故障模型
术语:
-
Fault:故障
- 指系统的缺陷,
- 系统有 Fault 不一定会发生错误。
-
Error:错误
- 指系统应该的状态与实际状态之间的差异,
- 系统激活了一个 Fault,进入了意外(Exception)状态。
-
Failure:失败(也翻译为故障)
- 指系统行为与其规约不一致,
- 如果系统抛出的意外被捕获,并且被容错处理,那么依然与规约一致。
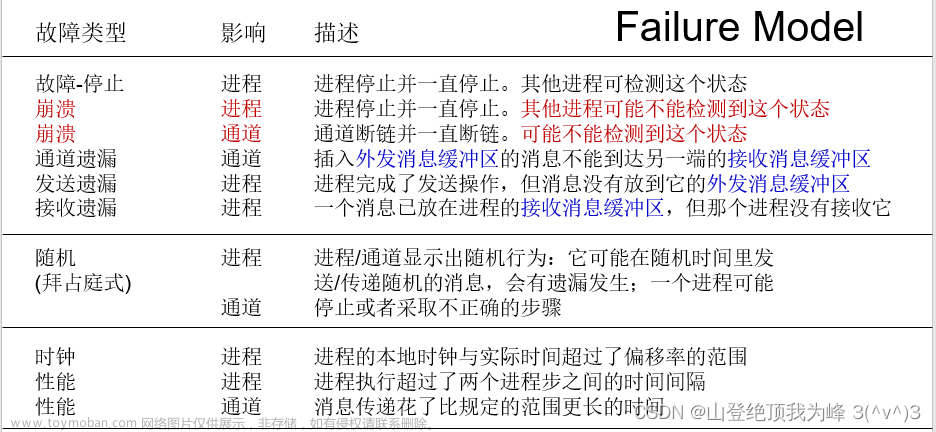
故障(Failure)的分类:
- 瞬态性 (Transient),间歇性 (Intermittent),永久性 (Permanent)
- 遗漏故障 (Omission Failure):崩溃 Crash,故障-停止 Fail-Stop;通道遗漏故障 Channel-Omission,发送遗漏故障 Send-Omission ,接收遗漏故障 Receive-Omission
- 随机故障 (Arbitrary/Byzantine Failure):拜占庭错误
- 时序故障:时钟故障 Clock Failure,进程性能故障 Process Performance Failure ,通道性能故障 Channel Performance Failure
故障检测:
- 被动式检测:在程序中设置检测点
-
主动式检测:
- 心跳 + 计时器(不可靠的故障检测器),指出进程可能出问题,但也可能是因为网络延迟。
- 不可靠的故障检测器 + 自适应地调整超时值(eventually weak failure detector ),可以在 通信可靠、崩溃进程不超过一半 的情况下达成共识。
故障屏蔽(容错):
- 信息冗余:校验和、签名
- 时间冗余:消息重传、事务
- 物理冗余:集群、复制
故障恢复:
- 故障恢复包括4个步骤:
- 故障诊断 (fault diagnosis)
- 故障隔离 (fault isolation)
- 系统重配置 (system reconfiguration)
- 系统重启 (system re-initialization)
- 恢复手段:
- 进程替换
- 进程迁移
可靠组播
可靠(reliable)通信,应该有以下两个基本性质,
-
有效性 (validity, liveness):在外发消息缓冲区的任何消息最终能被传递到接收消息缓冲区。
对有效性的威胁:
- 遗漏故障
- 接收者缓冲区满了,丢弃后续的消息
- 在信道上报文丢失
- 路由器故障
- 遗漏故障
-
完整性 (integrity, safety):接收到的消息与发送的消息一致,消息没有被传递两次。
对完整性的威胁:
- 通信协议允许重发消息,并且不拒绝到达两次的消息
- 可能有恶意用户插入伪造消息、重放旧的消息、篡改消息
基本组播不提供可靠性。我们定义可靠组播:
-
完整性 (Integrity, safety):一个正确的进程 p p p 传递一个消息 m m m 至多一次,其中 p ∈ g r o u p ( m ) p \in group(m) p∈group(m),消息发送者为 s e n d e r ( m ) sender(m) sender(m)
-
有效性 (Validity, liveness):如果一个正确的进程组播消息 m m m,那么它终将传递 m m m
-
协定 (Agreement, liveness):如果一个正确的进程传递了消息 m m m,那么在 g r o u p ( m ) group(m) group(m) 中的其它所有正确的进程也终将传递 m m m
-
有效性和协定一起得到一个全面的活性要求
-
协定条件与原子性(Atomicity)相关
-
基于基本组播
基本组播( s e n d send send 是可靠的 one-to-one 操作,但本进程可能会 crash 从而只完成一部分发送):
- B − m u l t i c a s t ( g , m ) B-multicast(g,m) B−multicast(g,m):对于每个 p ∈ g p \in g p∈g,分别执行 s e n d ( p , m ) send(p,m) send(p,m)
- r e c e i v e ( m ) receive(m) receive(m):在 p p p 上收到 m m m,然后 B − d e l i v e r ( m ) B-deliver(m) B−deliver(m)
可靠组播:
- 初始化:设置 r e c e i v e d : = { } received := \{\} received:={}
- R − m u l t i c a s t ( g , m ) R-multicast(g,m) R−multicast(g,m):进程 p p p 执行 B − m u l t i c a s t ( g , m ) B-multicast(g,m) B−multicast(g,m)(包括自己)
-
B
−
d
e
l
i
v
e
r
(
m
)
B-deliver(m)
B−deliver(m):
- 如果
m
∉
r
e
c
e
i
v
e
d
m \not \in received
m∈received,那么
- 设置 r e c e i v e d : = r e c e i v e d ∪ { m } received := received \cup \{m\} received:=received∪{m}
- 如果来源 q ≠ p q \neq p q=p,那么执行 B − m u l t i c a s t ( g , m ) B-multicast(g,m) B−multicast(g,m)
- 最后,执行 R − d e l i v e r ( m ) R-deliver(m) R−deliver(m)
- 否则,什么也不做
- 如果
m
∉
r
e
c
e
i
v
e
d
m \not \in received
m∈received,那么
可以证明,上述算法满足协定,正确进程终将(不对完成时间做任何保证)一起传递消息 m m m
基于 IP 组播
每个进程 p p p 维持两个变量:
- S g p S_g^p Sgp:进程 p p p 发送到组 g g g 中的消息数
- R g q R_g^q Rgq:进程 p p p 已传递的由进程 q q q 发送到到组 g g g 中的顺序数
算法如下:
-
R
−
m
u
l
t
i
c
a
s
t
(
g
,
m
)
R-multicast(g,m)
R−multicast(g,m):
- 组播消息时,捎带上序号以及确认
- 调用 m u l t i c a s t ( g , ⟨ m , S g p , a c k = [ q , R g q ] q ∈ g ⟩ ) multicast(g,\langle m,S_g^p,ack=[q,R_g^q]_{q \in g} \rangle) multicast(g,⟨m,Sgp,ack=[q,Rgq]q∈g⟩)
- 设置 S g p = S g p + 1 S_g^p = S_g^p+1 Sgp=Sgp+1
-
d
e
l
i
v
e
r
(
m
)
deliver(m)
deliver(m):
- 进程 r r r 收到来自 p p p 的消息 ⟨ m , S , a c k ⟩ \langle m,S,ack \rangle ⟨m,S,ack⟩
- 如果 S = R g p + 1 S = R_g^p+1 S=Rgp+1,那么是预期的消息,于是 R − d e l i v e r ( m ) R-deliver(m) R−deliver(m),接着立刻 R g p : = S R_g^p := S Rgp:=S
- 如果 S < R g p + 1 S < R_g^p+1 S<Rgp+1,那么这条消息已经传递过,简单丢弃它
- 如果
S
>
R
g
p
+
1
S > R_g^p+1
S>Rgp+1 或者存在某些确认
(
q
,
R
)
(q,R)
(q,R) 使得
R
>
R
g
q
R>R_g^q
R>Rgq,那么说明自己遗漏了某些消息,
- 进程 r r r 将 ( S , m ) (S,m) (S,m) 放入保留队列,直到 S = R g p + 1 S = R_g^p+1 S=Rgp+1 时再传递它
- 发送否定确认,来请求丢失的那些消息(或者给 p p p 或者给 q q q)
上述算法满足:完整性、有效性、协定
协定问题
协定(Agreement)问题,包括:
- 一致性(Consensus)问题
- 拜占庭将军(Byzantine generals)问题
- 交互一致性(Interactive Consistency)问题
Consensus
问题的定义:
- 每个进程 p i p_i pi 都处于未决状态,并提议一个值 v i ∈ D v_i \in D vi∈D
- 进程间相互通信,最后各进程设置决定变量(decision variable) d i d_i di
- d i d_i di 可以是 major,也可以是 min 或者 max,或者其他什么值
故障类型:崩溃故障(Crash Failures)
算法必须具有的特性:
- 终止性:每个正确进程最终设置它的决定变量
- 协定性:所有正确进程的决定值都相同
- 完整性:如果正确的进程都提议相同的值,那么处于决定状态的任何正确进程已选择了该值
同步系统中的一致性算法:假定 N N N 个进程中至多有 f f f 个进程同时崩溃,
- 初始化:
- 设置 v a l u e s i 0 : = { } values_i^0 := \{\} valuesi0:={}
- 设置 v a l u e s i 1 : = { v i } values_i^1 := \{v_i\} valuesi1:={vi}
- 第
r
=
1
,
⋯
,
f
,
f
+
1
r=1,\cdots,f,f+1
r=1,⋯,f,f+1 轮通信:
- 执行 B − m u l t i c a s t ( g , v a l u e s i r − v a l u e s i r − 1 ) B-multicast(g,values_i^{r}-values_i^{r-1}) B−multicast(g,valuesir−valuesir−1)
- 设置 v a l u e s i r + 1 : = v a l u e s i r values_i^{r+1} :=values_i^r valuesir+1:=valuesir
- 在本轮中不断收集 B − d e l i v e r ( v j ) B-deliver(v_j) B−deliver(vj),并设置 v a l u e s i r + 1 : = v a l u e s i r + 1 ∪ { v j } values_i^{r+1} :=values_i^{r+1} \cup \{v_j\} valuesir+1:=valuesir+1∪{vj}
- 第 f + 1 f+1 f+1 轮通信结束后:做决策 d i = d e c i d e ( v a l u e s i f + 1 ) d_i = decide(values_i^{f+1}) di=decide(valuesif+1)
Byzantine generals
问题的定义:
- 有一个将军(commanding general),发送指令给他的副将(lieutenant generals)
- IC1:All loyal lieutenants obey the same order.
- IC2:If the commanding general is loyal, then every loyal lieutenant obeys the order he sends.
- Conditions IC1 and IC2 are called the interactive consistency conditions. Note that if the commander is loyal, then IC1 follows from IC2.
故障类型:随机故障(Byzantine Failure)
算法必须具有的特性:
- 终止性:每个正确进程最终设置它的决定变量
- 协定性:所有正确进程的决定值都相同
- 完整性:如果司令进程是正确的,那么所有正确的进程都采取司令提议的那个值
算法:https://blog.csdn.net/weixin_44885334/article/details/126487783
Interactive Consistency
这是拜占庭将军问题的推广:
- 每个进程都提供一个值
- 正确的进程最终就一个向量达成一致,向量中的分量与每一个进程的值对应
- 这个向量称为决定向量 (decision vector)
故障类型:随机故障(Byzantine Failure)
算法必须具有的性质:
- 终止性:每个正确进程最终设置它的决定变量
- 协定性:所有正确进程的决定向量都相同
- 完整性:如果进程 p i p_i pi 是正确的,那么所有正确的进程都把 v i v_i vi 作为它们决定向量中的第 i i i 个分量
算法:每个进程都作为主将,把其他进程作为副官,调用 n n n 次拜占庭将军算法。
FLP 不可能定理
- 同步系统中的共识问题:如果有至多 f f f 个进程 crash,那么必须进行 f + 1 f+1 f+1 轮信息交换
- 同步系统中的 BFT:如果有至多 f f f 个进程出现随机故障,那么必须有 N ≥ 3 f + 1 N \ge 3f+1 N≥3f+1 个进程才会有解
- Consensus 问题、Byzantine generals 问题、Interactive Consistency 问题,三者可以互相转化
异步系统的不可能性(FLP, 1985):
- 在一个异步系统中,即使是只有一个进程出现崩溃故障,也没有算法能够保证达到共识。
- 在异步系统中,没有可以确保的方法来解决拜占庭将军问题、交互一致性问题、全排序可靠组播问题。
绕过不可能性结论的三个方法:
- 故障屏蔽:事务系统,使用持久储存来保存信息。
- 故障检测器:即使是不可靠的故障检测器,只要通信是可靠的,且崩溃的进程不超过 N / 2 N/2 N/2,那么异步系统中的 Consensus 是可以解决的。
- 随机化:随机化进程各方面的行为,使得破坏进程者不能有效地实施阻碍战术 。
分布式恢复
后向恢复
Backward Recovery:将系统从当前的错误状态,回滚,回到先前的正确状态。
优点:普遍适用的机制
缺点:成本高、恢复周期长、某些状态无法回滚
Checkpointing Algorithm
检查点,就是进程记录下这一时刻的自身状态,放在 local stable storage 里。
- 当某个进程 failure 之后,可以根据最近检查点的信息,使得自身恢复到先前的某个状态上。
- 接着,需要判断各个进程的检查点,是否形成了一个一致的割集的边界。
- 如果不是一致割集,那么就需要进一步回滚,直到检查点组成了一个一致的割集。
- 如果检查点生成的不好,那么很可能出现多米诺效应(Domino effect),一直回滚到初始状态,使得恢复时间漫长。
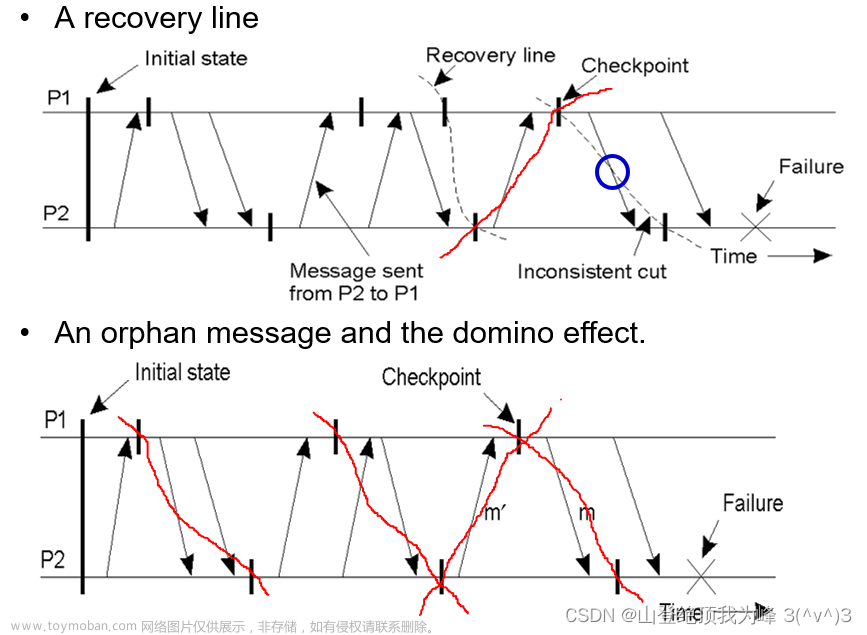
根据时机、频率、信息量的不同,可以分为多种检查点:
- Synchronous checkpointing:所有进程协作,把自身状态记录到磁盘里。
- Asynchronous checkpointing:各个进程独立地记录自身状态。
Coordinated Checkpointing
- 非阻塞方法(non-blocking method):分布式快照算法(Chandy-Lamport’s Snapshot),其他进程不需要等待快照完成。
- 两阶段阻塞协议(two-phase blocking protocal):
- 需要一个选举产生的协调者(coordinator)来多播 checkpoint request,开始 checkpointing
- 进程做 local checkpointing,在这期间要把正在执行的应用的后续消息进行排队(挂起其他任务),结束后发送 acknowledges 给协调者
- 协调者多播 checkpoint done,结束 checkpointing
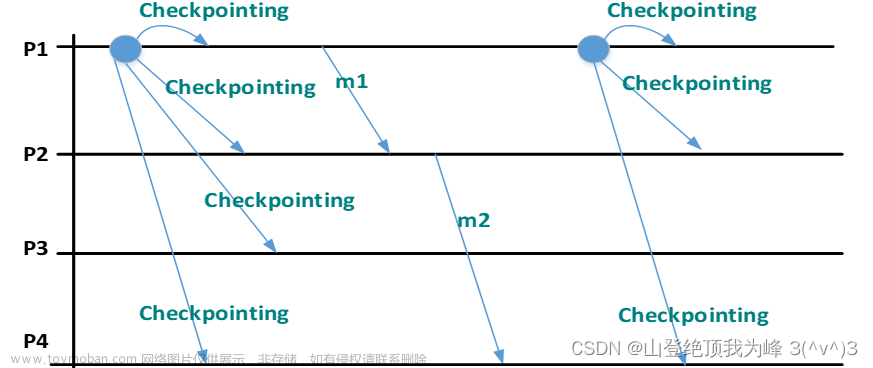
两阶段阻塞协议的优化:增量式快照(Incremental snapshot)
- 协调者只发送 checkpoint request 给那些依赖于协调者本地记录的那些进程(those processes that depend on the recovery of the coordinator),也就是自从协调者上次 checkpoint 之后发送消息给它们的那些进程
- 进程收到 checkpoint request 后,同样转发给那些依赖于自身本地记录的那些进程(those processes to which P itself had sent a message since the last checkpoint)
- 这些受影响进程做的新检查点,以及其他进程原本的检查点,共同构成了一个一致的割集(不过,这个割集是稍微旧了一点?比如协调者发消息频率较低,而其他进程间交流频繁)
Independent Checkpointing
定义一些变量:
- C P [ i ] ( m ) CP[i](m) CP[i](m):进程 P i P_i Pi 做的第 i i i 个检查点
- I N T [ i ] ( m ) INT[i](m) INT[i](m):在两个检查点 C P [ i ] ( m − 1 ) CP[i](m-1) CP[i](m−1) 与 C P [ i ] ( m ) CP[i](m) CP[i](m) 之间的时间区间
进程 P i P_i Pi 记录,在 I N T [ i ] ( m ) INT[i](m) INT[i](m) 期间,发送了消息给哪些进程
进程 P j P_j Pj 记录,时间间隔的因果序 I N T [ i ] ( m ) → I N T [ j ] ( n ) INT[i](m) \to INT[j](n) INT[i](m)→INT[j](n)
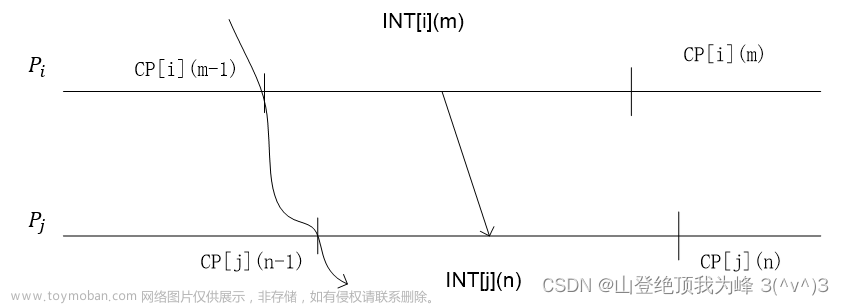
如图,在 I N T [ i ] ( m ) INT[i](m) INT[i](m) 期间 P i P_i Pi 发送了消息给 P j P_j Pj 的 I N T [ j ] ( n ) INT[j](n) INT[j](n) 区间。当进程 P i P_i Pi 回滚到检查点 C P [ i ] ( m − 1 ) CP[i](m-1) CP[i](m−1) 时,为了获得一致的割集,需要保证 P j P_j Pj 回滚到 I N T [ j ] ( n ) INT[j](n) INT[j](n) 之前的 C P [ j ] ( n − 1 ) CP[j](n-1) CP[j](n−1) 检查点。
因此,算法如下:
- 故障的进程 Q Q Q 通过 restore 最近的检查点来 recover
- 如果 Q Q Q 在做了最近检查点之后,没有发送消息给其他进程,那么 recovery 结束
- 如果 Q Q Q 在做了最近检查点之后,发送了消息 m m m 给某个进程 P P P(那么当前的全局状态是 P P P 接收到了 Q Q Q 还没发送的消息 m m m),需要发消息给 P P P 让它回滚(roll back)
- 如果 P P P 需要回滚,那么就 restore 之前的最近检查点,然后同样通知在这期间发送过消息的那些进程,让它们也回滚
在 Independent Checkpointing 中,多米诺效应难以避免。通过写发送日志、接收日志,可以一定程度上缓解多米诺效应。
Message Logging Algorithm
日志系统用在 a piecewise deterministic model 中:进程接收到消息后,其执行是确定的,no clock,no random number。
当进程 Q Q Q 从故障中恢复时,
- 重载最近的检查点,
- 读取日志中接收到的消息(replaying the log)重新执行程序,
- 此时,进程 Q Q Q 的状态恢复到了 检查点之后,接收到日志中的最后一条消息后 的位置,这是割集的一个边界点(全局状态,包括当前的进程状态,以及日志中记录的信息)。
Orphan messages(孤儿消息):一个消息 m m m,它已经被接收,但还没有被发送。
Orphan process(孤儿进程):一个进程 P P P,它在另一个进程 Q Q Q crash 然后 recover 后,进程 P P P 的状态与 Q Q Q 的不一致。
- D E P ( m ) DEP(m) DEP(m):已经 deliver 消息 m m m 的那些进程的集合
- C O P Y ( m ) COPY(m) COPY(m):持有消息 m m m 的备份的那些进程的集合
- 一个进程 R R R 成为孤儿,如果它属于 D E P ( m ) DEP(m) DEP(m),同时 C O P Y ( m ) COPY(m) COPY(m) 中所有的进程全部 crash 了。此时的 replay 是不正确的。
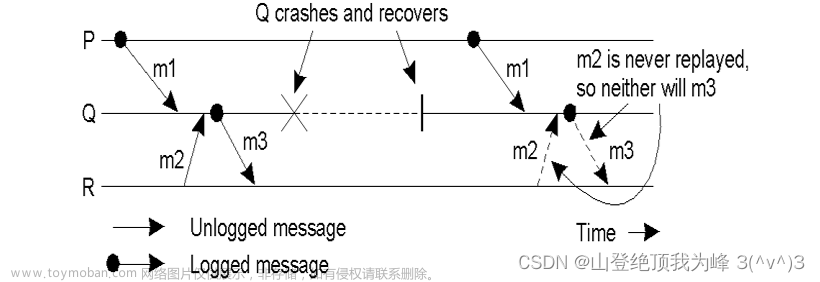
如上图所示,使用接收日志。进程 Q Q Q 记录了 m 1 m_1 m1,但没有记录 m 2 m_2 m2,因此不会 replay “接收到 m 2 m_2 m2” 这个事件,当然也就不会再发送 m 3 m_3 m3 了。但是, m 3 m_3 m3 却被进程 R R R 记录在了 log 里。 m 3 m_3 m3 是孤儿消息, R R R 是孤儿进程。
Pessimistic message logging
悲观的消息日志:接收到的消息,在被进程执行(processing)之前,首先保存(saving)到日志里。
- 为了避免孤儿进程,如果一个进程依赖于 m m m 的传递,那么 m m m 需要被备份(a copy of m m m)
- 进程 Q Q Q 在被传递了 m m m 之后,除非已经把 m m m 写入日志,不允许发送任何消息(先 store 影响自己的消息,再 send 自己的消息去影响别人)
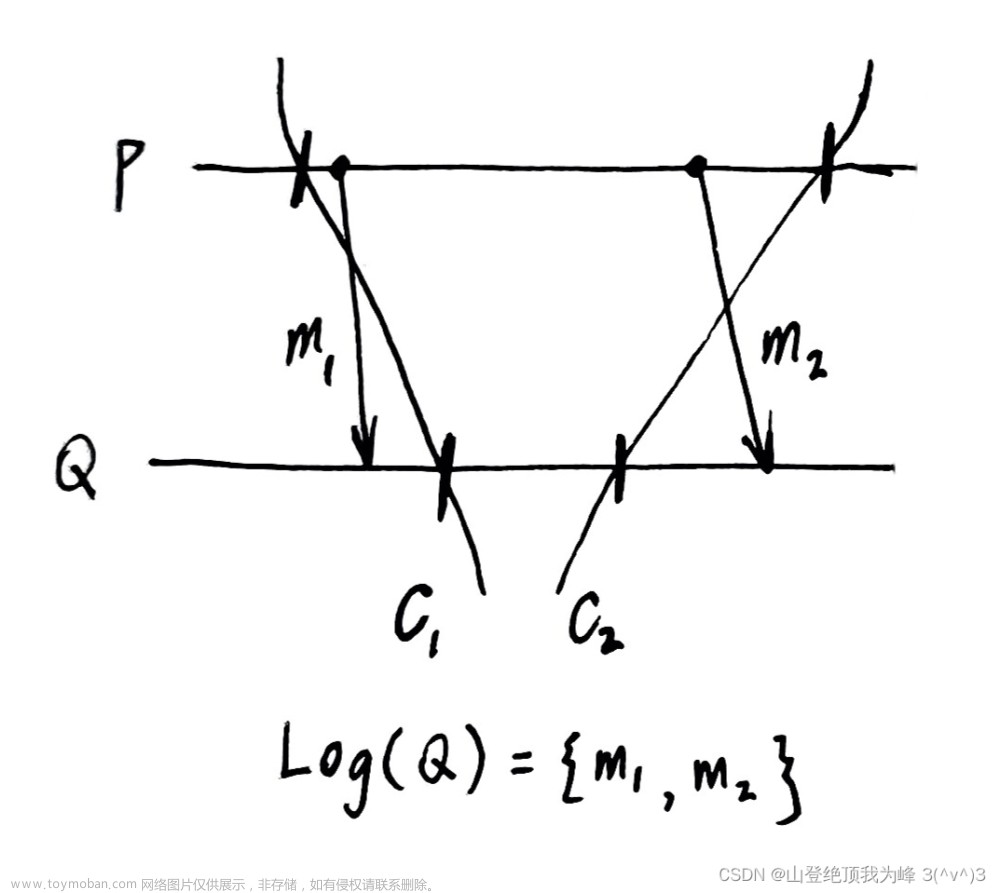
进程崩溃后恢复,
- 如果恢复到了形如 C 1 C_1 C1 的割集上,由于 Q Q Q 的日志记录了 m 1 m_1 m1,因此这是一致的状态
- 如果恢复到了形如 C 2 C_2 C2 的割集上,它本身就是一致状态。然后 Q Q Q 可以依据日志里的 m 2 m_2 m2 直接 replay, P P P 不必重传 m 2 m_2 m2
因此,检查点 + 悲观的接收日志,组成了一致的全局状态。不会出现多米诺效应!
Optimistic message logging
乐观的消息日志:接收到的消息,它的执行、保存是独立的。
- 如果 processing 之前首先 logging,由于磁盘 I/O 延迟,性能会很差。
- 频率需要控制好:
- 每次接收到消息,就异步执行 logging 操作,然后执行进程。这近似于悲观的消息日志,速度慢。
- Batching messages,分批 logging 它们。如果恰好在检查点之前记录,就和没有日志一样差了。
如果一个消息 m m m 还没被 log,进程 P P P 就 crash 了,在恢复后, P P P 根据日志中的信息没法完成 replay,在接收 m m m 之后发送消息 m ′ m' m′,将会使得其他那些收到 m ′ m' m′ 的进程成为 orphans。因此, P P P 必须额外记录一个关于 D E P ( m ) DEP(m) DEP(m) 的 track,让这些孤儿进程全部 roll back。
多米诺效应依然可能出现,但是被抑制(restricted)了。
State Interval Model
我们需要判断一个全局状态是否是一致状态(没有孤儿消息)的算法。
分布式系统中,一共有 N N N 个进程 P i P_i Pi,各自维护一个长度为 N N N 的关于 event 的向量时钟 V i V_i Vi
一个全局状态
S
S
S,其割集边界上的 vector clock,按顺序排列成矩阵,叫做 Dependency Matrix:
D
(
S
)
=
[
V
1
[
1
]
V
1
[
2
]
⋯
V
1
[
N
]
V
2
[
1
]
V
2
[
2
]
⋯
V
2
[
N
]
⋮
V
N
[
1
]
V
N
[
2
]
⋯
V
N
[
N
]
]
D(S) = \begin{bmatrix} V_1[1] & V_1[2] & \cdots & V_1[N]\\ V_2[1] & V_2[2] & \cdots & V_2[N]\\ \vdots\\ V_N[1] & V_N[2] & \cdots & V_N[N]\\ \end{bmatrix}
D(S)=
V1[1]V2[1]⋮VN[1]V1[2]V2[2]VN[2]⋯⋯⋯V1[N]V2[N]VN[N]
规则:state S S S is consistent if and only if all diagonal elements dominate the columns(主对角线是所在列向量的最大元)
状态区间(State interval):
- 它是一个关于某一个进程上的事件序列,拥有自己的 state interval index
- 它开始于一个消息的接收,结束于下一个消息的接收
- 它包含:第一个接收事件,第二个接收事件,第一个消息;但是,不包含第二个消息
- 每个消息携带对应的状态区间的 index,每个状态区间携带一个 dependency vector(类似于 event 的向量时钟,但只考虑 receiving events)
进程 P i P_i Pi 持有 C i [ 1 ⋯ N ] C_i[1 \cdots N] Ci[1⋯N],
- C i [ i ] C_i[i] Ci[i] 记录进程 P i P_i Pi 发送出去的消息数
- C i [ j ] C_i[j] Ci[j] 记录进程 P i P_i Pi 接收到的来自进程 P j P_j Pj 的消息数
- 每当发送消息 m m m 时,携带上自己的 C i C_i Ci,然后 C i [ i ] : = C i [ i ] + 1 C_i[i] := C_i[i]+1 Ci[i]:=Ci[i]+1
- 每当接收到来自 P j P_j Pj 的消息 ( m , C ) (m,C) (m,C),设置 C i : = max ( C i , C ) C_i := \max(C_i,C) Ci:=max(Ci,C),然后 C i [ j ] : = C i [ j ] + 1 C_i[j] := C_i[j]+1 Ci[j]:=Ci[j]+1
一个孤儿消息
m
m
m,发送方
P
i
P_i
Pi 还没发送,但是接收方
P
j
P_j
Pj 已经接收。因此它的特征就是,
C
i
[
i
]
<
C
j
[
i
]
C_i[i] < C_j[i]
Ci[i]<Cj[i],
P
j
P_j
Pj 知道的关于
P
i
P_i
Pi 的信息,反倒比
P
i
P_i
Pi 自己知道的还要多。同样定义 Dependency Matrix,
D
(
S
)
=
[
C
1
[
1
]
C
1
[
2
]
⋯
C
1
[
N
]
C
2
[
1
]
C
2
[
2
]
⋯
C
2
[
N
]
⋮
C
N
[
1
]
C
N
[
2
]
⋯
C
N
[
N
]
]
D(S) = \begin{bmatrix} C_1[1] & C_1[2] & \cdots & C_1[N]\\ C_2[1] & C_2[2] & \cdots & C_2[N]\\ \vdots\\ C_N[1] & C_N[2] & \cdots & C_N[N]\\ \end{bmatrix}
D(S)=
C1[1]C2[1]⋮CN[1]C1[2]C2[2]CN[2]⋯⋯⋯C1[N]C2[N]CN[N]
规则是:如果主对角线元素 C i [ i ] C_i[i] Ci[i] 不是所在列向量的最大元,那么这一列上更大的元素 C j [ i ] > C i [ i ] C_j[i]>C_i[i] Cj[i]>Ci[i],对应的 P j P_j Pj 就是孤儿进程。
我们说一个状态区间是稳定的(stable),如果离它最近的 checkpoint 以及它的 starting message 之间,所有的接收到的消息都已经完成了 logging。容易看出,进程 crash 之后 recover,加载最近的检查点,然后可以根据接收日志,重构这个稳定的状态区间。
我们说一个全局状态是可恢复的(recoverable),如果所有的状态区间都是稳定的。容易看出,进程 crash 之后 recover,能够重构这个可恢复的全局状态,但是还需要检查一致性。
前向恢复
Forward Recovery:将系统从当前的错误状态,继续执行,到达一个新的正确状态。
缺点:必须预先知道可能会发生哪些错误
分布式系统的所有可能的配置(configurations)集合,可以分为两类:合法的(legal)、非法的(illegal)
- 在一个非响应系统(nonreactive system)里,合法的配置被表示为全局状态的不变式(an invariant over the global state)
- 在一个响应系统(reactive system)里,合法的配置并不仅仅取决于状态谓词(state predicate),还取决于行为(behaviors)
Stabilizing Algorithm
一个系统被称为自稳定的(Stabilizing),如果
- 收敛性(Convergence):无论初始状态,也无论执行每一步所选择的动作,系统终将回到合法配置(eventually returns to a legal configuration)
- 封闭性(Closure):一旦进入合法配置,系统将会持续位于合法配置,直到出现 failure 或者 corrupt
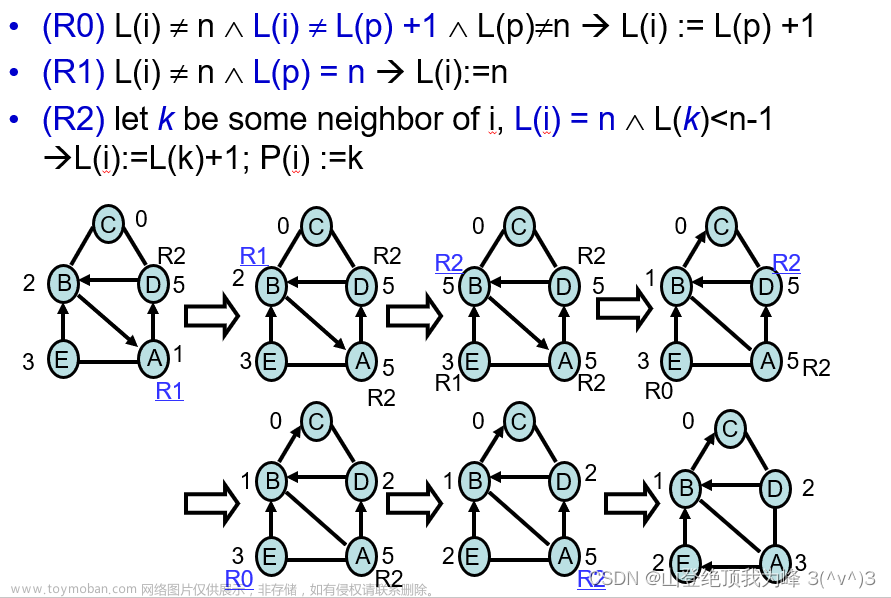
对于一个生成树(Spanning Tree) G = ( V , E ) G=(V,E) G=(V,E),定义
- L ( i ) L(i) L(i):节点 i i i 的层级(level),令树根有 L ( r ) = 0 L(r)=0 L(r)=0
- P ( i ) P(i) P(i):节点 i i i 的父节点(parent)
生成树的合法状态:图 G G G 是一个生成树,且除了 root 以外的每个节点的 level,都等于它的父节点 level 加一。
对应的不变式: G S T = ( ∀ i , i ≠ r ∧ p = P ( i ) : L ( i ) = L ( p ) + 1 ) GST = (\forall i,\, i\neq r \wedge p=P(i):\, L(i)=L(p)+1) GST=(∀i,i=r∧p=P(i):L(i)=L(p)+1)
 文章来源:https://www.toymoban.com/news/detail-472527.html
文章来源:https://www.toymoban.com/news/detail-472527.html
生成树的自稳定算法如图所示,每一步随机挑选一条规则 R 0 , R 1 , R 2 R_0,R_1,R_2 R0,R1,R2 来执行,最终 G G G 会满足 G S T GST GST 谓词。文章来源地址https://www.toymoban.com/news/detail-472527.html
到了这里,关于分布式系统(故障、恢复)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!