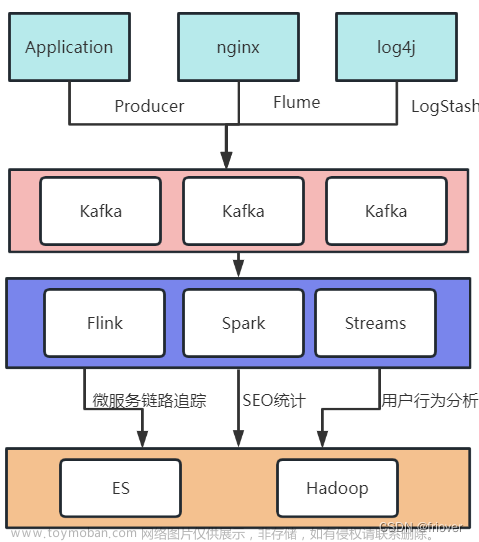
Kafka是LinkedIn公司使用Scala语言开发,后来捐献给apache的项目。官网地址是http://kafka.apache.org。是常用的以高吞吐、可持久化、可水平扩展、支持流处理的分布式消息系统。
简单架构图:
生产端:逻辑层生产者将消息发到指定的topic中,物理层,生产者先找到相应的集群和对应的leader partition建立连接发送消息。
消费端:逻辑层消费组接收此topic的所有消息,物理层消费组的消费者连接到固定的partition来消费消息。
在物理层上包装逻辑层也是一个比较常见的解耦方法:比如很多公司都是多地域多中心的多活容灾架构。在物理层北京亦庄数据中心、上海桂桥数据中心等物理数据中心上划分逻辑数据中心,数据中心的迁移可以做到应用服务不感知。底层的实现原理也很简单就是标签+路由层。
Kafka集群的一台服务端和其他应用一样,是由应用+数据组成,可以算作是一个分布式文件系统。大多数的分布式文件系统就是主从架构如Mysql、Kubernetes和Kafka,个别是对等式的架构如ElasticSearch。Kafka的主节点被称为Controller,负责和Zookeeper通信、集群成员管理(Broker上下线)和Topic管理(增删改查)。Zookeeper里存储的是集群的元数据信息。简而言之,Controller的功能可以类比Kubernetes等集群的Controller功能,差不多的。
数据存储上,每个partition物理上是一个文件夹,相当于将一个巨型文件分成多个大小相等的segment文件。每个文件的消息数不一定相等。每个partition文件由于是顺序读写,所以老的segment文件可以快速被删除。
一个segment文件由一个index文件和一个数据文件组成。文件名为上一个文件的最后一条消息的offset值。索引文件是稀疏索引。所谓稀疏索引说白了就是说不是每条消息都有索引,间隔几条才会有。数据文件也叫日志文件,里面都是一条条消息数据。
Kafka实际项目使用的思考:切换加密集群,安全上的需要,连接Kafka集群需要加密,使用的SASL简单认证和安全层。假设说我们使用的是用户名密码+SSL认证。
kafka参数调优:
在项目中实际使用,很多人都是网上copy对应的配置,并不知道他们之前的参数的相互影响。比如出现rebalance后产生的结果是具体以哪种方式引起的排查,我列举几种原因:
1.数据量大,消费不及时引起循环堆积
2.超时时间配置过小
3.批处理的时效性过慢
问题排查:当数据量大的时候,一次性获取500条数据,但是实际吞吐时长已经超过了心跳检测时间,那么就可能导致数据在偏移到一定数值时,被判定这个消费组挂掉,就直接离线,频繁触发rebalance这种情况。
解决方式:先知道当前获取一批数据消费时间,觉得过长可以优化逻辑(治本)以及修改max-poll-records拉取的批次数(减少批次数,只治标),适当增加heartbeat-interval-ms的检测时间,同时要保证session-timeout-ms的时间要大于heartbeat-interval-ms,不然也会修改参数无效这种情况。文章来源:https://www.toymoban.com/news/detail-474756.html
调优的配置文章来源地址https://www.toymoban.com/news/detail-474756.html
# 消费组
group-id: in-tsp-pre
# 偏移量获取方式
auto-offset-reset: latest
# 是否自动提交
enable-auto-commit: false
# auto-commit-interval: 100
# 批次获取数
max-poll-records: 500
# 批次提交最大时长
max-poll-interval-ms: 600000
# 心跳检测 低于session-timeout-ms的三分之一
heartbeat-interval-ms: 10000
# 超时时间
session-timeout-ms: 30000
到了这里,关于kafka基本架构以及参数调优的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!