爬虫5步曲:
1.安装requests and beacutifulsoup4库
2.获取爬虫所需的header 和cookie
3.获取网页,解析网页
4.分析得到的数据简化地址
5.爬取内容,清洗数据
1.安装requests&beautifulsoup4
pip3 install requests
pip3 install beautifulsoup4
2.获取爬虫所需的header 和cookie
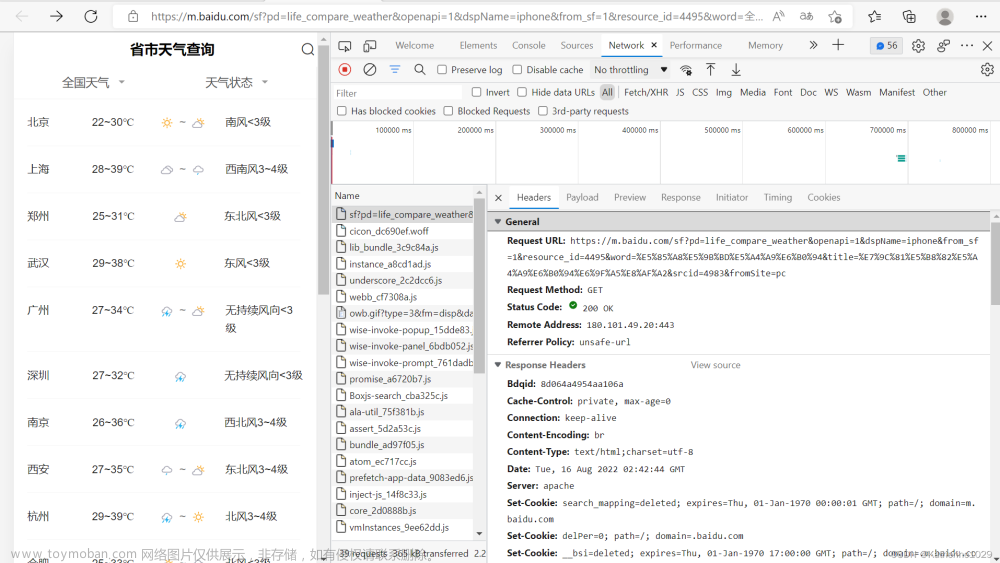
打开想爬取的网页后按下F12打开开发者模式,就会出现网页的js语言设计部分。如下图所示。找到网页上的Network部分。然后按下ctrl+R刷新页面。如果,进行就有文件信息,就不用刷新了,当然刷新了也没啥问题。然后,我们浏览Name这部分,找到我们想要爬取的文件,鼠标右键,选择copy,复制下网页的URL。就如下图所示。
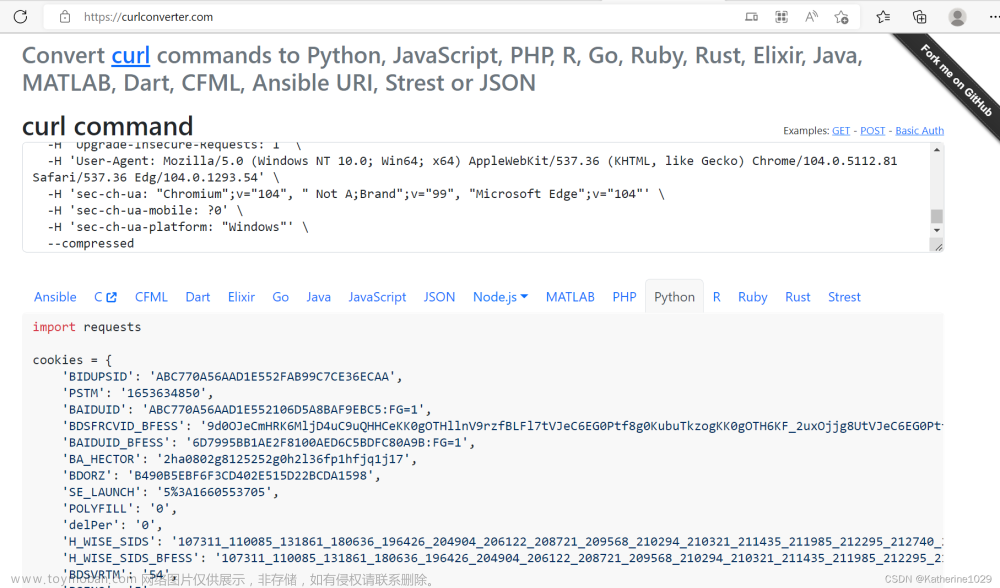
复制好URL后,我们就进入Convert curl commands to code (curlconverter.com)。这个网页可以根据你复制的URL,自动生成header和cookie,如下图。生成的header和cookie,直接复制走就行,粘贴到程序中。
3.获取网页,解析网页
我们将header和cookie搞到手后,就可以将它复制到我们的程序里。之后,使用request请求,就可以获取到网页了。这个时候,我们需要回到网页。同样按下F12进入开发者模式,找到网页的Elements部分。用左上角的小框带箭头的标志,如下图,点击网页内容,这个时候网页就会自动在右边显示出你获取网页部分对应的代码。
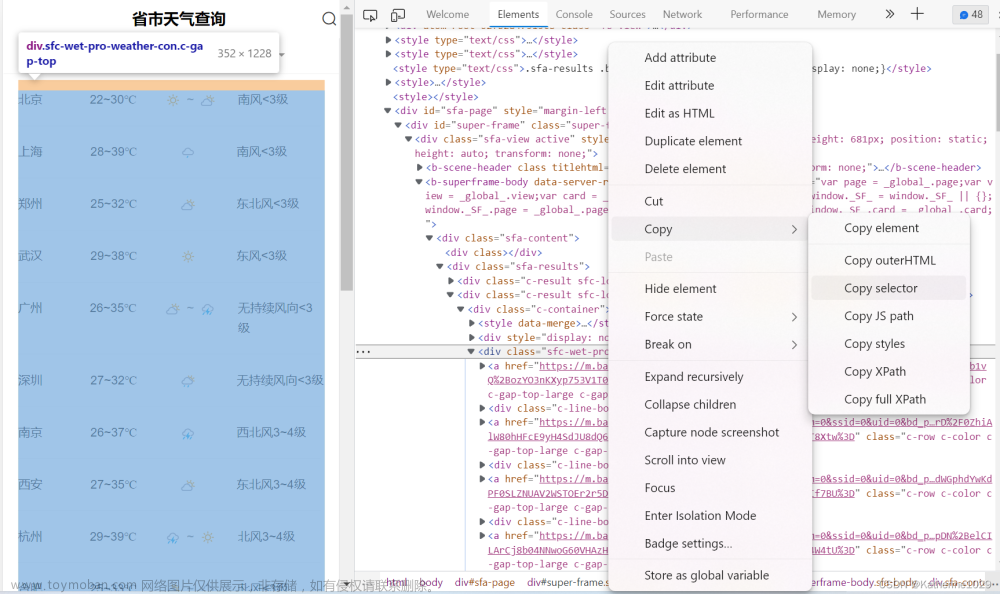
4.分析得到的数据简化地址
实刚才复制的selector就相当于网页上对应部分存放的地址。由于我们需要的是网页上的一类信息,所以我们需要对获取的地址进行分析,提取。
"div.c-span3"
5.爬取内容,清洗数据
之后我们就要soup和text过滤掉不必要的信息,比如js类语言,排除这类语言对于信息受众阅读的干扰。这样我们就成功的将信息,爬取下来了
#爬取内容 content="div.c-span3"
源代码:
import requests
from bs4 import BeautifulSoup
import requests
cookies = {
'BIDUPSID': 'ABC770A56AAD1E552FAB99C7CE36ECAA',
'PSTM': '1653634850',
'BAIDUID': 'ABC770A56AAD1E552106D5A8BAF9EBC5:FG=1',
'BDSFRCVID_BFESS': '9d0OJeCmHRK6MljD4uC9uQHHCeKK0gOTHllnV9rzfBLFl7tVJeC6EG0Ptf8g0KubuTkzogKK0gOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5',
'BAIDUID_BFESS': '6D7995BB1AE2F8100AED6C5BDFC80A9B:FG=1',
'BA_HECTOR': '2ha0802g8125252g0h2l36fp1hfjq1j17',
'BDORZ': 'B490B5EBF6F3CD402E515D22BCDA1598',
'SE_LAUNCH': '5%3A1660553705',
'POLYFILL': '0',
'delPer': '0',
'H_WISE_SIDS': '107311_110085_131861_180636_196426_204904_206122_208721_209568_210294_210321_211435_211985_212295_212740_212797_212867_213040_213351_214807_215727_216842_216941_217049_217086_217167_217915_218022_218454_218598_218619_219067_219943_219946_220014_220602_220662_220856_221008_221118_221121_221391_221411_221439_221468_221478_221501_221697_221796_221825_221871_221901_221919_222276_222298_222390_222396_222500_222616_222618_222620_222625_222773_222780_222792_222955_223048_223064_223134_223238_223253_223375_223474_223599_223766_223788_223825_223853_223919_224048_224068_224085_224275_224438_224572_224798_224815_224867_8000087_8000124_8000135_8000146_8000149_8000151_8000164_8000170_8000178_8000185',
'H_WISE_SIDS_BFESS': '107311_110085_131861_180636_196426_204904_206122_208721_209568_210294_210321_211435_211985_212295_212740_212797_212867_213040_213351_214807_215727_216842_216941_217049_217086_217167_217915_218022_218454_218598_218619_219067_219943_219946_220014_220602_220662_220856_221008_221118_221121_221391_221411_221439_221468_221478_221501_221697_221796_221825_221871_221901_221919_222276_222298_222390_222396_222500_222616_222618_222620_222625_222773_222780_222792_222955_223048_223064_223134_223238_223253_223375_223474_223599_223766_223788_223825_223853_223919_224048_224068_224085_224275_224438_224572_224798_224815_224867_8000087_8000124_8000135_8000146_8000149_8000151_8000164_8000170_8000178_8000185',
'BDSVRTM': '54',
'PSINO': '5',
'H_PS_PSSID': '36549_36755_36641_37107_36954_34812_36917_36569_37077_37137_37055_26350',
'ab_sr': '1.0.1_MTU4MzA0NmM2MWUxMTA0MTczZmJlMjhmZGFkYTM1ZTE1MWRmNTA0NzM4ZTliYjcwNDkzZThkYjNmZTViNjNmNjVkY2NjMGFhMzUyNzUwNGNlOTYyNTg1NDAwMzI2MjBhZTBjMTNhNGRlZTQ5ZjU5NDQwMmExYjhmOTYzYmVkNDdmYTcxOGVlMjQ3NDM4ZWUzYTM0MDdlZTY0M2MxYTE1Zg==',
'__bsi': '10904855338309584892_00_31_R_N_238_0303_c02f_Y',
'BDSVRBFE': 'Go',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'en-US,en;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
# Requests sorts cookies= alphabetically
# 'Cookie': 'BIDUPSID=ABC770A56AAD1E552FAB99C7CE36ECAA; PSTM=1653634850; BAIDUID=ABC770A56AAD1E552106D5A8BAF9EBC5:FG=1; BDSFRCVID_BFESS=9d0OJeCmHRK6MljD4uC9uQHHCeKK0gOTHllnV9rzfBLFl7tVJeC6EG0Ptf8g0KubuTkzogKK0gOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; BAIDUID_BFESS=6D7995BB1AE2F8100AED6C5BDFC80A9B:FG=1; BA_HECTOR=2ha0802g8125252g0h2l36fp1hfjq1j17; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; SE_LAUNCH=5%3A1660553705; POLYFILL=0; delPer=0; H_WISE_SIDS=107311_110085_131861_180636_196426_204904_206122_208721_209568_210294_210321_211435_211985_212295_212740_212797_212867_213040_213351_214807_215727_216842_216941_217049_217086_217167_217915_218022_218454_218598_218619_219067_219943_219946_220014_220602_220662_220856_221008_221118_221121_221391_221411_221439_221468_221478_221501_221697_221796_221825_221871_221901_221919_222276_222298_222390_222396_222500_222616_222618_222620_222625_222773_222780_222792_222955_223048_223064_223134_223238_223253_223375_223474_223599_223766_223788_223825_223853_223919_224048_224068_224085_224275_224438_224572_224798_224815_224867_8000087_8000124_8000135_8000146_8000149_8000151_8000164_8000170_8000178_8000185; H_WISE_SIDS_BFESS=107311_110085_131861_180636_196426_204904_206122_208721_209568_210294_210321_211435_211985_212295_212740_212797_212867_213040_213351_214807_215727_216842_216941_217049_217086_217167_217915_218022_218454_218598_218619_219067_219943_219946_220014_220602_220662_220856_221008_221118_221121_221391_221411_221439_221468_221478_221501_221697_221796_221825_221871_221901_221919_222276_222298_222390_222396_222500_222616_222618_222620_222625_222773_222780_222792_222955_223048_223064_223134_223238_223253_223375_223474_223599_223766_223788_223825_223853_223919_224048_224068_224085_224275_224438_224572_224798_224815_224867_8000087_8000124_8000135_8000146_8000149_8000151_8000164_8000170_8000178_8000185; BDSVRTM=54; PSINO=5; H_PS_PSSID=36549_36755_36641_37107_36954_34812_36917_36569_37077_37137_37055_26350; ab_sr=1.0.1_MTU4MzA0NmM2MWUxMTA0MTczZmJlMjhmZGFkYTM1ZTE1MWRmNTA0NzM4ZTliYjcwNDkzZThkYjNmZTViNjNmNjVkY2NjMGFhMzUyNzUwNGNlOTYyNTg1NDAwMzI2MjBhZTBjMTNhNGRlZTQ5ZjU5NDQwMmExYjhmOTYzYmVkNDdmYTcxOGVlMjQ3NDM4ZWUzYTM0MDdlZTY0M2MxYTE1Zg==; __bsi=10904855338309584892_00_31_R_N_238_0303_c02f_Y; BDSVRBFE=Go',
'Referer': 'https://www.baidu.com/link?url=DuQVKq8Td4TeuN-jwjK7jsswx0C1IdqTEyroK-ujwDUgbqe8cxCSUISnkUn7YB-lcSSOtk_xpTMJD1pl1GH_WSj5TEyWoehR9gwTgNsmuUnTOygSygm4X1V6BmRDvXpUboPyHjWmSvqm29EfTYTWRdCVaS2LiKke2KTbl3MNz-ERJRAny3-eED6v5rA7XV03cPWjuGuwvxzGuW4KMF13CqG7_hRSlgvrZ4WgzBt0GY7&wd=&eqid=d36a6c8c00004d680000000462faee7e',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-site',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.54',
'sec-ch-ua': '"Chromium";v="104", " Not A;Brand";v="99", "Microsoft Edge";v="104"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
params = {
'pd': 'life_compare_weather',
'openapi': '1',
'dspName': 'iphone',
'from_sf': '1',
'resource_id': '4495',
'word': '全国天气',
'title': '省市天气查询',
'srcid': '4983',
'fromSite': 'pc',
}
#获取网页
response = requests.get('https://m.baidu.com/sf', params=params, cookies=cookies, headers=headers)
#数据存储
fo = open("./天气.txt",'a',encoding="utf-8")
#解析网页
response.encoding='utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
print(soup)
#爬取内容
content="div.c-span3"
#清洗数据
a=soup.select(content)
for i in range(0,len(a)):
a[i] = a[i].text
fo.write(a[i]+'\n')
fo.close()
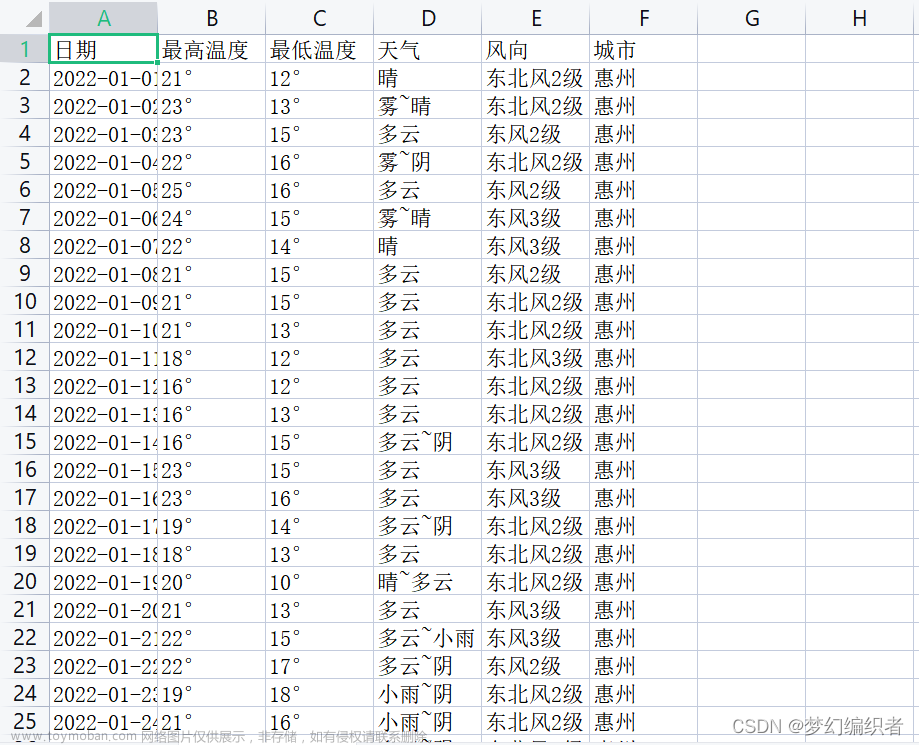
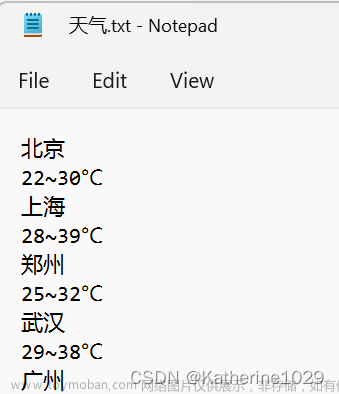
爬出结果:
编写过程中注意点和有待提升:
1.没有捞出天气信息,只捞出了气温
2.header and cookie的信息不是每次都捞出想要的,需要自己尝试
3.将捞出的数据做出图表,TXT不是很直观文章来源:https://www.toymoban.com/news/detail-473090.html
仅供学习,不可用于商业行为文章来源地址https://www.toymoban.com/news/detail-473090.html
B站爬取视屏代码 sys.argv = ['you-get', '--format=dash-flv', 'https://www.bilibili.com/bangumi/play/ss12548?from_spmid=666.23.0.0 '] you_get.main()
到了这里,关于python 爬虫爬取天气的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!