1、引入相关maven依赖
这里我的springboot的版本为2.2.0.RELEASE(这里使用springboot开发的,不是的话用main方法跑也一样的,springboot的话只是为了方便后期存数据到数据库)
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.8.1</version>
</dependency>
2、下载相关浏览器驱动这是介绍Chrome和Edge浏览器
chrome浏览器的下载地址:https://chromedriver.storage.googleapis.com/index.html
Edge的驱动下载地址为:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
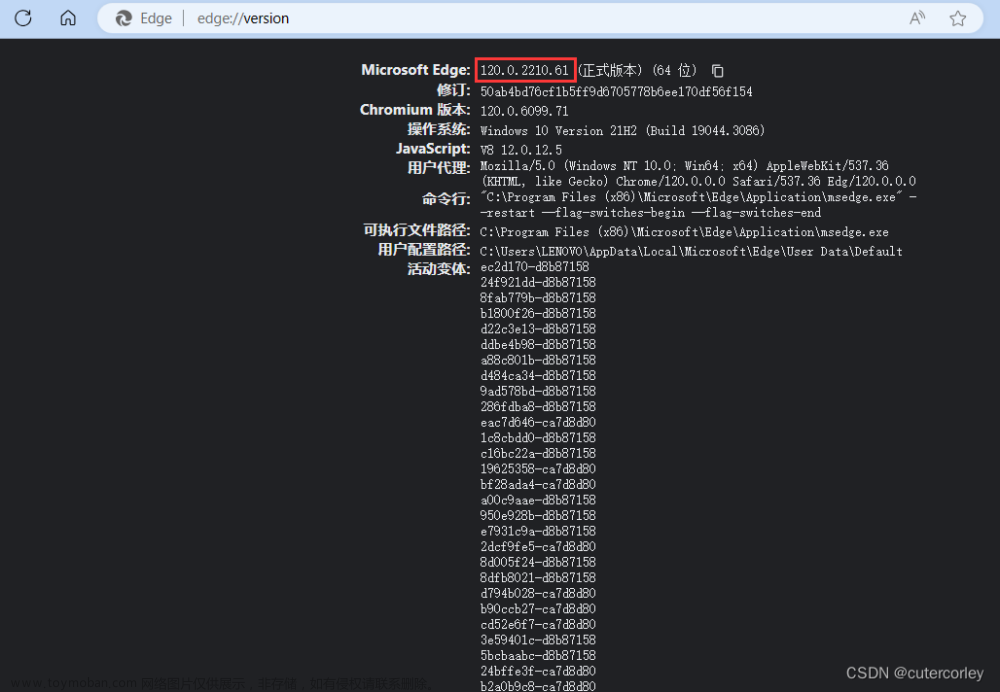
!!!!!下载驱动之前检查自己浏览器的版本号为多少,下载对应版本的驱动,不然会导致程序无法调用浏览器
3、调用浏览器(以下代码均可以直接在你的main方法中直接运行)
//设置自己刚才下载的驱动程序的位置
System.setProperty("webdriver.chrome.driver", "C:\\Users\\Administrator\\Desktop\\chromedriver.exe");
//创建一个驱动器对象
//也可以创建Edge的驱动对象,总之都是一个套路
//EdgeDriver edgeDriver = new EdgeDriver();//创建的edgedriver
ChromeDriver chromeDriver = new ChromeDriver();
//ChromeDriver对象可以获取到很多的信息,可以自行试一下
//浏览器访问某个地址
chromeDriver.get("www.baidu.com");
4、常见操作(后续我遇到之后也会继续更新)
4.1 获取网页元素的方法
//chromeDriver.findElement()为查询某个元素,当有多个时候只会返回第一个对象
//chromeDriver.findElements()方法可以查找元素列表
//以上两种方式都是从浏览器的根节点出发来找元素的
//获取到的WebElement对象都可以继续进行findElement()或者findElements()的操作,这个是从当前元素出发开始寻找WebElement对象
//参数有By.id(),By.tagName(),By.xpath()等,可以使用不同的方式来定位
WebElement body= chromeDriver.findElement(By.tagName("body"));//寻找html页面上的第一个body标签的元素
List<WebElement> divs = body.findElements(By.tagName("div"));//查找所有body标签下的div元素
//一般情况下可以通过以上这两种方法的组合获取到页面的任何一种元素
4.2 执行网页的js代码并取到js的返回值
//执行document.body.scrollHeight并将返回值拿到(获取body标签的高度)
Long totalHeight = (Long) chromeDriver.executeScript("return document.body.scrollHeight")
//有些操作在java里面操作特别麻烦,但是在js中操作可能就会简单很多,可以直接执行js的代码
//网页向下滚动
chromeDriver.executeScript("window.scrollTo(0,100)");//无需返回值的时候就不需要进行return
4.3 鼠标移动到某一元素,并点击(一些简单的模拟登录就会需要这个操作)
//先定位到登录按钮的元素
WebElement loginButton= chromeDriver.findElement(By.id("login_id"));
//鼠标移动到该元素上然后点击
Actions actions = new Actions(webDriver);//操作对象,里面有很多的鼠标、键盘动作可自行试一下
actions.moveToElement(loginButton).click().perform();
4.4 滚动页面,在解决滚动加载时是个好办法
//实际上也是来执行js代码进行滚动网页的
//获取到body的高度
//然后滚动到最下方
Long totalHeight = (Long) chromeDriver.executeScript("return document.body.scrollHeight");
chromeDriver.executeScript("window.scrollTo(0," + totalHeight + ")");
5、常见的坑!!!!!!
5.1 网页没有加载完获取元素时会失败
当元素加载未完成的时候,html并没有当前的元素节点,获取不到就是报错(这样我感觉很奇怪,但没办法人家就是这么设计的)
解决办法:
5.1.1 在chromeDriver.get(“www.baidu.com”)方法执行完之后,线程休眠一段时间,等他加载完,但是这样就显得很不智能,不过确实是一个办法
Thread.sleep(2000);//具体休眠时间看你电脑网速,还是有加载完网页的时间,预估一下就行
5.1.2 全局生效,每次获取元素的时候都会等5秒(根据你自己需要设置),一旦元素出现就会继续执行下去。只需要设置一次就行了,driver实例被关闭后也就消失。
这种方式程序只会等到页面加载完了(浏览器上那个小圈圈不转了)才会去执行下面代码,如果有时候页面大部分元素都加载完了,只有极个别元素,这样就很浪费时间
chromeDriver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
5.1.4 指定某个元素出现再去执行操作
//设置超时时间为10秒
WebDriverWait wait = new WebDriverWait(webDriver, 10);
//一直等到body元素出现后再去执行下面的操作
wait.until(ExpectedConditions.presenceOfAllElementsLocatedBy(By.id("body")));
5.2 有些元素在iframe标签下面,导致获取不到
使用代码,将chromeDriver切换到iframe里面
有些网页可能有多层的iframe这时就需要进行一层一层的切进去,但是切出来只需要一下就好文章来源:https://www.toymoban.com/news/detail-472712.html
5.2.1 如果iframe标签有name或者id的话
//直接切换到他frame()方法的参数为iframe的name或者id
chromeDriver.switchTo().frame("");
5.2.2 iframe当作一个元素进行切换
//找到iframe的标签
WebElement iframe = driver.findElement(By.tagName("iframe"));
//切换到改iframe
chromeDriver.switchTo().frame(iframe);
5.2.3切出iframe
chromeDriver.switchTo().defaultContent();
5.3 解决一些selenium识别的反爬
5.3.1 禁用启用Blink运行时的功能
window.navigator.webdriver的值设置为false文章来源地址https://www.toymoban.com/news/detail-472712.html
options.addArguments("--disable-blink-features=AutomationControlled");
chromeDriver.executeScript("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})", "");
到了这里,关于JAVA使用selenium的常见爬虫操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[爬虫]2.2.1 使用Selenium库模拟浏览器操作](https://imgs.yssmx.com/Uploads/2024/02/594545-1.jpg)