器需提前安装,否则将使用es默认分词器,对中文支持不好,因此在使用之前推荐先配置好分词器。另外在Easy-Es中也给出了一些用于分词匹配操作的API帮助我们操作使用:
match(boolean condition, R column, Object val);
matchPhase(boolean condition, R column, Object val, Float boost);
matchAllQuery();
matchPhrasePrefixQuery(boolean condition, R column, Object val, int maxExpansions, Float boost);
multiMatchQuery(boolean condition, Object val, Operator operator, int minimumShouldMatch, Float boost, R... columns);
queryStringQuery(boolean condition, String queryString, Float boost);
prefixQuery(boolean condition, R column, String prefix, Float boost);当然也包括模糊查询like之类的也属于该范畴。关于索引和API的使用参考如下表所示:
| ES原生 | Easy-Es | keyword类型 | text类型 | 是否支持分词 |
|---|---|---|---|---|
| term | eq | 完全匹配 | 查询条件必须都是text分词中的,且不能多余,多个分词时必须连续,顺序不能颠倒 |
否 |
| wildcard | like/likeLeft/likeRight | 根据api模糊匹配 like全模糊,likeLeft左模糊,likeRight右模糊 | 不支持 | 否 |
| match | match | 完全匹配 | match分词结果和text的分词结果有相同的即可,不考虑顺序
|
是 |
| matchPhrase | matchPhrase | 完全匹配 | matchPhrase的分词结果必须在text字段分词中都包含且顺序必须都相同,而且必须都是连续的. |
是 |
| matchPhrasePrefixQuery | matchPhrasePrefixQuery | 不支持 | matchPhrasePrefix与matchPhrase相同,除了它允许在文本的最后一个词上的前缀匹配. |
是 |
| multiMatchQuery | multiMatchQuery | 完全匹配 | 全字段分词匹配,可实现全文检索功能 | 是 |
| queryStringQuery | queryStringQuery | 完全匹配 | queryString中的分词结果至少有一个在text字段的分词结果中,不考虑顺序 | 是 |
| prefixQuery | prefixQuery | 完全匹配 | 只要分词后的词条中有词条满足前缀条件即可 | 是 |
介于上面已经测试过模糊查询的效果,这块就不继续测试了。
混合查询
在上面的查询中根据DSL不难发现,其实笔者在使用模糊匹配的时候确实用到的是通配符查询-wildcard,但是实际上在ES中原生支持的查询匹配方式并不只有这一种而已。在 Elasticsearch 中,有以下常见的匹配条件:
-
全文检索查询:MatchQuery,MultiMatchQuery,CommonTermsQuery,QueryStringQuery。
-
精确查询:TermQuery,TermsQuery,RangeQuery。
-
前缀匹配/通配符查询:PrefixQuery,WildcardQuery。
-
正则表达式查询:RegexpQuery。
-
短语匹配查询:MatchPhraseQuery。
-
跨度查询:SpanTermQuery,SpanNearQuery,SpanOrQuery,SpanNotQuery。
-
模糊查询:FuzzyQuery。
-
聚合查询:NumericRangeAggregation,DateHistogramAggregation,TermsAggregation等。
每种查询条件都有不同的匹配方式和适用场景,具体的区别如下:
-
全文检索查询:根据指定条件进行全文检索,将查询条件在倒排索引中进行匹配,得到一个文档评分。MatchQuery、MultiMatchQuery适用于在多个字段中查询指定词汇的文档,CommonTermsQuery则对指定词汇进行包含和排除操作,QueryStringQuery支持使用Lucene的查询语法进行高级查询。
-
精确查询:查询时精确匹配词项。TermQuery适用于查询单个精确值,TermsQuery适用于查询多个精确值,RangeQuery适用于查询某个区间范围内的文档。
-
前缀匹配/通配符查询:前缀匹配查询将文本匹配到指定前缀、通配符查询则是将文本匹配到指定的模式。PrefixQuery适用于对某个字段进行前缀匹配,WildcardQuery适用于采用通配符的方式进行匹配,如:*和?。
-
正则表达式查询:使用正则表达式语法进行匹配,适用于数据规律较为复杂或规律不确定的情况。
-
短语匹配查询:匹配一个文本序列而非单个独立词项,适用于查询短语的场景。MatchPhraseQuery可以指定匹配短语的位置和跨度。
-
跨度查询:也是匹配短语,但支持在文本中跳过一定数量的单词进行匹配,SpanTermQuery、SpanNearQuery、SpanOrQuery、SpanNotQuery,适用于一些文本分析的场景,如:短语检索、句子检索等。
-
模糊查询:在词项对应的倒排索引中找到相似的候选匹配项,适用于用户打错词的场景。FuzzyQuery支持设置模糊度的程度。
-
聚合查询:按照不同的条件进行数据聚合,返回聚合分析结果。NumericRangeAggregation用于按照数值范围进行数据聚合,DateHistogramAggregation用于按照时间序列进行数据聚合,TermsAggregation用于提取条款集合(例如,字段路径),并为它们提供所有匹配项的文档计数。
不同类型的查询条件需要我们根据实际场景选择最佳的查询方式,以提高查询效率和准确度。但是Easy-Es其实并没有全部集成这些匹配查询方式,它虽然覆盖了RestHighLevelClient约90%左右的API,和99.9%的核心高频使用功能,但是也不可避免的会出现个别场景下,Easy-Es不能满足某个特殊需求,因此需要通过混合查询来解决问题。
所谓的混合查询也就是将Easy-Es的框架集成查询与原生RestHighLevelClient提供的查询方式进行组合。由于Easy-Es底层以及集成了RestHighLevelClient,因此其实使用起来也并不难。由于官方文档上介绍已经非常详细了,笔者这里直接copy供大家了解即可,就不再重新示范了。
/**
* 正确使用姿势0(最实用,最简单,最推荐的使用姿势):EE满足的语法,直接用,不满足的可以构造原生QueryBuilder,然后通过wrapper.mix传入QueryBuilder
* @since 2.0.0-beta2 2.0.0-beta2才正式引入此方案,此方案为混合查询的最优解决方案,由于QueryBuilder涵盖了ES中全部的查询,所以通过此方案
* 理论上可以处理任何复杂查询,并且可以和EE提供的四大嵌套类型无缝衔接,彻底简化查询,解放生产力!
*/
@Test
public void testMix0(){
// 查询标题为老汉,内容匹配 推*,且最小匹配度不低于80%的数据
// 当前我们提供的开箱即用match并不支持设置最小匹配度,此时就可以自己去构造一个matchQueryBuilder来实现
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
QueryBuilder queryBuilder = QueryBuilders.matchQuery("content", "推*").minimumShouldMatch("80%");
wrapper.eq(Document::getTitle,"老汉").mix(queryBuilder);
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
/**
* 混合查询正确使用姿势1: EE提供的功能不支持某些过细粒度的功能,所有查询条件通过原生语法构造,仅利用EE提供的数据解析功能
*/
@Test
public void testMix1() {
// RestHighLevelClient原生语法
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("content", "推*").minimumShouldMatch("80%"));
// 仅利用EE查询并解析数据功能
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.setSearchSourceBuilder(searchSourceBuilder);
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
/**
* 混合查询正确使用姿势2: 其它都能支持,仅排序器不支持,这种情况可以只按ES原生语法构造所需排序器SortBuilder,其它用EE完成
*/
@Test
public void testMix2() {
// EE满足的语法
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.match(Document::getContent, "推*");
// RestHighLevelClient原生语法
Script script = new Script("doc['star_num'].value");
ScriptSortBuilder scriptSortBuilder = SortBuilders.scriptSort(script,ScriptSortBuilder.ScriptSortType.NUMBER).order(SortOrder.DESC);
// 利用EE查询并解析数据
wrapper.sort(scriptSortBuilder);
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
/**
* 混合查询正确使用姿势3: 其它功能都能支持,但需要向SearchSourceBuilder中追加非query参数
*/
@Test
public void testMix3() {
// EE满足的语法
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.match(Document::getContent, "推*");
SearchSourceBuilder searchSourceBuilder = documentMapper.getSearchSourceBuilder(wrapper);
// 追加或者设置一些SearchSourceBuilder支持但EE暂不支持的参数 不建议追加query参数,因为如果追加query参数会直接覆盖上面EE已经帮你生成好的query,以最后set的query为准
searchSourceBuilder.timeout(TimeValue.timeValueSeconds(3L));
wrapper.setSearchSourceBuilder(searchSourceBuilder);
List<Document> documents = documentMapper.selectList(wrapper);
System.out.println(documents);
}
/**
* 查询条件中可以利用大多数基本查询,但EE提供的聚合功能不能满足需求的情况下,需要自定义聚合器
*/
@Test
public void textMix4() {
// EE满足的语法
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, "老汉")
.match(Document::getContent, "推*");
SearchSourceBuilder searchSourceBuilder = documentMapper.getSearchSourceBuilder(wrapper);
// RestHighLevelClient原生语法
AggregationBuilder aggregation = AggregationBuilders.terms("titleAgg")
.field("title");
searchSourceBuilder.aggregation(aggregation);
wrapper.setSearchSourceBuilder(searchSourceBuilder);
SearchResponse searchResponse = documentMapper.search(wrapper);
// TODO 聚合后的信息是动态的,框架无法解析,需要用户根据聚合器类型自行从桶中解析,参考RestHighLevelClient官方Aggregation解析文档
}分页查询
在Easy-Es中目前已经支持了三种分页方式:
| 分页方式 | 性能 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| from+size 浅分页 | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll 滚动查询 | 中 | 解决了深度分页问题 | 无法反应数据的实时性 | 海量数据的导出需要查询海量结果集的数据 |
| search_after | 高 | 性能最好,不存在深度分页问题,能够反应数据的实时变化 | 实现复杂,需要有一个全局唯一的字段连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果,它不适用于大幅度跳页查询 | 海量数据的分页 |
浅分页
浅分页和MyBatisPlus基本类似,直接调用pageQuery即可:
@Test
void analyzeQuery(){
System.out.println(testMapper.pageQuery(EsWrappers.lambdaQuery(TestUser.class).ge(TestUser::getAge, 30), 1, 2));
}这样就能获取分页后的查询信息:
index-name: test_user
DSL:{"from":0,"size":2,"query":{"bool":{"must":[{"range":{"age":{"from":30,"to":null,"include_lower":true,"include_upper":true,"boost":1.0}}}],"adjust_pure_negative":true,"boost":1.0}},"track_total_hits":2147483647,"highlight":{"pre_tags":["<span style='color:red;'>"],"post_tags":["</span>"],"fragment_size":100,"fields":{"description":{"type":"unified"}}}}
PageInfo{pageNum=1, pageSize=2, size=2, startRow=0, endRow=1, pages=2, prePage=0, nextPage=2, isFirstPage=true, isLastPage=false, hasPreviousPage=false, hasNextPage=true, navigatePages=8, navigatepageNums=[1, 2], navigateFirstPage=1, navigateLastPage=2, total=4, list=[TestUser(id=wCoSdogBC5UsEDPvuIpG, name=勒布朗詹姆斯, description=历史得分王,伟大的得分手, highMapping=null, age=38, team=Los Angeles Lakers), TestUser(id=wSoSdogBC5UsEDPvuIpG, name=斯蒂芬库里, description=历史三分王,伟大的投手, highMapping=null, age=35, team=Golden State Warriors)]}滚动查询
滚动查询可以方便地批量读取大量数据,避免一次性把所有结果读取到内存中而导致内存溢出。在Easy-Es中使用滚动查询可以通过以下的方式来实现:
@Test
void test(){
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
TimeValue keepAlive = TimeValue.timeValueMinutes(1L);
SearchResponse searchResponse = client.prepareSearch("index")
.setScroll(keepAlive)
.setSize(100)
.setQuery(searchSourceBuilder.query())
.execute()
.actionGet();
String scrollId = searchResponse.getScrollId();
SearchHit[] searchHits = searchResponse.getHits().getHits();
while (searchHits != null && searchHits.length > 0) {
for (SearchHit hit : searchHits) {
// 处理搜索结果
}
SearchResponse scrollResponse = client.prepareSearchScroll(scrollId)
.setScroll(keepAlive)
.execute()
.actionGet();
scrollId = scrollResponse.getScrollId();
searchHits = scrollResponse.getHits().getHits();
}
ClearScrollResponse clearScrollResponse = client.prepareClearScroll()
.addScrollId(scrollId)
.execute()
.actionGet();
}这里在索引“index”中查询所有文档,并用setScroll方法来设置滚动查询时间(这里设置为1分钟)。设置setSize方法表示每次查询返回的文档条数,setQuery方法用于设置查询条件。通过while循环和prepareSearchScroll方法不断读取滚动查询的结果集。到达这个方法的最后一个批次或使用ClearScrollRequest清除滚动ID时结束查询。
滚动查询在实际业务中的应用是读取大量数据的场景,例如:从Elasticsearch集群中导出大量数据到数据仓库中。
searchAfter
使用searchAfter功能可以在进行分页查询时,使用上一页的最后一条记录的排序值作为下一页查询的起始值,避免前一页的数据重复出现。
@Test
public void testSearchAfter() {
LambdaEsQueryWrapper<TestUser> lambdaEsQueryWrapper = EsWrappers.lambdaQuery(TestUser.class);
lambdaEsQueryWrapper.size(6);
// 必须指定一种排序规则,且排序字段值必须唯一 此处我选择用id进行排序 实际可根据业务场景自由指定,不推荐用创建时间,因为可能会相同
lambdaEsQueryWrapper.orderByDesc(TestUser::getId);
SAPageInfo<TestUser> saPageInfo = testMapper.searchAfterPage(lambdaEsQueryWrapper, null, 3);
// 第一页
System.out.println(saPageInfo);
Assertions.assertEquals(3, saPageInfo.getList().size());
// 获取下一页
List<Object> nextSearchAfter = saPageInfo.getNextSearchAfter();
SAPageInfo<TestUser> next = testMapper.searchAfterPage(lambdaEsQueryWrapper, nextSearchAfter, 3);
Assertions.assertEquals(3, next.getList().size());
}需要注意的是:使用searchAfter必须指定排序,若没有排序不仅会报错,而且对跳页也不友好。 需要保持searchAfter排序唯一,不然会导致分页失效,推荐使用id,uuid等进行排序。
当然Easy-Es的所有功能点远不止这点,有兴趣的小伙伴可以去Easy-Es官网自行学习哈。
一点小见解
对于Spring Data Elasticsearch(简称Spring ES)笔者也做过一些简单了解。二者都是针对Elasticsearch的框架,可以方便地在Java应用中快速地操作和使用Elasticsearch。
从易用性和便捷性上来看,Easy-ES的API封装比Spring ES更为简单明了,易于理解和使用。Easy-ES集成了Elasticsearch的常用操作,并提供了常用的查询构建器,使用起来非常方便。同时,Easy-ES还提供了高亮、聚合、全文搜索等一系列功能,这些功能对于一些中小型项目而言是非常实用的。
而Spring ES则是Spring框架提供的Elasticsearch模块,它的API设计更为底层,需要用户有一定的Elasticsearch基础才能使用得好。但是,相对于Easy-ES而言,Spring ES可扩展性更好,可以支持更多的自定义操作,并且能够与Spring集成非常紧密,使得用户能够更好地利用Spring提供的依赖注入、事务管理等功能。文章来源:https://www.toymoban.com/news/detail-471531.html
因此,Easy-ES和Spring ES在不同方面都有自己的优劣势,需要根据具体的应用场景和使用需求来选择。如果是快速地构建简单的全文搜索应用,Easy-ES比较适合;如果是大型的、需要复杂操作和自定义的应用,或者需要与Spring紧密集成,那么Spring ES更加适合。大伙有兴趣也可以去实际体验一下,对初学者还是比较友好的。看完你觉得适合你入手一波吗?文章来源地址https://www.toymoban.com/news/detail-471531.html
到了这里,关于关于这款开源的ES的ORM框架-Easy-Es适合初学者入手不?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!