1.yarn(yet another resource negotiator)分布式资源管理系统
1.作业(job)包含多个任务(task)
2.container封装了cpu的各种资源
2.yarn的结构
1.ResouceManager(全局资源管理)
系统资源管理分配 处理客户端请求,健康检查namenode
2.nodemanager(当前节点资源管理)
3.applicationMaster(发送心跳RM.二次分配资源给container,跟踪任务情况,每个客户端申请的都生成一个am)
3.mapreduce(解决计算问题) 改进版spark更简单和流行,Flink可以实时处理,前两个不可以
- 应用场景(略)
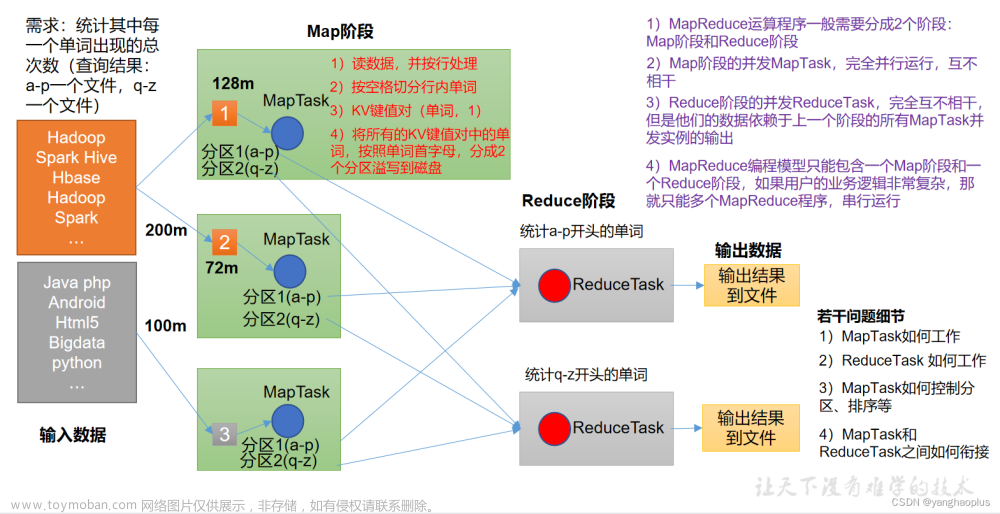
- 分为2个阶段 map(映射)(之间有整体shuffle排序)和reduce(规约) 分而治之(半成品,需要自己加代码)(落地,内存到磁盘)
大任务分为小任务到不同机器,然后任务汇总(数苹果,分几个人数,然后汇总数量)
!!!考试 map的数量由split决定的- 工作流程
0. 输入和分片Split, InputFormat处理输入的格式(默认一行一行处理)
1. map 在数据中选择<k,v> 如输入1行为 hello,key为第一行为1,value为hello
2. shuffle 先整合( mysql group by) 归并排序(order by) 后排序(助手sorter) (对key排序,字母顺序或者数字顺序)
<k,<v1,v2,v3>>
3. reduce
<k2,v2> #为map阶段处理后的结果
4.怎么打包jar
项目运行后export runnable jar
图形界面Scala IDE直接运行代码,在args加参数
5.mapreduce输出存储在日志 /usr/local #把yarn日志聚合配置好
6.winrar先以管理员打开 后解压
7.,mapreduce的输入输出格式
默认TextInputFormat key编号 value为文本行
SequentFormat ??我也没有用过 二进制格式
8.mapreduce
1.map
2.reduce
3.driver初始化的通用模块在main函数
9.excel数据用, 逗号分割,也可以处理访问量统计
10.Combiner 是迷你的reduce 在map本地进行合并(局部合并)避免网络传输慢(可有可无)
使用情况: 不影响最终数据,比如求平均值时,默认不打开
11.Partitioner分区器(必须有的) Hash数字指纹(输入一个文件,生成多个文件)文章来源:https://www.toymoban.com/news/detail-474609.html
//2月份的用户在一个文件 1月份的用户在另外一个文件
//几个reduce决定几个分区
//需要单独写个分区类,判断放到哪个分区,先分区---->Combiner->reduce文章来源地址https://www.toymoban.com/news/detail-474609.html
到了这里,关于05.hadoop上课笔记之hadoop5mapreduce和yarn的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![【Hadoop】- MapReduce概述[5]](https://imgs.yssmx.com/Uploads/2024/04/857929-1.png)