论文地址
https://openreview.net/pdf?id=_VjQlMeSB_J
摘要
我们探索如何生成一个思维链——一系列中间推理步骤——如何显著提高大型语言模型执行复杂推理的能力。 特别是,我们展示了这种推理能力如何通过一种称为思维链提示的简单方法自然地出现在足够大的语言模型中,其中提供了一些思维链演示作为提示中的示例。
对三种大型语言模型的实验表明,思维链提示提高了一系列算术、常识和符号推理任务的性能。 实证收益可能是惊人的。 例如,仅使用八个思维链范例来提示 PaLM 540B 在数学单词问题的 GSM8K 基准测试中实现了最先进的准确性,甚至超过了带有验证器的微调 GPT-3。

1 简介
语言模型最近彻底改变了 NLP 领域。 扩大语言模型的规模已被证明可以带来一系列好处,例如提高性能和样本效率。 然而,单靠扩大模型规模并不足以在算术、常识和符号推理等具有挑战性的任务上实现高性能。
这项工作探索了如何释放大型语言模型的推理能力 通过一种由两个想法驱动的简单方法。 首先,算术推理技术可以受益于生成导致最终答案的自然语言基本原理。 除了使用形式语言的神经符号方法之外,先前的工作已经使模型能够通过从头开始训练或微调预训练模型来生成自然语言中间步骤 而不是自然语言。 其次,大型语言模型通过提示提供了上下文中的小样本学习的令人兴奋的前景。 也就是说,不是为每个新任务微调一个单独的语言模型检查点,而是可以简单地用一些演示任务的输入输出范例来“提示”模型。 值得注意的是,这在一系列简单的问答任务中取得了成功。

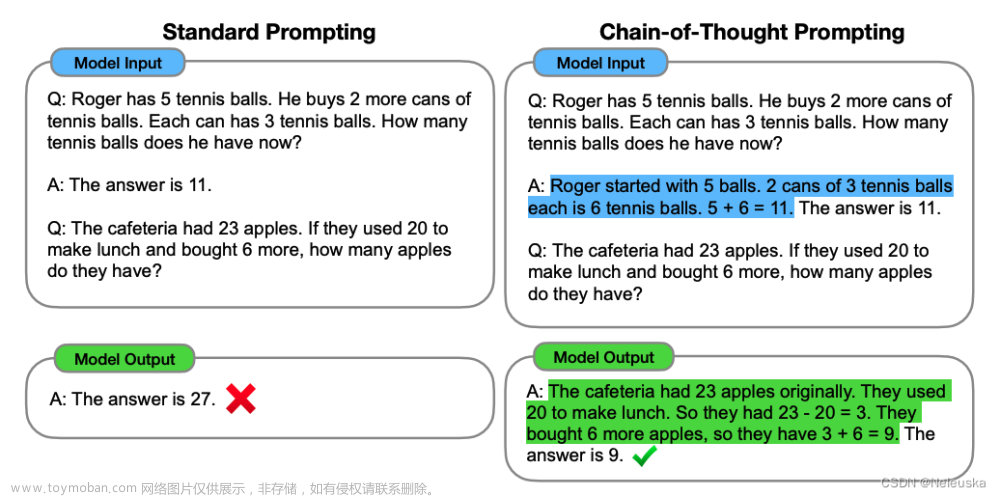
然而,上述两种想法都有关键的局限性。 对于基本原理增强训练和微调方法,创建大量高质量基本原理的成本很高,这比普通机器学习中使用的简单输入-输出对复杂得多。 对于 Brown 等人使用的传统小样本提示方法。 (2020),它在需要推理能力的任务上表现不佳,并且通常不会随着语言模型规模的增加而大幅改善 (Rae et al., 2021)。 在本文中,我们以一种避免其局限性的方式结合了这两种想法的优势。 具体来说,我们探索了语言模型执行推理任务的小样本提示的能力,给定一个由三元组组成的提示:〈输入、思维链、输出〉。 思维链是导致最终输出的一系列中间自然语言推理步骤,我们将这种方法称为思维链提示。 图 1 显示了一个示例提示。
我们对算术、常识和符号推理基准进行了实证评估,表明思维链提示优于标准提示,有时甚至达到惊人的程度。 图 2 说明了这样一个结果——在 GSM8K 数学单词问题基准测试中(Cobbe 等人,2021 年),使用 PaLM 540B 的思维链提示大大优于标准提示,并达到了新的最先进水平 表现。 仅提示方法很重要,因为它不需要大型训练数据集,而且单个模型检查点可以执行许多任务而不失一般性。 这项工作强调了大型语言模型是如何通过一些关于任务的自然语言数据的例子来学习的(参见通过大型训练数据集自动学习输入和输出的模式)。
2 连锁思维提示
在解决复杂的推理任务(例如多步数学单词问题)时,请考虑自己的思维过程。 通常将问题分解为中间步骤并在给出最终答案之前解决每个步骤:“在简给她妈妈 2 朵花后,她有 10 朵花。 . . 然后在她把 3 给她爸爸之后,她会得到 7 。 . . 所以答案是 7。” 本文的目标是赋予语言模型生成类似思维链的能力——一系列连贯的中间推理步骤,这些步骤会导致问题的最终答案。如果在范例中为小样本提示提供了思维链推理的演示,我们将证明足够大的语言模型可以生成思维链。
图 1 显示了一个模型的示例,该模型生成了一条思路来解决数学单词问题,否则它会变得不正确。 在这种情况下,思维链类似于一个解决方案,可以解释为一个解决方案,但我们仍然选择将其称为思维链,以更好地捕捉它模仿逐步思考过程以得出答案的想法(和 此外,解决方案/解释通常在最终答案之后出现(Narang 等人,2020 年;Wiegreffe 等人,2022 年;Lampinen 等人,2022 年等)。
作为一种促进语言模型推理的方法,思维链提示具有几个吸引人的特性。
- 首先,思维链原则上允许模型将多步问题分解为中间步骤,这意味着可以将额外的计算分配给需要更多推理步骤的问题。
- 其次,思维链为模型的行为提供了一个可解释的窗口,表明它可能是如何得出特定答案的,并提供了调试推理路径错误位置的机会(尽管完全表征了支持模型的计算) 答案仍然是一个悬而未决的问题)。
- 第三,链式思维推理可用于数学单词问题、常识推理和符号操作等任务,并且可能(至少在原则上)适用于人类可以通过语言解决的任何任务。
- 最后,只要将思维序列链的例子包含到少样本提示的范例中,就可以很容易地在足够大的现成语言模型中引出思维链推理。
在实证实验中,我们将观察思维链提示在算术推理(第 3 节)、常识推理(第 4 节)和符号推理(第 5 节)中的效用。
3 算术推理
我们首先考虑图 1 中形式的数学单词问题,这些问题衡量语言模型的算术推理能力。 尽管对人类来说很简单,但算术推理是语言模型经常遇到困难的任务(Hendrycks 等人,2021 年;Patel 等人,2021 年等)。 引人注目的是,当与 540B 参数语言模型一起使用时,思维链提示在多项任务上的表现与特定于任务的微调模型相当,甚至在具有挑战性的 GSM8K 基准测试中达到了最新的技术水平(Cobbe 等人,2021)。
3.1 实验装置
我们在多个基准测试中探索了各种语言模型的思维链提示。

基准。 我们考虑以下五个数学单词问题基准:(1)GSM8K 数学单词问题基准(Cobbe 等人,2021),(2)具有不同结构的数学单词问题的 SVAMP 数据集(Patel 等人,2021) ,(3)各种数学单词问题的 ASDiv 数据集(Miao 等人,2020),(4)代数单词问题的 AQuA 数据集,以及(5)MAWPS 基准(Koncel-Kedziorski 等人,2016)。 示例问题在附录表 12 中给出。
标准提示。 对于基线,我们考虑标准的小样本提示,由 Brown 等人推广。 (2020),其中语言模型在输出测试时间示例的预测之前给出了输入-输出对的上下文示例。 范例被格式化为问题和答案。 模型直接给出了答案,如图1(左)所示。
连锁思维提示。 我们提出的方法是用相关答案的思维链来增强小样本提示中的每个范例,如图 1(右)所示。 由于大多数数据集只有一个评估拆分,我们手动组成了一组八个带有思想链的小样例用于提示——图 1(右)显示了一个思想链范例,完整的范例集在 附录表 20。(这些特定范例没有经过提示工程;稳健性在第 3.4 节和附录 A.2 中进行了研究。)调查这种形式的思维链提示是否可以成功地引发一系列数学单词的成功推理 问题,我们对除 AQuA 以外的所有基准测试都使用了这组八个思维链范例,AQuA 是多项选择而不是自由响应。 对于 AQuA,我们使用了训练集中的四个样本和解决方案,如附录表 21 中所示。
语言模型。 我们评估了五种大型语言模型。 第一个是 GPT-3 (Brown et al., 2020),为此我们使用 text-ada-001、text-babbage-001、text-curie-001 和 text-davinci-002,它们大概对应于 InstructGPT 模型 350M、1.3B、6.7B、175B参数模型(Ouyang et al., 2022)。其次是LaMDA(Thoppilan et al., 2022),有422M、2B、8B、68B、137B参数模型。 三是PaLM,有8B、62B、540B参数型号。 第四个是 UL2 20B(Tay 等人,2022),第五个是 Codex(Chen 等人,2021,OpenAI API 中的代码-davinci-002)。 我们通过贪婪解码从模型中采样(尽管后续工作表明可以通过在许多采样代中采用多数最终答案来改进思维链提示(Wang 等人,2022a))。 对于 LaMDA,我们报告了五个随机种子的平均结果,其中每个种子都有不同的随机打乱顺序的样本。 由于 LaMDA 实验没有显示不同种子之间的大差异,为了节省计算,我们报告了所有其他模型的单个示例订单的结果。
3.2 结果

图 4 总结了思维链提示的最强结果,附录中的表 2 显示了每个模型集合、模型大小和基准的所有实验输出。 有三个关键要点。
第一,图 4 表明,思维链提示是模型规模的一种新兴能力(Wei 等人,2022b)。 也就是说,思想链提示不会对小型模型的性能产生积极影响,并且只有在与 ∼100B 参数的模型一起使用时才会产生性能提升。 我们定性地发现,较小规模的模型产生了流畅但不合逻辑的思维链,导致性能低于标准提示。
第二,思维链提示对于更复杂的问题有更大的性能提升。 例如,对于 GSM8K(基线性能最低的数据集),最大的 GPT 和 PaLM 模型的性能翻了一番以上。 另一方面,对于 SingleOp,MAWPS 中最简单的子集,只需要一个步骤即可解决,性能改进要么是负面的,要么非常小(参见附录表 3)。
第三,通过 GPT-3 175B 和 PaLM 540B 进行的思想链提示优于现有技术水平,后者通常会微调标记训练数据集上的任务特定模型。 图 4 显示了 PaLM 540B 如何使用思想链提示在 GSM8K、SVAMP 和 MAWPS 上实现最新技术水平(但请注意,标准提示已经超过了 SVAMP 的先前最佳水平)。 在另外两个数据集 AQuA 和 ASDiv 上,带有思想链提示的 PaLM 达到了现有技术水平的 2% 以内(附录表 2)。
为了更好地理解为什么要使用思想链为了促进工作,我们手动检查了 LaMDA 137B 为 GSM8K 生成的模型生成的思维链。 在模型返回正确最终答案的 50 个随机示例中,所有生成的思维链在逻辑和数学上也是正确的,除了两个巧合地得出了正确的答案(请参阅附录 D.1 和表 8,了解正确的模型生成的思维链示例)。我们还随机检查了模型给出错误答案的 50 个随机样本。 这一分析的总结是,46% 的思维链几乎是正确的,除了小错误(计算器错误、符号映射错误或缺少一个推理步骤),另外 54% 的思维链有重大错误语义理解或连贯性错误(参见附录 D.2)。 为了深入了解为什么缩放可以提高思维链推理能力,我们对 PaLM 62B 产生的错误进行了类似的分析,以及这些错误是否通过缩放到 PaLM 540B 得到修复。 总结是将 PaLM 扩展到 540B 修复了 62B 模型中的大部分单步缺失和语义理解错误(参见附录 A.1)。
3.3 消融研究文章来源:https://www.toymoban.com/news/detail-474486.html
。。待续文章来源地址https://www.toymoban.com/news/detail-474486.html
到了这里,关于(论文阅读)Chain-of-Thought Prompting Elicits Reasoning in Large Language Models的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[论文阅读] Explicit Visual Prompting for Low-Level Structure Segmentations](https://imgs.yssmx.com/Uploads/2024/02/608289-1.png)







