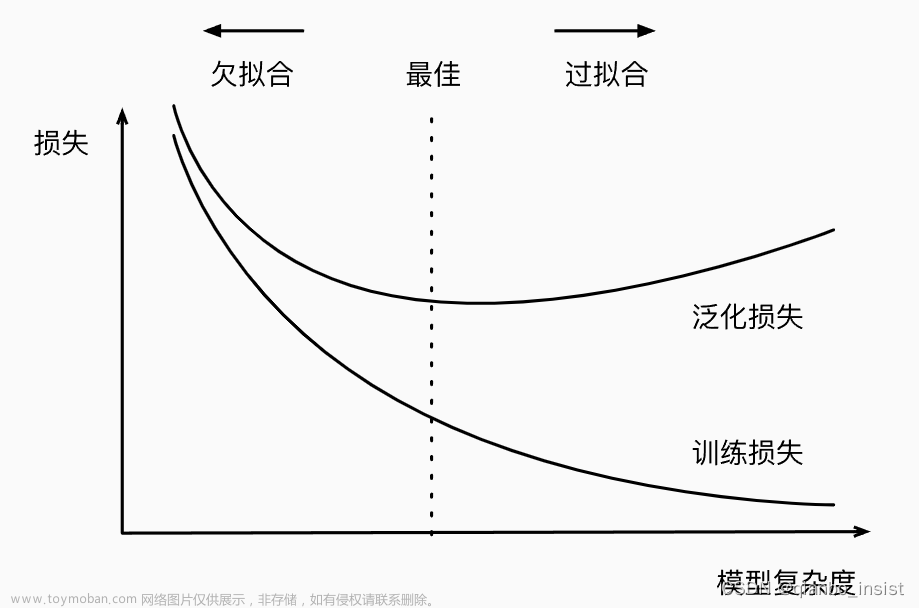
要点:
- 多项式回归模型的搭建
一 简介
R2(决定系数)和RMSE(均方根误差)是常用的回归模型评估指标,用于衡量模型对观测数据的拟合程度和预测精度。以下是它们的计算方法:
-
R2(决定系数): R2 表示模型对因变量的解释能力,取值范围从 0 到 1,越接近 1 表示模型对数据的拟合程度越好。
计算公式为: R2 = 1 - (SSR / SST) 其中,SSR 是回归平方和(Sum of Squares of Residuals),表示回归模型的拟合误差; SST 是总平方和(Total Sum of Squares),表示总体数据的离散程度。
R2 的计算结果越接近 1,说明模型能够较好地解释观测数据的变化,拟合效果较好。
-
RMSE(均方根误差): RMSE 表示模型预测值与实际观测值之间的差异,用于衡量模型的预测精度。
计算公式为: RMSE = sqrt(MSE) 其中,MSE 是均方误差(Mean Squared Error),表示预测值与观测值之间的平均误差的平方。
RMSE 的计算结果越小,表示模型的预测精度越高,预测值与实际观测值的差异较小。
二 求值方式
在使用机器学习框架或统计软件包进行建模时,通常可以通过相应的函数或方法来获取模型的 R2 和 RMSE 值。
以常见的Python机器学习库Scikit-learn为例,可以使用以下方法来获取 R2 和 RMSE 值:
-
R2(决定系数):
from sklearn.metrics import r2_score
# y_true为实际观测值,y_pred为模型预测值
r2 = r2_score(y_true, y_pred)
这将计算模型的 R2 值,其中 y_true 是实际观测值,y_pred 是模型的预测值。
-
RMSE(均方根误差):
from sklearn.metrics import mean_squared_error
# y_true为实际观测值,y_pred为模型预测值
rmse = mean_squared_error(y_true, y_pred, squared=False)
这将计算模型的 RMSE 值,其中 y_true 是实际观测值,y_pred 是模型的预测值。squared=False 参数表示返回的是均方根误差而不是均方误差。
这只是一个示例,具体的方法和函数可能因使用的工具或库而有所差异。在具体使用时,可以查阅所使用工具的文档或参考相应的函数说明来获取模型的 R2 和 RMSE 值。
三 非线性拟合
非线性回归是指将非线性模型应用于回归问题,其中因变量和自变量之间的关系不是线性的。非线性回归函数的选择通常取决于问题的特性和数据的分布。
以下是一些常见的非线性回归函数:
-
多项式回归: 多项式回归将自变量的多项式函数引入回归模型中,例如二次、三次或更高次的多项式。其形式为:
y = a0 + a1*x + a2*x^2 + a3*x^3 + ...其中
x是自变量,y是因变量,a0, a1, a2, a3, ...是回归系数。 -
指数回归: 指数回归将自变量以指数函数的形式引入回归模型中。其形式为:
y = a*exp(b*x)其中
x是自变量,y是因变量,a和b是回归系数。 -
对数回归: 对数回归将自变量以对数函数的形式引入回归模型中。其形式为:
y = a + b*log(x)其中
x是自变量,y是因变量,a和b是回归系数。 -
Sigmoid回归(逻辑回归): Sigmoid回归是一种常用的二分类非线性回归方法,它使用Sigmoid函数将线性组合的结果转换为概率值。其形式为:
y = 1 / (1 + exp(-(a + b*x)))其中
x是自变量,y是概率值,a和b是回归系数。
这只是非线性回归函数的一些示例,实际选择哪种函数取决于具体问题和数据的特征。还有其他许多非线性函数可供选择,您可以根据问题的需要进行调整和扩展。
四 多项式回归
多项式回归参考:多项式回归
线性回归研究的是一个目标变量和一个自变量之间的回归问题,但有时候在很多实际问题中,影响目标变量的自变量往往不止一个,而是多个,比如绵羊的产毛量这一变量同时受到绵羊体重、胸围、体长等多个变量的影响,因此需要设计一个目标变量与多个自变量间的回归分析,即多元回归分析。由于线性回归并不适用于所有的数据,我们需要建立曲线来适应我们的数据,现实世界中的曲线关系很多都是增加多项式实现的,比如一个二次函数模型:文章来源:https://www.toymoban.com/news/detail-471737.html
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt
import numpy as np
#X表示企业成本 Y表示企业利润
X = [[400], [450], [486], [500], [510], [525], [540], [549], [558], [590], [610], [640], [680], [750], [900]]
Y = [[80], [89], [92], [102], [121], [160], [180], [189], [199], [203], [247], [250], [259], [289], [356]]
print('数据集X: ', X)
print('数据集Y: ', Y)
#第一步 线性回归分析
clf = LinearRegression()
clf.fit(X, Y)
X2 = [[400], [750], [950]]
Y2 = clf.predict(X2)
print(Y2)
res = clf.predict(np.array([1200]).reshape(-1, 1))[0]
print('预测成本1200元的利润:$%.1f' % res)
plt.plot(X, Y, 'ks') #绘制训练数据集散点图
plt.plot(X2, Y2, 'g-') #绘制预测数据集直线
#第二步 多项式回归分析
xx = np.linspace(350,950,100) #350到950等差数列
quadratic_featurizer = PolynomialFeatures(degree = 2) #实例化一个二次多项式
x_train_quadratic = quadratic_featurizer.fit_transform(X) #用二次多项式x做变换
X_test_quadratic = quadratic_featurizer.transform(X2)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(x_train_quadratic, Y)
#把训练好X值的多项式特征实例应用到一系列点上,形成矩阵
xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_quadratic.predict(xx_quadratic), "r--",
label="$y = ax^2 + bx + c$",linewidth=2)
plt.legend()
plt.show()
这里我们使用R方(R-Squared)来评估多项式回归预测的效果,R方也叫确定系数(Coefficient of Determination),它表示模型对现实数据拟合的程度。计算R方的方法有几种,一元线性回归中R方等于皮尔逊积矩相关系数(Pearson Product Moment Correlation Coefficient)的平方,该方法计算的R方是一定介于0~1之间的正数。另一种是Sklearn库提供的方法来计算R方。R方计算代码如下:文章来源地址https://www.toymoban.com/news/detail-471737.html
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt
import numpy as np
#X表示企业成本 Y表示企业利润
X = [[400], [450], [486], [500], [510], [525], [540], [549], [558], [590], [610], [640], [680], [750], [900]]
Y = [[80], [89], [92], [102], [121], [160], [180], [189], [199], [203], [247], [250], [259], [289], [356]]
print('数据集X: ', X)
print('数据集Y: ', Y)
#第一步 线性回归分析
clf = LinearRegression()
clf.fit(X, Y)
X2 = [[400], [750], [950]]
Y2 = clf.predict(X2)
print(Y2)
res = clf.predict(np.array([1200]).reshape(-1, 1))[0]
print('预测成本1200元的利润:$%.1f' % res)
plt.plot(X, Y, 'ks') #绘制训练数据集散点图
plt.plot(X2, Y2, 'g-') #绘制预测数据集直线
#第二步 多项式回归分析
xx = np.linspace(350,950,100)
quadratic_featurizer = PolynomialFeatures(degree = 5)
x_train_quadratic = quadratic_featurizer.fit_transform(X)
X_test_quadratic = quadratic_featurizer.transform(X2)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(x_train_quadratic, Y)
#把训练好X值的多项式特征实例应用到一系列点上,形成矩阵
xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_quadratic.predict(xx_quadratic), "r--",
label="$y = ax^2 + bx + c$",linewidth=2)
plt.legend()
plt.show()
print('1 r-squared', clf.score(X, Y))
print('5 r-squared', regressor_quadratic.score(x_train_quadratic, Y))
# ('1 r-squared', 0.9118311887769025)
# ('5 r-squared', 0.98087802460869788)
到了这里,关于R2 和 RMSE的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!