本文翻译了 Getting Started 和 Installation Details 和 CIFAR-10 Tutorial 三个教程,可以让新手安装和简单使用上 DeepSpeed 来做模型训练。文章来源地址https://www.toymoban.com/news/detail-474880.html
0x0. 前言
这个系列是对DeepSpeed的教程做一下翻译工作,在DeepSpeed的Tutorials中提供了34个Tutorials。这些Tutorials不仅包含配置DeepSpeed完成分布式训练的标准流程,还包含一些DeepSpeed支持的一些Feature比如低比特优化器,Zero等等。最近有使用DeepSpeed做一些简单的模型训练实验的需求,所以开一下这个专题,尽量翻译完DeepSpeed的大多数Tutorials,不定期更新。这篇首先翻译一下Getting Started 和 Installation Details,CIFAR-10 Tutorial 这三个Tutorials。基于 PyTorch 2.0 版本运行 CIFAR-10 Tutorial 中碰到一些报错也给出了解决的方法。
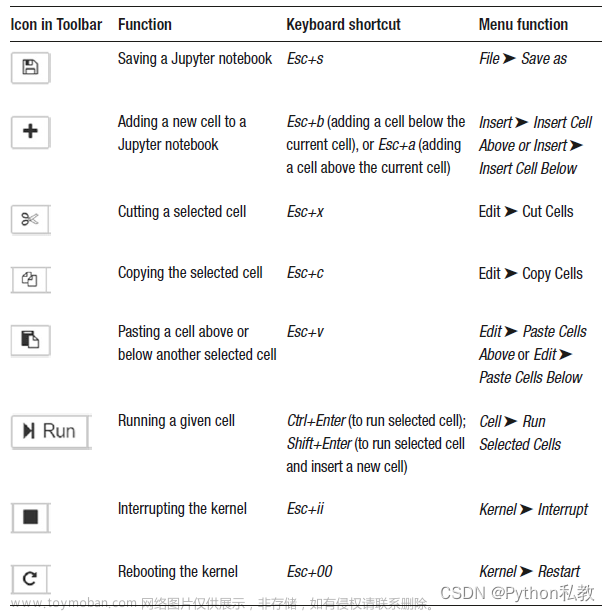
0x1. Getting Started
- 对应原文:https://www.deepspeed.ai/getting-started
安装
- 安装DeepSpeed非常简单,只需运行以下命令:pip install deepspeed。有关更多详细信息,请参阅官方文档,也就是稍后会翻译的文档。
- 要在AzureML上开始使用DeepSpeed,请参阅AzureML Examples GitHub。这里的链接404了。
- DeepSpeed与HuggingFace Transformers和PyTorch Lightning进行了直接集成。HuggingFace Transformers用户现在可以通过简单的
--deepspeed标志和配置文件轻松加速他们的模型。有关更多详细信息,请参见官方文档。PyTorch Lightning通过Lightning Trainer提供了对DeepSpeed的易于访问。有关更多详细信息,请参见官方文档。 - DeepSpeed在AMD上可通过我们的ROCm镜像(https://hub.docker.com/r/deepspeed/rocm501/tags)使用,例如
docker pull deepspeed/rocm501:ds060_pytorch110。
编写DeepSpeed模型
使用DeepSpeed引擎进行模型训练。引擎可以包装任何类型为torch.nn.module的模型,并具有一组最小的API来训练和保存模型检查点。请参见教程以获取详细示例。
要初始化DeepSpeed引擎:
model_engine, optimizer, _, _ = deepspeed.initialize(args=cmd_args,
model=model,
model_parameters=params)
deepspeed.initialize确保在底层适当地完成了所需的分布式数据并行或混合精度训练所需的所有设置。除了包装模型外,DeepSpeed还可以基于传递给deepspeed.initialize和DeepSpeed配置文件(https://www.deepspeed.ai/getting-started/#deepspeed-configuration)的参数构建和管理训练优化器、数据加载器和学习率调度器。请注意,DeepSpeed会在每个训练步骤自动执行学习率调度。
如果你已经设置了分布式环境,则需要进行以下替换:
torch.distributed.init_process_group(...)
替换为:
deepspeed.init_distributed()
默认情况下,DeepSpeed使用已经经过充分测试的NCCL后端,但您也可以覆盖默认设置(https://deepspeed.readthedocs.io/en/latest/initialize.html#distributed-initialization)。但是,如果直到deepspeed.initialize()之后才需要设置分布式环境,则无需使用此函数,因为DeepSpeed将在其初始化期间自动初始化分布式环境。无论如何,你都需要删除torch.distributed.init_process_group。
训练
一旦DeepSpeed引擎被初始化,就可以使用三个简单的API来进行前向传播(callable object)、反向传播(backward)和权重更新(step)来训练模型。
for step, batch in enumerate(data_loader):
#forward() method
loss = model_engine(batch)
#runs backpropagation
model_engine.backward(loss)
#weight update
model_engine.step()
-
Gradient Averaging: 在分布式数据并行训练中,
backward确保在对一个train_batch_size进行训练后,梯度在数据并行进程间进行平均。 - Loss Scaling: 在FP16/混合精度训练中, DeepSpeed 引擎会自动处理缩放损失,以避免梯度中的精度损失。
-
Learning Rate Scheduler: 当使用 DeepSpeed 的学习率调度器(在
ds_config.json文件中指定)时, DeepSpeed 会在每次训练步骤(执行model_engine.step()时)调用调度器的step()方法。当不使用DeepSpeed的学习率调度器时:- 如果调度期望在每次训练步骤都执行, 那么用户可以在初始化 DeepSpeed 引擎时将调度器传递给
deepspeed.initialize, 让 DeepSpeed 进行管理、更新或保存/恢复。 - 如果调度应该在任何其它间隔(例如训练周期)执行,则用户在初始化期间不应将调度传递给 DeepSpeed,必须显式地管理它。
- 如果调度期望在每次训练步骤都执行, 那么用户可以在初始化 DeepSpeed 引擎时将调度器传递给
模型检查点
使用 DeepSpeed 中的 save_checkpoint 和 load_checkpoint API 处理训练状态的保存和加载,需要提供两个参数来唯一识别一个检查点:
-
ckpt_dir: 检查点将保存到此目录。 -
ckpt_id:在目录中唯一标识检查点的标识符。在下面的代码片段中,我们使用损失值作为检查点标识符。
#load checkpoint
_, client_sd = model_engine.load_checkpoint(args.load_dir, args.ckpt_id)
step = client_sd['step']
#advance data loader to ckpt step
dataloader_to_step(data_loader, step + 1)
for step, batch in enumerate(data_loader):
#forward() method
loss = model_engine(batch)
#runs backpropagation
model_engine.backward(loss)
#weight update
model_engine.step()
#save checkpoint
if step % args.save_interval:
client_sd['step'] = step
ckpt_id = loss.item()
model_engine.save_checkpoint(args.save_dir, ckpt_id, client_sd = client_sd)
DeepSpeed 可以自动保存和恢复模型、优化器和学习率调度器的状态,同时隐藏这些细节,使用户无需关心。然而,用户可能希望保存与给定模型训练相关的其他数据。为了支持这些项目,save_checkpoint 接受一个客户端状态字典 client_sd 用于保存。这些元素可以作为返回参数从 load_checkpoint 中检索。在上面的示例中,步骤值 (step) 被存储为 client_sd 的一部分。
重要提示:所有进程都必须调用此方法,而不仅仅是rank 0的进程。这是因为每个进程都需要保存其主节点权重和调度器+优化器状态。如果仅为rank 0的进程调用此方法,它将挂起等待与其它进程同步。
DeepSpeed 配置
可以使用一个配置 JSON 文件来启用、禁用或配置 DeepSpeed 功能,该文件应该作为 args.deepspeed_config 指定。下面是一个示例配置文件。有关完整功能集,请参见 API 文档(https://www.deepspeed.ai/docs/config-json/) 。
{
"train_batch_size": 8,
"gradient_accumulation_steps": 1,
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.00015
}
},
"fp16": {
"enabled": true
},
"zero_optimization": true
}
加载 DeepSpeed 训练
DeepSpeed 安装了入口点 deepspeed 以启动分布式训练。我们通过以下假设来说明 DeepSpeed 的一个示例用法:
- 你已将 DeepSpeed 集成到你的模型中了。
-
client_entry.py是你的模型入口脚本。 -
client args是argparse命令行参数。 -
ds_config.json是 DeepSpeed 的配置参数。
资源配置
DeepSpeed 使用与 OpenMPI 和 Horovod 兼容的 hostfile 配置多节点计算资源。hostfile 是一个主机名(或 SSH 别名)列表,这些机器可以通过无密码 SSH 访问,并且还包括 slot counts,用于指定系统上可用的 GPU 数量。例如:
worker-1 slots=4
worker-2 slots=4
上述示例指定了两个名为 worker-1 和 worker-2 的机器,每台机器都有四个 GPU 用于训练。
可以使用 --hostfile 命令行选项指定 hostfile。如果没有指定 hostfile,则 DeepSpeed 会搜索 /job/hostfile 。如果没有指定或找到 hostfile,则 DeepSpeed 查询本地计算机上的 GPU 数量,以发现可用的本地 slot 数量。
下面的命令在 myhostfile 中指定的所有可用节点和 GPU 上启动 PyTorch 训练工作:
deepspeed --hostfile=myhostfile <client_entry.py> <client args> \
--deepspeed --deepspeed_config ds_config.json
另外,DeepSpeed 允许您将模型的分布式训练限制在可用节点和 GPU 的子集上。此功能通过两个命令行参数启用:--num_nodes 和 --num_gpus。例如,可以使用以下命令将分布式训练限制为仅使用两个节点:
deepspeed --num_nodes=2 \
<client_entry.py> <client args> \
--deepspeed --deepspeed_config ds_config.json
您也可以使用 --include 和 --exclude 标志来包含或排除特定的资源。例如,要使用除节点 worker-2 上的 GPU 0 和节点 worker-3 上的 GPU 0 和 1 之外的所有可用资源:
deepspeed --exclude="worker-2:0@worker-3:0,1" \
<client_entry.py> <client args> \
--deepspeed --deepspeed_config ds_config.json
类似地,可以仅在 worker-2 上使用 GPU 0 和 1:
deepspeed --include="worker-2:0,1" \
<client_entry.py> <client args> \
--deepspeed --deepspeed_config ds_config.json
多节点环境变量
当在多个节点上进行训练时,我们发现支持传播用户定义的环境变量非常有用。默认情况下,DeepSpeed 将传播所有设置的 NCCL 和 PYTHON 相关环境变量。如果您想传播其它变量,可以在名为 .deepspeed_env 的文件中指定它们,该文件包含一个行分隔的 VAR=VAL 条目列表。DeepSpeed 启动器将查找你执行的本地路径以及你的主目录(~/)。
以一个具体的例子来说明,有些集群需要在训练之前设置特殊的 NCCL 变量。用户可以简单地将这些变量添加到其主目录中的 .deepspeed_env 文件中,该文件如下所示:
NCCL_IB_DISABLE=1
NCCL_SOCKET_IFNAME=eth0
DeepSpeed 然后会确保在启动每个进程时在整个训练工作的每个节点上设置这些环境变量。
MPI 和 AzureML 兼容性
如上所述,DeepSpeed 提供了自己的并行启动器来帮助启动多节点/多GPU训练作业。如果您喜欢使用MPI(例如 mpirun)启动训练作业,则我们提供对此的支持。需要注意的是,DeepSpeed 仍将使用 torch 分布式 NCCL 后端,而不是 MPI 后端。
要使用 mpirun + DeepSpeed 或 AzureML(使用 mpirun 作为启动器后端)启动你的训练作业,您只需要安装 mpi4py Python 包。DeepSpeed 将使用它来发现 MPI 环境,并将必要的状态(例如 world size、rank 等)传递给 torch 分布式后端。
如果你正在使用模型并行,Pipline 并行或者在调用 deepspeed.initialize(..) 之前需要使用 torch.distributed 调用,我们为你提供了额外的 DeepSpeed API 调用以支持相同的 MPI。请将您的初始 torch.distributed.init_process_group(..) 调用替换为:
deepspeed.init_distributed()
资源配置(单节点)
如果我们只在单个节点上运行(具有一个或多个GPU),DeepSpeed不需要像上面描述的那样使用 hostfile。如果没有检测到或传递 hostfile,则 DeepSpeed 将查询本地计算机上的 GPU 数量来发现可用的插槽数。--include 和 --exclude 参数与正常工作相同,但用户应将“localhost”指定为主机名。
另外需要注意的是,CUDA_VISIBLE_DEVICES 不能用于 DeepSpeed 来控制应该使用哪些设备。例如,要仅使用当前节点的 gpu1,请执行以下操作:
deepspeed --include localhost:1 ...
0x2. Installation Details
- 对应原文:https://www.deepspeed.ai/tutorials/advanced-install/
安装细节
通过 pip 是最快捷的开始使用 DeepSpeed 的方式,这将安装最新版本的 DeepSpeed,不会与特定的 PyTorch 或 CUDA 版本绑定。DeepSpeed 包含若干个 C++/CUDA 扩展,我们通常称之为“ops”。默认情况下,所有这些 extensions/ops 将使用 torch 的 JIT C++ 扩展加载器即时构建(JIT)(https://pytorch.org/docs/stable/cpp_extension.html) ,该加载器依赖 ninja 在运行时进行动态链接。
pip install deepspeed
安装完成后,你可以使用 ds_report 或 python -m deepspeed.env_report 命令查看 DeepSpeed 环境报告,以验证你的安装并查看你的机器与哪些 ops 兼容。我们发现,在调试 DeepSpeed 安装或兼容性问题时,这个报告很有用。
ds_report
预安装DeepSpeed的Ops
注意:在预编译任何 DeepSpeed 的 c++/cuda ops 之前,必须先安装 PyTorch。但是,如果使用 ops 的默认 JIT 编译模式,则不需要预编译安装。
有时我们发现,将一些或全部 DeepSpeed C++/CUDA ops 预先安装而不使用 JIT 编译路径是有用的。为了支持预安装,我们引入了构建环境标志以打开/关闭特定 ops 的构建。
您可以通过设置 DS_BUILD_OPS 环境变量为 1 来指示我们的安装程序(install.sh 或 pip install)尝试安装所有 ops,例如:
DS_BUILD_OPS=1 pip install deepspeed
DeepSpeed 只会安装与你的机器兼容的 ops。有关系统兼容性的更多详细信息,请尝试上面描述的 ds_report 工具。
如果你只想安装特定的 op(例如 FusedLamb),你可以在安装时使用 DS_BUILD 环境变量进行切换。例如,要仅安装带有 FusedLamb op 的 DeepSpeed,请使用:
DS_BUILD_FUSED_LAMB=1 pip install deepspeed
可用的 DS_BUILD 选项包含:
-
DS_BUILD_OPS切换所有 ops -
DS_BUILD_CPU_ADAM构建 CPUAdam op -
DS_BUILD_FUSED_ADAM构建 FusedAdam op (from apex) -
DS_BUILD_FUSED_LAMB构建 FusedLamb op -
DS_BUILD_SPARSE_ATTN构建 sparse attention op -
DS_BUILD_TRANSFORMER构建 transformer op -
DS_BUILD_TRANSFORMER_INFERENCE构建 transformer-inference op -
DS_BUILD_STOCHASTIC_TRANSFORMER构建 stochastic transformer op -
DS_BUILD_UTILS构建各种优化工具 -
DS_BUILD_AIO构建异步 (NVMe) I/O op
为了加速 build-all 过程,您可以使用以下方式并行编译:
DS_BUILD_OPS=1 pip install deepspeed --global-option="build_ext" --global-option="-j8"
这应该可以使完整构建过程加快 2-3 倍。您可以调整 -j 来指定在构建过程中使用多少个 CPU 核心。在此示例中,它设置为 8 个核心。
你还可以构建二进制 whell,并在具有相同类型的 GPU 和相同软件环境(CUDA 工具包、PyTorch、Python 等)的多台机器上安装它。
DS_BUILD_OPS=1 python setup.py build_ext -j8 bdist_wheel
这将在 dist 目录下创建一个 PyPI 二进制轮,例如 dist/deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl,然后你可以直接在多台机器上安装它,在我们的示例中:
pip install dist/deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl
源码安装 DeepSpeed
在从 GitHub 克隆 DeepSpeed 仓库后,您可以通过 pip 在 JIT 模式下安装 DeepSpeed(见下文)。由于不编译任何 C++/CUDA 源文件,此安装过程应该很快完成。
pip install .
对于跨多个节点的安装,我们发现使用 github 仓库中的 install.sh (https://github.com/microsoft/DeepSpeed/blob/master/install.sh) 脚本安装 DeepSpeed 很有用。这将在本地构建一个 Python whell,并将其复制到你的主机文件(通过 --hostfile 给出,或默认为 /job/hostfile)中列出的所有节点上。
当使用 DeepSpeed 的代码首次运行时,它将自动构建仅运行所需的 CUDA 扩展,并默认将它们放置在 ~/.cache/torch_extensions/ 目录下。下一次执行相同的程序时,这些已预编译的扩展将从该目录加载。
如果你使用多个虚拟环境,则可能会出现问题,因为默认情况下只有一个 torch_extensions 目录,但不同的虚拟环境可能使用不同的设置(例如,不同的 python 或 cuda 版本),然后加载另一个环境构建的 CUDA 扩展将失败。因此,如果需要,你可以使用 TORCH_EXTENSIONS_DIR 环境变量覆盖默认位置。因此,在每个虚拟环境中,你可以将其指向一个唯一的目录,并且 DeepSpeed 将使用它来保存和加载 CUDA 扩展。
你还可以在特定运行中更改它,使用:
TORCH_EXTENSIONS_DIR=./torch-extensions deepspeed ...
选择正确的架构进行构建
如果你在运行 DeepSpeed 时遇到以下错误:
RuntimeError: CUDA error: no kernel image is available for execution on the device
这意味着 CUDA 扩展没有为你尝试使用的卡构建。
从源代码构建 DeepSpeed 时,DeepSpeed 将尝试支持各种架构,但在 JIT 模式下,它只支持在构建时可见的架构。
你可以通过设置 TORCH_CUDA_ARCH_LIST 环境变量来专门为所需的一系列架构构建:
TORCH_CUDA_ARCH_LIST="6.1;7.5;8.6" pip install ...
当你为更少的架构构建时,这也会使构建更快。
这也是为了确保使用你的确切架构而建议的。由于各种技术原因,分布式的 PyTorch 二进制文件没有完全支持所有架构,跳过兼容的二进制文件可能会导致未充分利用你的完整卡的计算能力。要查看 deepspeed 来源构建中包含哪些架构 - 保存日志并搜索 -gencode 参数。
完整的 NVIDIA GPU 列表及其计算能力可以在这里 (https://developer.nvidia.com/cuda-gpus) 找到。
CUDA 版本不匹配
如果在运行时碰到以下错误:
Exception: >- DeepSpeed Op Builder: Installed CUDA version {VERSION} does not match the version torch was compiled with {VERSION}, unable to compile cuda/cpp extensions without a matching cuda version.
你安装的 CUDA 版本与用于编译 torch 的 CUDA 版本不匹配。我们仅需要主版本匹配(例如,11.1 和 11.8 是可以的)。但是,主版本不匹配可能会导致意外的行为和错误。
解决此错误的最简单方法是更改已安装的 CUDA 版本(使用 nvcc --version 检查)或更新 torch 版本以匹配已安装的 CUDA 版本(使用 python3 -c "import torch; print(torch.version)" 检查)。
如果你想跳过此检查并继续使用不匹配的 CUDA 版本,请使用以下环境变量:
DS_SKIP_CUDA_CHECK=1
针对特定功能的依赖项
一些 DeepSpeed 功能需要 DeepSpeed 的一般依赖项之外的特定依赖项。
- 有关每个功能/op 的 Python 包依赖项,请参阅我们的 requirements 目录(https://github.com/microsoft/DeepSpeed/tree/master/requirements)。
- 我们尽力将系统级依赖项最小化,但某些功能需要特殊的系统级软件包。请查看我们的
ds_report工具输出,以查看您是否缺少给定功能的系统级软件包。
0x3. CIFAR-10 Tutorial
如果你还没有阅读入门指南,我们建议你先阅读入门指南(就是上面2节),然后再按照本教程逐步操作。
在本教程中,我们将向 CIFAR-10 模型中添加 DeepSpeed,这是一个小型图像分类模型。
首先,我们将介绍如何运行原始的 CIFAR-10 模型。然后,我们将逐步启用此模型以在 DeepSpeed 中运行。
运行原始的 CIFAR-10
CIFAR-10 教程的原始模型代码见(https://github.com/pytorch/tutorials/blob/main/beginner_source/blitz/cifar10_tutorial.py)。我们已将其复制到 DeepSpeedExamples/training/cifar/ (https://github.com/microsoft/DeepSpeedExamples/tree/master/training/cifar)下,并作为子模块提供。要下载,请执行:
git clone git@github.com:microsoft/DeepSpeedExamples.git
安装 CIFAR-10 模型的 requirements:
cd DeepSpeedExamples/training/cifar
pip install -r requirements.txt
运行 python cifar10_tutorial.py,它会在第一次运行时下载训练数据集。
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
170500096it [00:02, 61124868.24it/s]
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
cat frog frog frog
[1, 2000] loss: 2.170
[1, 4000] loss: 1.879
[1, 6000] loss: 1.690
[1, 8000] loss: 1.591
[1, 10000] loss: 1.545
[1, 12000] loss: 1.467
[2, 2000] loss: 1.377
[2, 4000] loss: 1.374
[2, 6000] loss: 1.363
[2, 8000] loss: 1.322
[2, 10000] loss: 1.295
[2, 12000] loss: 1.287
Finished Training
GroundTruth: cat ship ship plane
Predicted: cat ship plane plane
Accuracy of the network on the 10000 test images: 53 %
Accuracy of plane : 69 %
Accuracy of car : 59 %
Accuracy of bird : 56 %
Accuracy of cat : 36 %
Accuracy of deer : 37 %
Accuracy of dog : 26 %
Accuracy of frog : 70 %
Accuracy of horse : 61 %
Accuracy of ship : 51 %
Accuracy of truck : 63 %
cuda:0
我这里本地使用torch 2.0版本,运行这个脚本会报错。AttributeError: ‘_MultiProcessingDataLoaderIter’ object has no attribute ‘next’ 。这个错误通常发生在使用 PyTorch 1.7 及更高版本时,因为在这些版本中,.next() 方法被弃用了,并被
.__next__()方法取代了。因此,你可以把代码中的2处.next()替换成 .next()来解决这个错误。
使能 DeepSpeed
参数解析
使能 DeepSpeed 的第一步是向 CIFAR-10 模型添加 DeepSpeed 参数,可以使用以下方式的 deepspeed.add_config_arguments() 函数:
import argparse
import deepspeed
def add_argument():
parser=argparse.ArgumentParser(description='CIFAR')
# Data.
# Cuda.
parser.add_argument('--with_cuda', default=False, action='store_true',
help='use CPU in case there\'s no GPU support')
parser.add_argument('--use_ema', default=False, action='store_true',
help='whether use exponential moving average')
# Train.
parser.add_argument('-b', '--batch_size', default=32, type=int,
help='mini-batch size (default: 32)')
parser.add_argument('-e', '--epochs', default=30, type=int,
help='number of total epochs (default: 30)')
parser.add_argument('--local_rank', type=int, default=-1,
help='local rank passed from distributed launcher')
# Include DeepSpeed configuration arguments.
parser = deepspeed.add_config_arguments(parser)
args=parser.parse_args()
return args
初始化
我们使用 deepspeed.initialize 创建 model_engine、optimizer 和 trainloader,deepspeed.initialize 的定义如下:
def initialize(args,
model,
optimizer=None,
model_params=None,
training_data=None,
lr_scheduler=None,
mpu=None,
dist_init_required=True,
collate_fn=None):
在这里,我们使用 CIFAR-10 模型(net)、args、parameters 和 trainset 初始化 DeepSpeed:
parameters = filter(lambda p: p.requires_grad, net.parameters())
args=add_argument()
# Initialize DeepSpeed to use the following features
# 1) Distributed model.
# 2) Distributed data loader.
# 3) DeepSpeed optimizer.
model_engine, optimizer, trainloader, _ = deepspeed.initialize(args=args, model=net, model_parameters=parameters, training_data=trainset)
初始化 DeepSpeed 后,原始 device 和 optimizer 会被删除:
#from deepspeed.accelerator import get_accelerator
#device = torch.device(get_accelerator().device_name(0) if get_accelerator().is_available() else "cpu")
#net.to(device)
#optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
训练API
deepspeed.initialize 返回的模型是 DeepSpeed 模型引擎,我们将使用它来使用 forward、backward 和 step API 训练模型。
for i, data in enumerate(trainloader):
# Get the inputs; data is a list of [inputs, labels].
inputs = data[0].to(model_engine.device)
labels = data[1].to(model_engine.device)
outputs = model_engine(inputs)
loss = criterion(outputs, labels)
model_engine.backward(loss)
model_engine.step()
在使用 mini-batch 更新权重之后,DeepSpeed 会自动处理梯度清零。
配置
使用 DeepSpeed 的下一步是创建一个配置 JSON 文件 (ds_config.json)。该文件提供由用户定义的 DeepSpeed 特定参数,例如批2⃣️大小、优化器、调度器和其他参数。
{
"train_batch_size": 4,
"steps_per_print": 2000,
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.001,
"betas": [
0.8,
0.999
],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.001,
"warmup_num_steps": 1000
}
},
"wall_clock_breakdown": false
}
运行启用 DeepSpeed 的 CIFAR-10 模型
要使用 DeepSpeed 开始训练已应用 DeepSpeed 的 CIFAR-10 模型,请执行以下命令,默认情况下它将使用所有检测到的 GPU。
deepspeed cifar10_deepspeed.py --deepspeed_config ds_config.json
DeepSpeed 通常会打印更多的训练细节供用户监视,包括训练设置、性能统计和损失趋势。
deepspeed.pt cifar10_deepspeed.py --deepspeed_config ds_config.json
Warning: Permanently added '[192.168.0.22]:42227' (ECDSA) to the list of known hosts.
cmd=['pdsh', '-w', 'worker-0', 'export NCCL_VERSION=2.4.2; ', 'cd /data/users/deepscale/test/ds_v2/examples/cifar;', '/usr/bin/python', '-u', '-m', 'deepspeed.pt.deepspeed_launch', '--world_info=eyJ3b3JrZXItMCI6IFswXX0=', '--node_rank=%n', '--master_addr=192.168.0.22', '--master_port=29500', 'cifar10_deepspeed.py', '--deepspeed', '--deepspeed_config', 'ds_config.json']
worker-0: Warning: Permanently added '[192.168.0.22]:42227' (ECDSA) to the list of known hosts.
worker-0: 0 NCCL_VERSION 2.4.2
worker-0: WORLD INFO DICT: {'worker-0': [0]}
worker-0: nnodes=1, num_local_procs=1, node_rank=0
worker-0: global_rank_mapping=defaultdict(<class 'list'>, {'worker-0': [0]})
worker-0: dist_world_size=1
worker-0: Setting CUDA_VISIBLE_DEVICES=0
worker-0: Files already downloaded and verified
worker-0: Files already downloaded and verified
worker-0: bird car horse ship
worker-0: DeepSpeed info: version=2.1, git-hash=fa937e7, git-branch=master
worker-0: [INFO 2020-02-06 19:53:49] Set device to local rank 0 within node.
worker-0: 1 1
worker-0: [INFO 2020-02-06 19:53:56] Using DeepSpeed Optimizer param name adam as basic optimizer
worker-0: [INFO 2020-02-06 19:53:56] DeepSpeed Basic Optimizer = FusedAdam (
worker-0: Parameter Group 0
worker-0: betas: [0.8, 0.999]
worker-0: bias_correction: True
worker-0: eps: 1e-08
worker-0: lr: 0.001
worker-0: max_grad_norm: 0.0
worker-0: weight_decay: 3e-07
worker-0: )
worker-0: [INFO 2020-02-06 19:53:56] DeepSpeed using configured LR scheduler = WarmupLR
worker-0: [INFO 2020-02-06 19:53:56] DeepSpeed LR Scheduler = <deepspeed.pt.deepspeed_lr_schedules.WarmupLR object at 0x7f64c4c09c18>
worker-0: [INFO 2020-02-06 19:53:56] rank:0 step=0, skipped=0, lr=[0.001], mom=[[0.8, 0.999]]
worker-0: DeepSpeedLight configuration:
worker-0: allgather_size ............... 500000000
worker-0: allreduce_always_fp32 ........ False
worker-0: disable_allgather ............ False
worker-0: dump_state ................... False
worker-0: dynamic_loss_scale_args ...... None
worker-0: fp16_enabled ................. False
worker-0: global_rank .................. 0
worker-0: gradient_accumulation_steps .. 1
worker-0: gradient_clipping ............ 0.0
worker-0: initial_dynamic_scale ........ 4294967296
worker-0: loss_scale ................... 0
worker-0: optimizer_name ............... adam
worker-0: optimizer_params ............. {'lr': 0.001, 'betas': [0.8, 0.999], 'eps': 1e-08, 'weight_decay': 3e-07}
worker-0: prescale_gradients ........... False
worker-0: scheduler_name ............... WarmupLR
worker-0: scheduler_params ............. {'warmup_min_lr': 0, 'warmup_max_lr': 0.001, 'warmup_num_steps': 1000}
worker-0: sparse_gradients_enabled ..... False
worker-0: steps_per_print .............. 2000
worker-0: tensorboard_enabled .......... False
worker-0: tensorboard_job_name ......... DeepSpeedJobName
worker-0: tensorboard_output_path ......
worker-0: train_batch_size ............. 4
worker-0: train_micro_batch_size_per_gpu 4
worker-0: wall_clock_breakdown ......... False
worker-0: world_size ................... 1
worker-0: zero_enabled ................. False
worker-0: json = {
worker-0: "optimizer":{
worker-0: "params":{
worker-0: "betas":[
worker-0: 0.8,
worker-0: 0.999
worker-0: ],
worker-0: "eps":1e-08,
worker-0: "lr":0.001,
worker-0: "weight_decay":3e-07
worker-0: },
worker-0: "type":"Adam"
worker-0: },
worker-0: "scheduler":{
worker-0: "params":{
worker-0: "warmup_max_lr":0.001,
worker-0: "warmup_min_lr":0,
worker-0: "warmup_num_steps":1000
worker-0: },
worker-0: "type":"WarmupLR"
worker-0: },
worker-0: "steps_per_print":2000,
worker-0: "train_batch_size":4,
worker-0: "wall_clock_breakdown":false
worker-0: }
worker-0: [INFO 2020-02-06 19:53:56] 0/50, SamplesPerSec=1292.6411179579866
worker-0: [INFO 2020-02-06 19:53:56] 0/100, SamplesPerSec=1303.6726433398537
worker-0: [INFO 2020-02-06 19:53:56] 0/150, SamplesPerSec=1304.4251022567403
......
worker-0: [2, 12000] loss: 1.247
worker-0: [INFO 2020-02-06 20:35:23] 0/24550, SamplesPerSec=1284.4954513975558
worker-0: [INFO 2020-02-06 20:35:23] 0/24600, SamplesPerSec=1284.384033658866
worker-0: [INFO 2020-02-06 20:35:23] 0/24650, SamplesPerSec=1284.4433482972925
worker-0: [INFO 2020-02-06 20:35:23] 0/24700, SamplesPerSec=1284.4664449792422
worker-0: [INFO 2020-02-06 20:35:23] 0/24750, SamplesPerSec=1284.4950124403447
worker-0: [INFO 2020-02-06 20:35:23] 0/24800, SamplesPerSec=1284.4756105952233
worker-0: [INFO 2020-02-06 20:35:24] 0/24850, SamplesPerSec=1284.5251526215386
worker-0: [INFO 2020-02-06 20:35:24] 0/24900, SamplesPerSec=1284.531217073863
worker-0: [INFO 2020-02-06 20:35:24] 0/24950, SamplesPerSec=1284.5125323220368
worker-0: [INFO 2020-02-06 20:35:24] 0/25000, SamplesPerSec=1284.5698818883018
worker-0: Finished Training
worker-0: GroundTruth: cat ship ship plane
worker-0: Predicted: cat car car plane
worker-0: Accuracy of the network on the 10000 test images: 57 %
worker-0: Accuracy of plane : 61 %
worker-0: Accuracy of car : 74 %
worker-0: Accuracy of bird : 49 %
worker-0: Accuracy of cat : 36 %
worker-0: Accuracy of deer : 44 %
worker-0: Accuracy of dog : 52 %
worker-0: Accuracy of frog : 67 %
worker-0: Accuracy of horse : 58 %
worker-0: Accuracy of ship : 70 %
worker-0: Accuracy of truck : 59 %
补充:你可以使用 --include localhost:1 类似的命令在单卡上运行模型。此外,–num_gpus可以指定使用多少张GPU来运行。文章来源:https://www.toymoban.com/news/detail-474880.html
0x4. 总结
本文翻译了 Getting Started 和 Installation Details 和 CIFAR-10 Tutorial 三个教程,可以让新手安装和简单使用上 DeepSpeed 来做模型训练。
到了这里,关于【DeepSpeed 教程翻译】一,Getting Started ,Installation Details 和 CIFAR-10 Tutorial的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!