一、简介
1. 概述
Elasticsearch是一个基于Lucene库的开源搜索引擎,支持分布式、多租户和全文搜索功能。它使用了RESTful API接口可以简化对Elasticsearch的集成和扩展。
2. 应用场景
Elasticsearch广泛应用于全文搜索、日志存储和分析、安全事件检测、业务指标分析等领域。
二、架构
1. 节点和集群
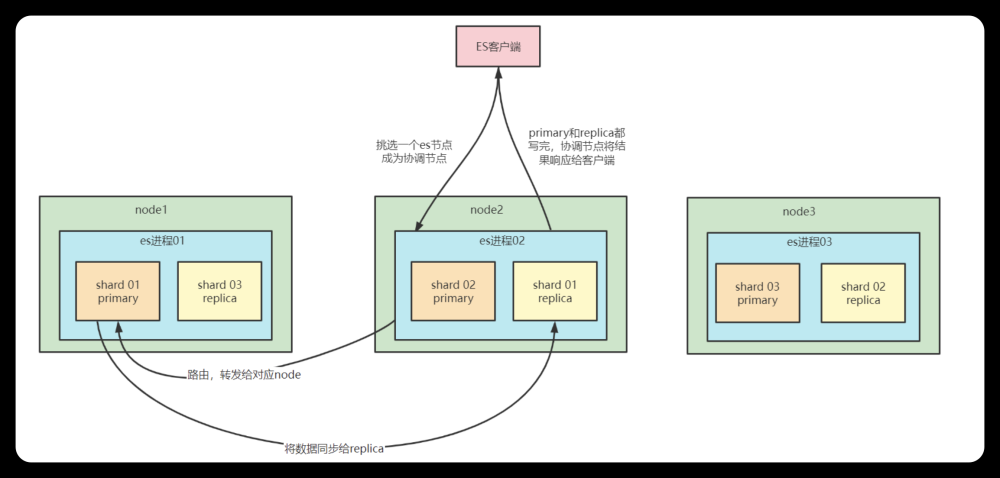
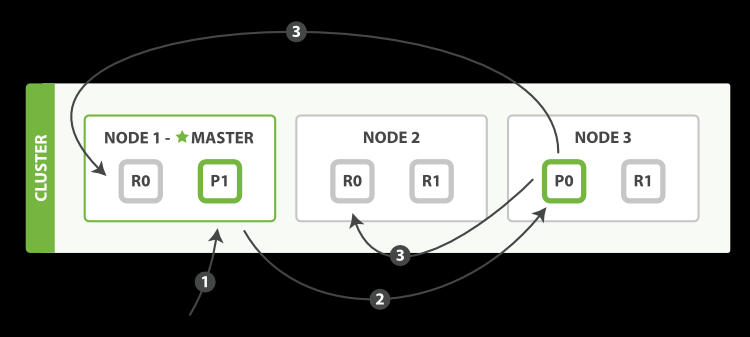
Elasticsearch是一个分布式系统由多个节点组成。节点可以分为两种类型:主节点和数据节点
主节点负责协调整个集群中的操作,例如创建或删除索引、添加或删除节点等等。每个集群只能有一个主节点,当主节点故障时,其他节点将会选举出新的主节点。
数据节点存储数据,并参与搜索操作。在集群中可以同时存在多个数据节点,每个数据节点都包含了所有数据的一部分副本。
节点之间通过使用基于TCP的传输层通信,使用JSON格式进行交互。
2. 索引和分片
Elasticsearch使用索引来组织和存储数据。一个索引可以看作是一个关系型数据库中的一个表,而每个文档则相当于一行数据。
为了支撑大规模数据存储,Elasticsearch将索引分成多个分片(shard),每个分片都是一个独立的Lucene索引。当一个索引被创建时,可以指定分片的数量,在索引中的每个文档将会被分配到一个确定的分片中。分片的数量一旦确定,就不能再更改。
分片带来了好处,使得每个分片只需要存储索引的一小部分数据,从而使它们更容易被存储在单个节点之上。此外,分片还使得Elasticsearch可以水平扩展,可以将不同的分片分配给不同的节点。
下面是Java代码展示如何创建一个索引,设置分片数量为5,副本数量为1:
public void createIndex(RestHighLevelClient client, String indexName) throws IOException {
CreateIndexRequest request = new CreateIndexRequest(indexName);
// 设置分片数量为5,副本数量为1
request.settings(Settings.builder()
.put("index.number_of_shards", 5)
.put("index.number_of_replicas", 1)
);
client.indices().create(request, RequestOptions.DEFAULT);
}
三、查询操作原理
1. 查询DSL语法分类
在Elasticsearch中使用Query DSL(查询领域特定语言)进行查询操作。查询DSL分为两大类:查询查询和聚合查询。
1.1. 查询查询
查询查询用于从索引中获取单个或多个文档。以下是常用的查询类型:
-
match查询:查找包含指定项的文档。如下所示:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
SearchResponse searchResponse = null;
MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("title", "Elasticsearch");
searchSourceBuilder.query(matchQueryBuilder);
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("index-name");
searchRequest.source(searchSourceBuilder);
searchResponse = client.search(searchRequest, CommonOptions.DEFAULT);
-
term查询:查找与指定术语完全匹配的文档。如下所示:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
SearchResponse searchResponse = null;
TermQueryBuilder termQueryBuilder = new TermQueryBuilder("title.keyword", "Elasticsearch");
searchSourceBuilder.query(termQueryBuilder);
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("index-name");
searchRequest.source(searchSourceBuilder);
searchResponse = client.search(searchRequest, CommonOptions.DEFAULT);
-
bool查询:将多个查询组合在一起,并通过逻辑运算符来确定与查询的真值。如下所示:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
SearchResponse searchResponse = null;
MatchQueryBuilder matchQueryBuilder1 = new MatchQueryBuilder("title", "Elasticsearch");
MatchQueryBuilder matchQueryBuilder2 = new MatchQueryBuilder("content", "Java");
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
boolQueryBuilder.must(matchQueryBuilder1);
boolQueryBuilder.must(matchQueryBuilder2);
searchSourceBuilder.query(boolQueryBuilder);
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("index-name");
searchRequest.source(searchSourceBuilder);
searchResponse = client.search(searchRequest, CommonOptions.DEFAULT);
1.2. 聚合查询
聚合查询用于从索引中获取汇总信息。以下是常见的聚合类型:
-
avg聚合:计算指定字段的平均值。如下所示:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
SearchResponse searchResponse = null;
AvgAggregationBuilder aggregationBuilder = AggregationBuilders.avg("average_price").field("price");
searchSourceBuilder.aggregation(aggregationBuilder);
searchSourceBuilder.size(0); // return only aggregations and no hits
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("index-name");
searchRequest.source(searchSourceBuilder);
searchResponse = client.search(searchRequest, CommonOptions.DEFAULT);
-
max聚合:计算指定字段的最大值。如下所示:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
SearchResponse searchResponse = null;
MaxAggregationBuilder aggregationBuilder = AggregationBuilders.max("max_price").field("price");
searchSourceBuilder.aggregation(aggregationBuilder);
searchSourceBuilder.size(0); // return only aggregations and no hits
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("index-name");
searchRequest.source(searchSourceBuilder);
searchResponse = client.search(searchRequest, CommonOptions.DEFAULT);
2. Lucene 原理基础
Elasticsearch是基于Lucene库开发的。因此了解Lucene的一些基础原理可以更好地理解Elasticsearch的查询操作。Lucene是一个文档检索库,用于快速地搜索大量文档。以下是Lucene的一些关键概念:
-
Document:文档是Lucene中的最小检索单位。每个文档都由多个字段组成。 -
Field:字段表示文档的内容。每个字段都有一个名字和值。 -
Analyzer:分析器用于将文本转换为词条,这些词条将存储在倒排索引中。 -
Inverted Index:倒排索引是一个包含单个词汇条目的文档列表的数据结构。它使得快速查找文档成为可能。 -
TF-IDF:TF-IDF(词频 - 逆文档频率)是一种常见的检索评估方法,用于计算文档中单词的重要性。
四、性能优化实践
1. 集群设置与调优
1.1 分片
- 合理设置分片数量
- 分片数过多会降低索引和搜索的性能
- 建议每个节点最少设置两个分片
- 分片平衡
- Elasticsearch自动将副本分配到其他节点上
- 考虑使用Shard Allocation Awareness优化跨机架部署,避免机架单点故障带来的影响
1.2 副本
- 合理设置副本数量
- 副本数过多会增加集群负载,导致查询变慢
- 建议副本数不超过节点数-1
- 副本位置
- 数据中心可用性高:副本置于其他服务器(或数据中心)
- 数据中心可用性低:副本置于相同服务器(或数据中心)
1.3 内存
- 设置Xmx和Xms参数,限制JVM使用的最大和最小内存
- 注意JVM内存与操作系统缓存的折衷,确保JVM能充分利用一定量的操作系统缓存
2. 索引和查询性能优化
2.1 索引
- 尽量减少分词器的使用
- 禁用不必要的字段
- 确定合适的网络延迟参数,选择正确的同步级别
- 通过Bulk API批量插入数据
2.2 查询
- 查询时避免全文搜索和模糊匹配
- 排序时应使用docvalue进行优化
- 尽量使用过滤器而不是查询器实现准确匹配
3. 内存及磁盘使用技巧
3.1 JVM内存分配
- 应使用cgroup限制Elasticsearch进程的内存使用
- 使用SSD硬盘加速索引和查询操作
- 选择合适的JVM垃圾回收策略以减轻内存压力
4. 正确使用搜索建议和聚合功能
4.1 搜索建议
- 使用completion suggester代替phrase suggester
- 建议根据具体场景合理设置suggest条目数量
4.2 聚合
- 对聚合结果进行分析,确定最优聚合方式
- 避免数据分散,在数据时间窗口内按照时间排序
五、扩展与集成
1. 插件开发以及集成
在Elasticsearch中插件可以扩展和定制Elasticsearch的功能,包括增加新的API端点、集成外部组件或是创建自己的查询方式等等。要开发和集成插件,可以按照以下步骤进行:
步骤1:编写插件代码
开发插件可以使用Java编写,并打包成jar文件,也可以使用Elasticsearch提供的Gradle插件进行构建。在插件代码中,需要实现Plugin接口,并覆盖getSettings()方法以提供插件设置,默认情况下,插件不需要任何设置。此外还需要实现onModule()方法来注册各种组件,包括自定义的QueryBuilder、Aggregator等。例如以下代码展示如何注册一个自定义查询:
public class MyQueryPlugin extends Plugin {
@Override
public Settings getSettings() {
return Settings.builder()
.put("my_setting", "default_value")
.build();
}
@Override
public List<QuerySpec<?>> getQueries(QuerySpecRegistry querySpecRegistry) {
return Collections.singletonList(
new QuerySpec.Builder("myQuery", MyQueryBuilder::new, MyQueryBuilder::fromXContent)
.build()
);
}
// 其他组件的注册
}
步骤2:打包插件
完成插件代码编写后需要将插件打包为.zip格式,并放入Elasticsearch的plugins目录下。要注意的是在打包插件时,需要在根目录下创建es-plugin.properties文件,并设置插件的名字和版本号,例如:
name=my-plugin
version=1.0.0
步骤3:安装插件
将插件打包好并放入plugins目录后,需要重启Elasticsearch节点以完成插件安装。如果一切正常,可以在Elasticsearch的日志中看到类似于以下的输出信息:
[2019-04-06T15:55:21,926][INFO ][o.e.p.PluginsService ] [node-1] loaded module [my-module]
[2019-04-06T15:55:21,927][INFO ][o.e.p.PluginsService ] [node-1] loaded plugin [my-plugin]
2. 生态系统
Elasticsearch生态系统提供了大量的基于Elasticsearch的工具和库,包括:
- Kibana:数据可视化和分析平台
- Logstash:日志流处理工具
- Beats:轻量的数据采集代理
- Elasticsearch-Hadoop:连接Hadoop生态系统和Elasticsearch
- elasticsearch-mapper-attachments插件:支持在Elasticsearch中索引和搜索各种文档格式
这些工具和库可以一起使用,构建出更加强大、灵活和高效的数据分析和搜索方案。
六、大数据技术集成
1. Hadoop集成
1.1 Hadoop技术介绍
Hadoop是一个开源的分布式数据处理框架,最初是为了处理大规模的结构化和半结构化数据而设计。它包括了HDFS(Hadoop Distributed File System)和MapReduce两个核心组件,可以实现大规模数据存储、处理和分析。
Elasticsearch是一个开源的搜索引擎,基于Lucene构建,支持全文搜索、分面搜索、结构化搜索等功能。它被广泛应用在企业级搜索、日志分析、安全分析等领域。
1.2 Hadoop集成方案
Hadoop与Elasticsearch集成主要有以下两种方式:
-
使用Elasticsearch的Hadoop插件,将Elasticsearch作为Hadoop的输出格式,可以方便地把Hadoop的计算结果写入到Elasticsearch中。
-
使用Hadoop的Elasticsearch插件,将Elasticsearch作为Hadoop的输入格式,可以直接从Elasticsearch中读取数据进行计算。
1.3 Hadoop集成的优点
Hadoop与Elasticsearch集成可以带来以下几个优点:
-
处理大规模数据:Hadoop可以有效地处理大规模的数据,而Elasticsearch则可以对这些数据进行高效的检索和分析,结合起来可以实现大规模数据的存储、处理和分析。
-
快速检索:由于Elasticsearch的搜索引擎支持全文搜索、分面搜索等功能,可以快速地检索出需要的数据。
-
灵活性:Hadoop可以根据数据的不同进行多种计算操作,而Elasticsearch也可以根据不同的需求进行数据的不同处理,这两个框架的灵活性相互补充,可以满足不同场景的需求。
2. Spark集成
2.1 Spark技术介绍
Spark是一个开源的大数据处理框架,可以进行内存计算、离线批处理、流式处理、机器学习等多种计算。它具有高速的内存计算能力、良好的易用性和丰富的生态系统。
Spark与Elasticsearch集成可以带来以下几个优点:
-
高速的内存计算:Spark拥有高速的内存计算能力,可以快速地处理大规模数据。而Elasticsearch又可以快速地检索所需的数据,两者协同可以更快地完成数据处理任务。
-
良好的易用性:Spark的API具有良好的易用性,操作简单直观。通过Spark对Elasticsearch中的数据进行处理,可以方便地进行数据分析和挖掘。
2.2 Spark集成方案
Spark可以通过Elasticsearch Hadoop插件实现与Elasticsearch的集成,这个插件可以将Spark作为Hadoop的一个计算引擎,可以读取和写入Elasticsearch中的数据。具体步骤如下:
-
下载并安装Elasticsearch Hadoop插件。
-
在Spark应用程序中添加相关依赖。
-
在Spark应用程序中使用Spark SQL或DataFrame API连接Elasticsearch并进行数据处理。
2.3 Spark集成的优点
Spark与Elasticsearch集成可以带来以下几个优点:
-
快速处理大数据:Spark可以快速地处理大规模数据,而Elasticsearch可以快速地检索所需的数据,两者协同可以更快地完成数据处理任务。
-
容错性:Spark具有良好的容错机制,可以确保数据处理任务的稳定运行。而Elasticsearch也有自己的容错机制,可以防止数据丢失和数据损坏。
3. Logstash集成
3.1 Logstash技术介绍
Logstash是一个开源的数据收集、处理和转发工具,可以将各种数据源(如Web服务器、数据库、消息队列等)中的数据采集并送到不同的目的地。
Logstash可以通过Elasticsearch输出插件将数据写入Elasticsearch中,这样就可以快速地实现数据的检索和分析。
3.2 Logstash集成方案
Logstash可以通过Elasticsearch输出插件实现与Elasticsearch的集成,具体步骤如下:
-
下载并安装Logstash和Elasticsearch。
-
在Logstash配置文件中添加Elasticsearch输出插件,并指定Elasticsearch的连接信息和数据的索引名称等信息。
-
启动Logstash并开始数据采集和处理任务。
3.3 Logstash集成的优点
Logstash与Elasticsearch集成可以带来以下几个优点:
-
高效的数据处理:Logstash可以快速地从各种数据源中采集数据并进行处理,而Elasticsearch可以对这些数据进行高效的检索和分析。文章来源:https://www.toymoban.com/news/detail-474089.html
-
灵活性:通过Logstash的数据处理管道,可以对不同类型的数据进行灵活的处理和转换,而Elasticsearch可以根据不同的需求进行数据的不同处理,这两个框架的灵活性相互补充,可以满足不同场景的需求。文章来源地址https://www.toymoban.com/news/detail-474089.html
到了这里,关于Elasticsearch 底层技术原理以及性能优化实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![五、浅析[ElasticSearch]底层原理与分组聚合查询](https://imgs.yssmx.com/Uploads/2024/02/560240-1.png)




