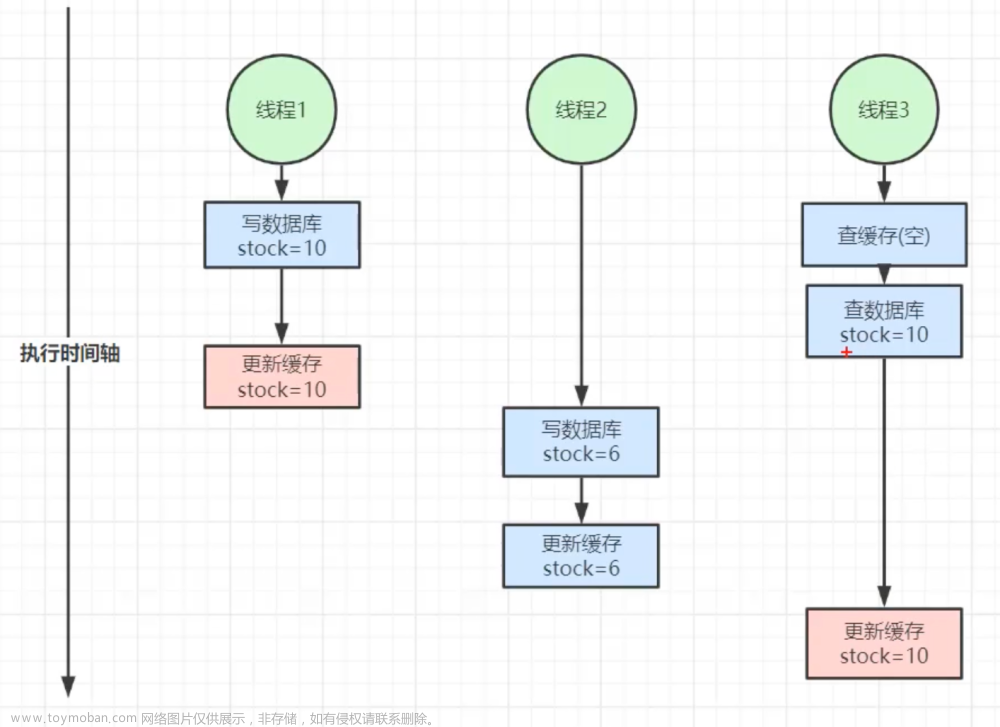
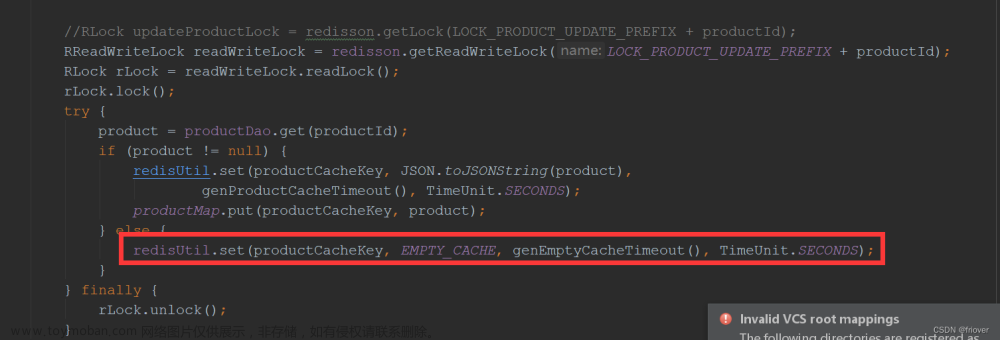
场景一:高并发频繁的数据库访问
解决方案:
-
总所周知的是:加缓存,最常见的是:加缓存中间件如 Redis,当然了这里要说的不是这个,增加一个中间件多少有点费事儿;
-
通过Java类的方式解决
POM添加jar包//添加依赖 <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>20.0</version> </dependency>//在 service 层或者 DAO 层创建了一个名为 consumerCache 的缓存池,这里用Optional包了一层是因为
Cache.get(Key)方法不能返回和存储null,如果是null会报错,具体原因感兴趣的可以看看 Cache 的源码//导包路径 import com.google.common.cache.CacheBuilder; // import com.google.common.cache.Cache; private final Cache<Long, Optional<List<PartnerCallbackDef>>> consumerCache = CacheBuilder .newBuilder() .maximumSize(1000) //最大数量 .expireAfterWrite(3, TimeUnit.MINUTES) //缓存过期时间和时间单位 .build();在查数据库的时候先尝试从缓存中获取,如果缓存中没有再执行数据库查询,将数据库查询结果缓存并返回,发生异常时会捕获并记录日志,然后返回一个空的Optional对象,在接受方法返回结果进行下一步处理的时候用
isPresent()判断一下就好了。private Optional<List<PartnerCallbackDef>> getConsumerCache(final Long key) { try { return consumerCache.get(key, () -> Optional.ofNullable(partnerCallbackDefDao.getByTypeAndPartnerId(Constants.CALLBACK_DEF_TYPE_CONSUMER, key))); } catch (ExecutionException e) { LogUtils.error(log, "读取缓存数据异常", e); return Optional.empty(); } }PartnerCallbackDefDao 中的方法
getByTypeAndPartnerId没有什么特殊逻辑,就是对数据库的访问public List<PartnerCallbackDef> getByTypeAndPartnerId(String type, Long partnerId) { return mapper.getByTypeAndPartnerId(type, partnerId); }这样很简单的就实现了对数据库访问的缓存,在调用
getConsumerCache方法获取指定ID的数据时,会先从缓存中获取,缓存中获取不到或缓存过期时才会从数据集中从新拉取,并且在Cache.get(Key)方法中,只要我们保证方法的入参 Key 是线程安全的,那么方法Cache.get(Key)就是线程安全的。
场景二:大数据量的同步
解决方案:
思路:
1. 首先我们可以将数据量进行分割来分批次进行同步,以防止大量的数据一次性打到数据库对数据库造成压力;
2. 在Controller层做校验,用redis存储请求数据,过滤掉重复的请求内容,以实现接口的幂等校验;还可以做请求的数据量校验和限流
3. 根据实际业务需求考虑同步方式是增量同步还是全量同步,其中增量同步的实现方式是将接收到的请求数据进行数据库的过滤,只进行新增和修改操作;而全量同步则是不做过滤处理,将接收到的请求数据全部保存到数据库。文章来源:https://www.toymoban.com/news/detail-474957.html
代码:文章来源地址https://www.toymoban.com/news/detail-474957.html
数据分割工具类
import com.google.common.collect.Maps;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
/**
* @author: luce
* @Date: 2023/4/20 14:08
* @Description:
*/
public class SplitUtil {
/**
* 按指定大小进行分割
* @param num 分割大小
* @param dataList 需要分割的集合
* @param <T>
* @return
*/
public static <T> Map<Integer, List<T>> splitData(Integer num, List<T> dataList) {
HashMap<Integer, List<T>> map = Maps.newHashMap();
int size = dataList.size();
//分割大小
int count = SplitUtil.countNumBydivisor(size, num);
for (int i = 0; i < count; i++) {
int lastNum = num * (i + 1);
LinkedList<T> linkedList = new LinkedList<>();
for (int j = num * i; j < lastNum && j < size; j++) {
linkedList.add(dataList.get(j));
}
map.put(i, linkedList);
}
return map;
}
/**
* @Description:按除数分割
* @params: [size , divisor]
* @return: int
* @Author: jiangpan
* @Date: 2018/12/23 20:56
**/
public static int countNumBydivisor(int size, int divisor){
int num = size % divisor;
if (num > 0) {
num = size / divisor + 1;
} else {
num = size / divisor;
}
return num ;
}
}
使用样例: Map<Integer, List<UserDTO>> userMap = SplitUtil.splitData(splitSize, userDTOList);
userMap.values().forEach(userList -> {
TemResponseDTO<Void> res = temOpenapiHttpClient.syncUser(openapiToken, userList);
log.info("人员同步返回结果:{}", res.getErrorDescription());
});
幂等处理参考
/**
* 获取并过滤redis中的数据
* @param partnerId 请求的企业ID
* @param userBaseGroundList 请求参数
* @return 返回
*/
public Set<UserBaseGround> getUserBaseGroundMd5Data(Long partnerId, List<UserBaseGround> userBaseGroundList) {
Set<UserBaseGround> costSet = Sets.newLinkedHashSet();
//父key
String groundMd5Key = GROUND_MD5_KEY.replace("{0}", String.valueOf(partnerId));
userBaseGroundList.forEach(v -> {
//子key
String childKey = v.getEmpCode() + v.getCityName() + v.getAddressType();
String md5xString = DigestUtils.MD5_64bit(JSONObject.toJSONString(v));
String value = RedisCacheUtils.get(groundMd5Key, childKey);
if (StringUtils.isEmpty(value) || !Objects.equals(md5xString, value)) {
costSet.add(v);
RedisCacheUtils.hdel(groundMd5Key, childKey);
}
});
return costSet;
}
/**
* 保存MD5后的人员常驻地入参
*/
public void setUserBaseGroundMd5Data(Long partnerId, UserBaseGround userBaseGround) {
String groundMd5Key = GROUND_MD5_KEY.replace("{0}", String.valueOf(partnerId));
String childKey = userBaseGround.getEmpCode() + userBaseGround.getCityName() + userBaseGround.getAddressType();
String md5xString = DigestUtils.MD5_64bit(JSONObject.toJSONString(userBaseGround));
RedisCacheUtils.hSet(groundMd5Key, childKey, md5xString, Integer.parseInt(userMd5Expired));
}
使用样例:
//获取并过滤redis中的组织数据
Set<UserBaseGround> userBaseGroundMd5Data = userBaseGroundCommon.getUserBaseGroundMd5Data(partnerId, userBaseGroundList);
if (CollectionUtils.isEmpty(userBaseGroundMd5Data)) {
LogUtils.info(logger, "hash过滤后无数据,用户常驻地同步成功");
super.success("用户常驻地同步成功");
return;
}
//将成功保存到数据库的请求数据缓存
setUserBaseGroundMd5Data(partnerId, userBaseGround);
检验请求数据量
/***
* 检验请求数据量
* @param size
* @param partnerId
*/
protected void rateLimit(Integer size, Long partnerId) {
String requestURI = getRequest().getRequestURI();
String key = REQUEST_CURRENT_LIMIT + requestURI + partnerId;
Long value = RedisCacheUtils.incr(key, Long.valueOf(size), 60);
JSONObject resquestConfig = getResquestConCurrentConfig(requestURI);
if (value > resquestConfig.getIntValue(INTERFACE_CONCURRENT_VALUE)) {
LogUtils.warn(logger, "请求超过频率限制:请求接口地址:{}, 企业id:{}, 缓存数量:{}, 当前同步数量:{}", requestURI, partnerId, value, size);
// 去掉才加的数
RedisCacheUtils.decr(key, value);
throw new BizException(RATE_LIMITED.name(), RATE_LIMITED.getMessage());
}
}
/**
* 获取并发限制apollo中的配置
*
* @param requestURI
* @return
*/
protected JSONObject getResquestConCurrentConfig(String requestURI) {
List<JSONObject> jsonObjects = JSONArray.parseArray(requestConCurrentLimit, JSONObject.class);
return jsonObjects.stream()
.filter(item -> item.getString(INTEFACE_PATH).equals(requestURI) == true)
.findAny()
.orElse(null);
}
接口限流
/***
* 接口限流
* @param partnerId
* @param expinedSecond
*/
protected void frequencyLimit(Long partnerId, Integer expinedSecond) {
if (expinedSecond == null) {
expinedSecond = 60;//默认60s有效时间
}
String requestURI = getRequest().getRequestURI();
String key = REQUEST_CURRENT_LIMIT + partnerId + ":" + requestURI;
RedisSingleCache redisCache = (RedisSingleCache) RedisCacheUtils.getRedisCache();
Jedis jedisCluster = null;
try {
jedisCluster = redisCache.getJedis();
long calledTimes = StringUtils.isEmpty(jedisCluster.get(key)) ? 0L : Long.parseLong(jedisCluster.get(key)); //已调用次数
int limitValue = getFrequencyLimitValue(requestURI); //配置的频率限制次数
if (calledTimes >= limitValue) {
LogUtils.warn(logger, "请求超过频率限制:请求接口地址:{}, 企业id:{}, 已调用数量:{},接口限制数量:{}",
requestURI, partnerId, calledTimes, limitValue);
throw new BizException(RATE_LIMITED.name(), RATE_LIMITED.getMessage());
}
if (calledTimes != 0L) {
Long ttl = RedisCacheUtils.ttl(key);
if (ttl != null && ttl > 0) {
expinedSecond = ttl.intValue();
}
}
RedisCacheUtils.incr(key, 1L, expinedSecond);
} catch (Exception e) {
LogUtils.warn(logger, "接口限流出现异常:{}", e);
throw new BizException("请求失败,请联系管理员:{}", e.getMessage());
} finally {
if (Objects.nonNull(jedisCluster)) {
jedisCluster.close();
}
}
}
//获取接口频率限制值,如果未配置则表示不限,返回Integer.MAX_VALUE
private int getFrequencyLimitValue(String requestURI) {
int rs = Integer.MAX_VALUE;
JSONObject requestConfig = getResquestConCurrentConfig(requestURI);
int value = requestConfig.getIntValue(INTERFACE_CONCURRENT_VALUE);
if (value > 0) {
rs = value;
}
return rs;
}
增量同步实现
更新中....
到了这里,关于Java项目的性能优化样例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!