关键词:大模型,LLaMA,Alpaca,Lora,Belle,模型训练,模型微调,指令微调
最近尝试在领域数据进行生成式大模型的再训练和微调,在调研和实验中整理了一些项目&论文的基本信息,后续会持续完善和补充。
LLaMA大模型及其衍生模型
1. LLaMA
项目地址: https://github.com/facebookresearch/llama
LLaMa语料数据如下,对各类语料又做了「去重、筛选」等,每种数据的处理方式有差别,具体见论文。语料中不包含中文数据。![[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)](https://imgs.yssmx.com/Uploads/2023/06/473799-1.png)
模型参数:1.4T tokens, 2 epochs, 训练耗时65B模型: 2048 * 80G A100 * 21day,其他参数见下表:![[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)](https://imgs.yssmx.com/Uploads/2023/06/473799-2.png)
相对于之前的大模型,LLaMa做了三点改进:
- GPT3在每层transformer之后做正则化,调整为在每层transformer之前做正则化,正则化采用RMSNorm;
- 相比PaLM,在激活函数上,使用SwiGLU替换ReLU非线性激活函数;
- 相比GPTNeo,在位置编码上,使用RoPE替代绝对位置编码;
LLaMA相对其他大模型在零样本常识推理任务上的性能对比:![[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)](https://imgs.yssmx.com/Uploads/2023/06/473799-3.png)
结论:在其他零样本、小样本任务上与各大模型进行性能对比,结果显示,LLaMA-13B在大多数任务上能够赶上GPT3,但模型大小不足GPT3的十分之一。LLaMA-65B与Chinchilla-70B/PaLM-540B在多个任务也具有一定的竞争力。
更重要的是LLaMA是chatGPT之后首个被广泛用作底座模型的开源大模型,为后续基于llama的衍生模型做出了极大的贡献![[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)](https://imgs.yssmx.com/Uploads/2023/06/473799-4.png)
2. stanford_alpaca
项目地址:https://github.com/tatsu-lab/stanford_alpaca
以llama做为底座模型,引入新的数据进行指令微调ISF,新数据采用self-instruct的方式有Text-davinci-003进行生成,得到52k新数据进行微调训练。
本项目的贡献在于,提供了用于指令微调的数据生成方式,同时证明了ISF后模型效果的提升,其之后的很多项目均是基于这个思路。![[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)](https://imgs.yssmx.com/Uploads/2023/06/473799-5.png)
3. ChatDoctor
本项目可以看着是standford-aplaca方法在医疗领域的衍生,其借助chatGPT对结构化知识库生成ISF数据集的方法在后续项目的多被借鉴。
项目地址: https://github.com/Kent0n-Li/ChatDoctor
基础模型:llama-7b
指令样本构造:Standford Alpaca 52k数据,700类疾病知识库借助ChatGPT生成的5k数据
指令样本量:52k + 5k
任务评测:对比ChatGPT在医学内容上进行提问,评估内容输出的准确性,ChatGPT 87%,ChatDocter 91%
模型发布:ChatDocktor,模型在stanford alpaca的基础上进行再训练![[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)](https://imgs.yssmx.com/Uploads/2023/06/473799-6.png)
4. alpaca-lora
项目地址: https://github.com/tloen/alpaca-lora
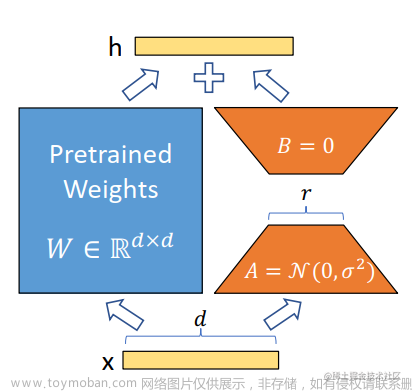
Alpaca-Lora (羊驼-Lora),在stanford-alpaca的基础上,使用 Lora (Low-rank Adaptation) 技术对模型进行指令微调,相当于是对模型进行轻量化训练,使得对显存的占用和训练时长都大幅度降低。在大模型训练高资源高成本的情况下,使用lora技术,牺牲少部分性能却使得大模型训练变得可行,在之后的项目中被广泛用到。
LoRa结构:在模型的Linear层的旁边,增加一个「旁支」,训练更新旁支参数替代模型参数。![[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)](https://imgs.yssmx.com/Uploads/2023/06/473799-7.png)
5. Chinese-LLaMA-Alpaca
项目地址: https://github.com/ymcui/Chinese-LLaMA-Alpaca
该项目值得被重点推荐和学习,ymcui在Bert时代Chinese-BERT-wwm亦是杰出之作。
该项目在LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,同时中文Alpaca模型进一步使用了中文指令数据进行精调。保姆级说明文档及量化版本可轻松部署本地PC。
预训练数据:通用中文语料(bert-wwm,macbert,lert,pert等语料)13.6M行
指令微调样本数据:200w数据,中英文翻译500k + pCLUE 300k + Alpaca 100k(中/英)
6. BELLE
项目地址:https://github.com/LianjiaTech/BELLE
基础模型:bloom-7b, llama-7b
指令样本构造:Standford Alpaca方法,chatGPT self-instruct
指令样本量:20万、60万、100万和200万样本
任务评测:在Extract, Classification, Closed QA, 和Summarization任务上,增加数据能持续带来效果的提升,还未达到瓶颈。在Translation, Rewrite, 和Brainstorming任务上,几十万的数据量就能获得较好的效果。在Math, Code, 和COT任务上,模型效果较差,而且增加数据量已经无法带来效果的提升。 https://github.com/ZrrSkywalker/LLaMA-Adapter
模型发布:BLOOMZ-7B1-xx,LLAMA-7B-xx,xx表示不同的指令样本量
大模型综述 A Survey of Large Language Models
论文地址:A Survey of Large Language Models
4月份发表在arXiv上的大模型综述,包括了大模型的发展历程、各大模型的关键参数、训练语料的处理方法及数据类型,以及大模型训练的流程等,对于全面了解认识大模型很有帮助。
-
大模型发展历程:
![[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)](https://imgs.yssmx.com/Uploads/2023/06/473799-8.png)
- 各大模型关键信息:![[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)](https://imgs.yssmx.com/Uploads/2023/06/473799-9.png)
-
LLM语料从内容类型上可以分为六大类:Books, CommonCrawl, Reddit links, Wikipedia, Code, and others.
![[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)](https://imgs.yssmx.com/Uploads/2023/06/473799-10.png)
语料数据包括了通用数据和专业数据,通用数据的多样性能提高模型的泛化性和语言理解能力,专业数据能够赋予LLM特定的任务解决能力。![[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)](https://imgs.yssmx.com/Uploads/2023/06/473799-11.png)
高质量数据可能在很大程度上影响LLM的性能,因此需要对原始语料进行过滤,包括去除有噪声、冗余、不相关和潜在毒性的数据。
LLM训练前的数据处理流程:![[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)](https://imgs.yssmx.com/Uploads/2023/06/473799-12.png) 文章来源:https://www.toymoban.com/news/detail-473799.html
文章来源:https://www.toymoban.com/news/detail-473799.html
---------END--------文章来源地址https://www.toymoban.com/news/detail-473799.html
到了这里,关于[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!