用集群外的prometheus来监控k8s,主要是想把监控服务跟k8s集群隔离开,这样就能减少k8s资源的开销。
一、环境准备
CentOS Linux release 7.7.1908 (Core) 3.10.0-1062.el7.x86_64
Docker version 20.10.21
| 主机名 | IP | 备注 |
| prometheus-server.test.cn | 192.168.10.166 | |
| k8s集群 | 192.168.10.160:6443 | 集群master-vip |
二、监控指标介绍
需要通过exporter收集各种维度的监控指标,其维度如下
| 监控维度 | 监控工具 | 监控url | 备注 |
| Node性能 | node-exporter | http://node-ip:9100/metrics | 节点状态 |
| Pod性能 | kubelet cadvisor |
https://192.168.10.160:6443/api/v1/nodes/node-name:10250/proxy/metrics https://192.168.10.160:6443/api/v1/nodes/node-name:10250/proxy/metrics/cadvisor |
容器状态 |
| k8s集群资源 | kube-state-metrics | http://192.168.10.160:30866/metrics http://192.168.10.160:30867/metrics |
demploy,ds的各种状态 |
三、k8s apiserver授权
要访问k8s apiserver集群需要先进行授权,而集群内部Prometheus可以使用集群内默认配置进行访问,而集群外的Prometheus访问需要使用token+客户端cert进行认证,因此需要先进行RBAC授权。
由于我们需要访问不同的namespace,因此我们最好分配cluster-admin,以免权限不足。具体步骤如下:
# 创建命名空间
kubectl create ns devops
# 创建serviceaccounts
kubectl create sa prometheus -n devops
# 创建prometheus角色并对其绑定cluster-admin
kubectl create clusterrolebinding prometheus --clusterrole cluster-admin --serviceaccount=devops:prometheus虽创建了serviceaccount,但访问apiserver并不是直接使用serviceaccount,而是通过token。因此我们需要获取serviceaccount:prometheus对应的token,而此token是经过base64加密过的,必须解密后才能使用。
# 1.查看sa,在devops
# kubectl get sa -n devops
NAME SECRETS AGE
default 1 7d1h
prometheus 1 7d1h
# 2.查看secret
# kubectl get sa prometheus -o yaml -n devops
apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: "2022-11-28T14:01:29Z"
name: prometheus
namespace: devops
resourceVersion: "2452117"
uid: 949d3611-04fd-435f-8a93-df189ba27cdf
secrets:
- name: prometheus-token-c9f99
# 3.获取token,从yaml中得到token
# kubectl get secret prometheus-token-c9f99 -o yaml -n devops
apiVersion: v1
data:
ca.crt: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tL.................省略
namespace: ZGV2b3Bz
token: ZXlKaGJHY2lPaUpTVXpJMU5pSXNJbXRwWkNJN...................省略
kind: Secret
metadata:
annotations:
kubernetes.io/service-account.name: prometheus
kubernetes.io/service-account.uid: 949d3611-04fd-435f-8a93-df189ba27cdf
creationTimestamp: "2022-11-28T14:01:29Z"
name: prometheus-token-c9f99
namespace: devops
resourceVersion: "2452116"
uid: 43393401-e7f0-4b58-add5-b88b2abc302f
type: kubernetes.io/service-account-token
# 4.token解密
# 由于此token是经过base64加密的,我们需要通过base64解密获取token值,解出的值要存起来,后面会用到
# echo "ZXlKaGJHY2lPaUpTVXpJMU5pSXNJbXRwWkNJN...................省略" |base64 -d
通过上面的一系列操作获得的token,解密后把它存成k8s_token文件,后面需要在配置Prometheus server时要用作为bearer_token访问k8s的apiserver
四、监控指标收集工具安装
1、node指标收集工具安装
node-exporter工具主要用来采集集群node节点的服务器层面的数据,如cpu、内存、磁盘、网卡流量等,监控的url是:http://node-ip:9100/metrics
node-exporter工具也可以用docker方式独立部署在服务器上,但是独立部署有一个问题 ,就是在集群扩展上,需要手动部署,并且prometheus server也需要手动修改配置文件,非常麻烦。因此我们采用在k8s集群上将node-exporter工具以DaemonSet形式部署,配合Prometheus动态发现更加方便
kind: DaemonSet
apiVersion: apps/v1
metadata:
name: node-exporter
annotations:
prometheus.io/scrape: 'true' #用于prometheus自动发现
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
name: node-exporter
spec:
containers:
- image: quay.io/prometheus/node-exporter:latest
name: node-exporter
ports:
- containerPort: 9100
hostPort: 9100
name: node-exporter
hostNetwork: true #这里面要修改成hostNetwork,以便于直接通过node url直接访问
hostPID: true
tolerations: #设置tolerations,以便master节点也可以安装
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
---
kind: Service
apiVersion: v1
metadata:
annotations:
prometheus.io/scrape: 'true'
labels:
app: node-exporter
name: node-exporter
spec:
type: ClusterIP
clusterIP: None
ports:
- name: node-exporter
port: 9100
protocol: TCP
selector:
app: node-exporter
kubectl apply -f node-exporter.yaml
# kubectl get pod -n devops
NAME READY STATUS RESTARTS AGE
node-exporter-2bjln 1/1 Running 1 (4d6h ago) 7d1h
node-exporter-784sc 1/1 Running 0 7d1h
node-exporter-klts6 1/1 Running 0 7d1h
node-exporter-nz29b 1/1 Running 0 7d1h
node-exporter-tlgjn 1/1 Running 0 7d1h
node-exporter-xnq67 1/1 Running 0 7d1h
2、pod指标收集工具安装
pod的指标是用cAdvisor来收集,目前这个工具集成到 Kubelet中,当Kubelet启动时会同时启动cAdvisor,且一个cAdvisor只监控一个Node节点的信息。cAdvisor 自动查找所有在其所在节点上的容器,自动采集CPU、内存、文件系统和网络使用的统计信息。cAdvisor 通过它所在节点机的 Root 容器,采集并分析该节点机的全面使用情况。
当然kubelet也会输出一些监控指标数据,因此pod的监控数据有kubelet和cadvisor,监控url分别为
https://192.168.10.160:6443/api/v1/nodes/node-name:10250/proxy/metrics
https://192.168.10.160:6443/api/v1/nodes/node-name:10250/proxy/metrics/cadvisor
由于kubelet天然存在,因此直接使用即可,无需做其他配置。
3、k8s集群资源对像指标工具安装
kube-state-metrics工具是一个简单的服务,它监听Kubernetes API服务器并生成关联对象的指标。 它不关注单个Kubernetes组件的运行状况,而是关注内部各种对象(如deployment、node、pod等)的运行状况。
我这边下载的是kube-state-metrics-2.4.2 版本,这个可以根据自已的k8s集群版本来选择,上面有对应列表GitHub - kubernetes/kube-state-metrics: Add-on agent to generate and expose cluster-level metrics.
| kube-state-metrics | Kubernetes client-go Version |
|---|---|
| v2.3.0 | v1.23 |
| v2.4.2 | v1.23 |
| v2.5.0 | v1.24 |
| v2.6.0 | v1.24 |
| v2.7.0 | v1.25 |
| master | v1.25 |
#下载
https://github.com/kubernetes/kube-state-metrics/archive/refs/tags/v2.4.2.zip
#解压
unzip kube-state-metrics-2.4.2.zip
cd kube-state-metrics-2.4.2/examples/standard
#ls
cluster-role-binding.yaml cluster-role.yaml deployment.yaml service-account.yaml service.yaml
#看到5个文件,其中在4个文件里加上之前创建的namespace devops
# grep devops *
cluster-role-binding.yaml: namespace: devops
deployment.yaml: namespace: devops
service-account.yaml: namespace: devops
service.yaml: namespace: devops
#修改service.yaml,增加NodePort,以便Promethues服务可以访问到
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.4.2
name: kube-state-metrics
namespace: devops
spec:
#clusterIP: None
type: NodePort #用NodePort
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
nodePort: 30866 #增加端口
- name: telemetry
port: 8081
targetPort: telemetry
nodePort: 30867 #增加端口
selector:
app.kubernetes.io/name: kube-state-metricskubectl apply -f *.yaml
# kubectl get pod -n devops
NAME READY STATUS RESTARTS AGE
kube-state-metrics-554c4b8c57-5cwld 1/1 Running 0 7d
node-exporter-2bjln 1/1 Running 1 (4d6h ago) 7d1h
node-exporter-784sc 1/1 Running 0 7d1h
node-exporter-klts6 1/1 Running 0 7d1h
node-exporter-nz29b 1/1 Running 0 7d1h
node-exporter-tlgjn 1/1 Running 0 7d1h
node-exporter-xnq67 1/1 Running 0 7d1h
五、Promethemus+Grafana+Alertmanager服务部署
1、Promethemus服务部署
ssh登上192.168.10.166,采用docker部署Promethemus服务
mkdir /etc/prometheus/
docker run -d -p 9090:9090 -v /etc/prometheus/:/etc/prometheus/ --restart=always --name=prometheus --net=bridge prom/prometheus2、配置修改
vim /etc/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.10.166:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
- "rules/node_exporter.yml"
- "rules/process_exporter.yml"
- "rules/pod_exporter.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
#- job_name: "node-monitor"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
static_configs:
- targets: ["192.168.10.166:9090"]
#kube-state-metrics服务采集
- job_name: "kube-state-metrics"
static_configs:
- targets: ["192.168.10.160:30866","192.168.10.160:30867"]
#API Serevr节点指标信息采集
- job_name: 'kubernetes-apiservers-monitor'
kubernetes_sd_configs:
- role: endpoints
api_server: https://192.168.10.160:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: k8s_token #这个k8s_token文件就是刚才前面生成的文件,保存在/etc/promethues路径下
scheme: https
tls_config:
insecure_skip_verify: true
bearer_token_file: k8s_token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- source_labels: [__address__]
regex: '(.*):6443'
replacement: '${1}:9100'
target_label: __address__
action: replace
- source_labels: [__scheme__]
regex: https
replacement: http
target_label: __scheme__
action: replace
#node节点指标信息采集
- job_name: 'kubernetes-nodes-monitor'
scheme: http
tls_config:
insecure_skip_verify: true
bearer_token_file: k8s_token
kubernetes_sd_configs:
- role: node
api_server: https://192.168.10.160:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: k8s_token
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- source_labels: [__meta_kubernetes_node_label_failure_domain_beta_kubernetes_io_region]
regex: '(.*)'
replacement: '${1}'
action: replace
target_label: LOC
- source_labels: [__meta_kubernetes_node_label_failure_domain_beta_kubernetes_io_region]
regex: '(.*)'
replacement: 'NODE'
action: replace
target_label: Type
- source_labels: [__meta_kubernetes_node_label_failure_domain_beta_kubernetes_io_region]
regex: '(.*)'
replacement: 'K8S-test'
action: replace
target_label: Env
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
#pod指标信息采集
# kubelet
- job_name: "kube-node-kubelet"
scheme: https
tls_config:
insecure_skip_verify: true
bearer_token_file: k8s_token
kubernetes_sd_configs:
- role: node
api_server: "https://192.168.10.160:6443"
tls_config:
insecure_skip_verify: true
bearer_token_file: k8s_token
relabel_configs:
- target_label: __address__
# 使用replacement值替换__address__默认值
replacement: 192.168.10.160:6443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
# 使用replacement值替换__metrics_path__默认值
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}:10250/proxy/metrics
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: service_name
#advisor
- job_name: "kube-node-cadvisor"
scheme: https
tls_config:
insecure_skip_verify: true
bearer_token_file: k8s_token
kubernetes_sd_configs:
- role: node
api_server: "https://192.168.10.160:6443"
tls_config:
insecure_skip_verify: true
bearer_token_file: k8s_token
relabel_configs:
- target_label: __address__
# 使用replacement值替换__address__默认值
replacement: 192.168.10.160:6443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
# 使用replacement值替换__metrics_path__默认值
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}:10250/proxy/metrics/cadvisor
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: service_name
修改完配置文件后,重启Prometheus服务,然后查看一下日志是否正常,看到以下"Server is ready to receive web requests",代表服务正常
on=2.641481066s wal_replay_duration=5.355716351s total_replay_duration=8.304813832s
ts=2022-12-06T04:49:14.648Z caller=main.go:945 level=info fs_type=EXT4_SUPER_MAGIC
ts=2022-12-06T04:49:14.649Z caller=main.go:948 level=info msg="TSDB started"
ts=2022-12-06T04:49:14.649Z caller=main.go:1129 level=info msg="Loading configuration file" filename=/etc/prometheus/prometheus.yml
ts=2022-12-06T04:49:14.665Z caller=main.go:1166 level=info msg="Completed loading of configuration file" filename=/etc/prometheus/prometheus.yml totalDuration=16.486363ms db_storage=3.223µs remote_storage=32.417µs web_handler=2.464µs query_engine=3.066µs scrape=757.183µs scrape_sd=1.55814ms notify=60.724µs notify_sd=29.287µs rules=11.47234ms
ts=2022-12-06T04:49:14.665Z caller=main.go:897 level=info msg="Server is ready to receive web requests."
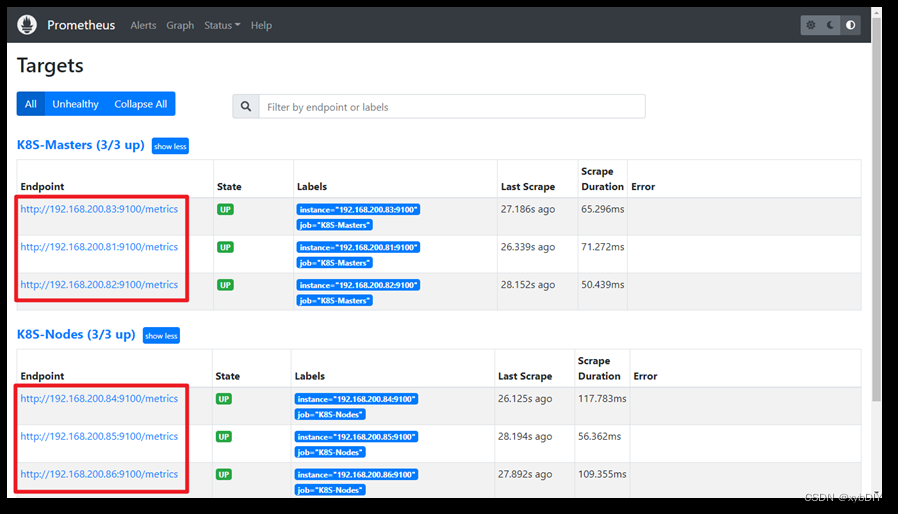
部署完后,在浏览器上输入http://192.168.10.166:9090/targets
看到各种状态都是up,说明可以正常收取到信息

3、Grafana服务部署
mkdir -p /opt/grafana-storage/
#密码设成admin,第一次进入后,需要修改一个新的密码
docker run -d -p 3000:3000 --restart=always --name prom-grafana -v /opt/grafana-storage:/var/lib/grafana -v /etc/localtime:/etc/localtime -e "GF_SECURITY_ADMIN_PASSWORD=admin" grafana/grafana
部署完后在浏览器上输入http://192.168.10.166:3000/,就可以打开Grafana页面了,第一次用户名和密码都是admin,进入后需要设置一个新的密码
##添加数据源

然后可以到https://grafana.com/官网上下载自已的模板,也可以自已创建
4、部署Alertmanager服务
Alertmanager主要是用于邮件报警,微信、钉钉等服务接口服务,这边只介绍邮件服务,别的就不介绍了。
ssh登录192.168.10.166
mkdir -p /etc/alertmanager
mkdir -p /etc/alertmanager/template
docker run -d --restart=always --name=alertmanager -p 9093:9093 -v /etc/alertmanager:/etc/alertmanager -v /etc/localtime:/etc/localtime prom/alertmanager
#修改配置文件
vim /etc/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'mail.test.cn:2525'
smtp_from: 'monitor@test.cn'
smtp_auth_username: 'monitor@test.cn'
smtp_auth_password: 'xxxxxxxxxxx'
smtp_require_tls: false
templates:
- 'template/*.tmpl'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 1m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: 'test01@test.cn,it@test.cn'
html: '{{ template "email.html" . }}'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
vim /etc/alertmanager/template/main.tmpl
{{ define "email.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
**********告警通知********** <br>
告警类型: {{ $alert.Labels.alertname }} <br>
告警级别: {{ $alert.Labels.severity }} <br>
{{- end }}
===================== <br>
告警主题: {{ $alert.Annotations.summary }} <br>
告警详情: {{ $alert.Annotations.description }} <br>
故障时间: {{ $alert.StartsAt.Local }} <br>
{{ if gt (len $alert.Labels.instance) 0 -}}
故障实例: {{ $alert.Labels.instance }} <br>
{{- end -}}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
**********恢复通知********** <br>
告警类型: {{ $alert.Labels.alertname }} <br>
告警级别: {{ $alert.Labels.severity }} <br>
{{- end }}
===================== <br>
告警主题: {{ $alert.Annotations.summary }} <br>
告警详情: {{ $alert.Annotations.description }} <br>
故障时间: {{ $alert.StartsAt.Local }} <br>
恢复时间: {{ $alert.EndsAt.Local }} <br>
{{ if gt (len $alert.Labels.instance) 0 -}}
故障实例: {{ $alert.Labels.instance }} <br>
{{- end -}}
{{- end }}
{{- end }}
{{- end }}
配置文件修改后,重启alertmanager服务。在浏览上输入 http://192.168.10.166:9093/#/status

这样Alertmanager服务就具备发邮件的功能了,这时候还需要在Prometheus的配置,需要添加一些规则,比如host down后,cpu,memery等资源达到多少需要报警
#修改Prometheus主配置文件,添加以上内网
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.10.166:9093 ##调用Alertmanager服务
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
- "rules/node_exporter.yml" #node资源报警规则
- "rules/process_exporter.yml" #服务进程资源报警规则
- "rules/pod_exporter.yml" #k8s里的服务状诚资源报警规则#把这些规则文件全部放在rules目录
mkdir -p /etc/prometheus/rules/vim /etc/prometheus/rules/node_exporter.yml
groups:
- name: host-monitoring
rules:
- alert: hostsDown
expr: up == 0
for: 1m
annotations:
summary: "主机:{{ $labels.hostname }},{{ $labels.instance }} 关机"
- alert: 内存使用率
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10
for: 1m
labels:
severity: warning
annotations:
summary: "内存使用率>90%"
description: "主机:{{ $labels.hostname }},{{ $labels.instance }},当前值:{{ humanize $value }}"
- alert: CPU使用率
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 60
for: 1m
labels:
severity: warning
annotations:
summary: "CPU使用率>60%"
description: "主机:{{ $labels.hostname }},{{ $labels.instance }},当前值:{{ humanize $value }}"
- alert: 磁盘使用率
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node
_filesystem_readonly == 0
for: 1m
labels:
severity: warning
annotations:
summary: "磁盘使用率>90%"
description: "主机:{{ $labels.hostname }},{{ $labels.instance }},当前值:{{ humanize $value }}"vim /etc/prometheus/rules/pod_exporter.yml
groups:
- name: node.rules
rules:
- alert: JobDown #检测job的状态,持续5分钟metrices不能访问会发给altermanager进行报警
expr: up == 0 #0不正常,1正常
for: 5m #持续时间 , 表示持续5分钟获取不到信息,则触发报警
labels:
severity: error
#cluster: k8s
annotations:
summary: "Job: {{ $labels.job }} down"
description: "Instance:{{ $labels.instance }}, Job {{ $labels.job }} stop "
- alert: PodDown
expr: kube_pod_container_status_running != 1
for: 2s
labels:
severity: warning
#cluster: k8s
annotations:
summary: 'Container: {{ $labels.container }} down'
description: 'Namespace: {{ $labels.namespace }}, Pod: {{ $labels.pod }} is not running'
- alert: PodReady
expr: kube_pod_container_status_ready != 1
for: 5m #Ready持续5分钟,说明启动有问题
labels:
severity: warning
#cluster: k8s
annotations:
summary: 'Container: {{ $labels.container }} ready'
description: 'Namespace: {{ $labels.namespace }}, Pod: {{ $labels.pod }} always ready for 5 minitue'
- alert: PodRestart
expr: changes(kube_pod_container_status_restarts_total[30m])>0 #最近30分钟pod重启
for: 2s
labels:
severity: warning
#cluster: k8s
annotations:
summary: 'Container: {{ $labels.container }} restart'
description: 'namespace: {{ $labels.namespace }}, pod: {{ $labels.pod }} restart {{ $value }} times'vim /etc/prometheus/process_exporter.yml
groups:
- name: Server-monitoring
rules:
- alert: etcd
expr: (namedprocess_namegroup_num_procs{groupname="map[:etcd]"}) == 0 ## map[:一定要写规定的进程名]
for: 30s
labels:
severity: error
annotations:
summary: "{{ $labels.instance }}: etcd进程服务挂了,已经超过30秒"
value: "{{ $value }}"
然后重启Prometheus服务,这时候在http://192.168.10.166:9090/rules#host-monitoring文章来源:https://www.toymoban.com/news/detail-474307.html
就可以看到生效的规则。文章来源地址https://www.toymoban.com/news/detail-474307.html
到了这里,关于外独立部署Prometheus+Grafana+Alertmanager监控K8S的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!