1、简介
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
GitHub:https://github.com/THUDM/ChatGLM-6B
2、硬件要求
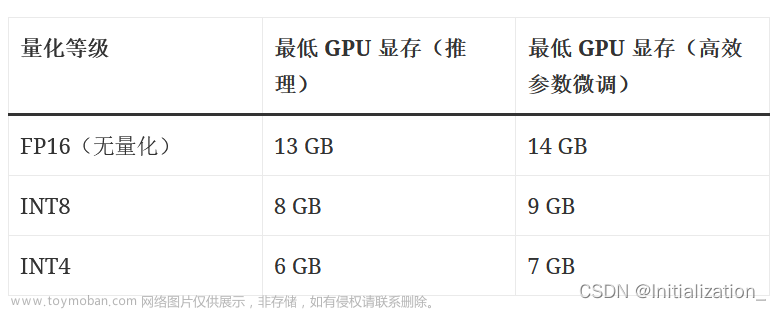
| 量化等级 | 最低 GPU 显存(推理) | 最低 GPU 显存 |
|---|---|---|
| FP16(无量化) | 13 GB | 14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
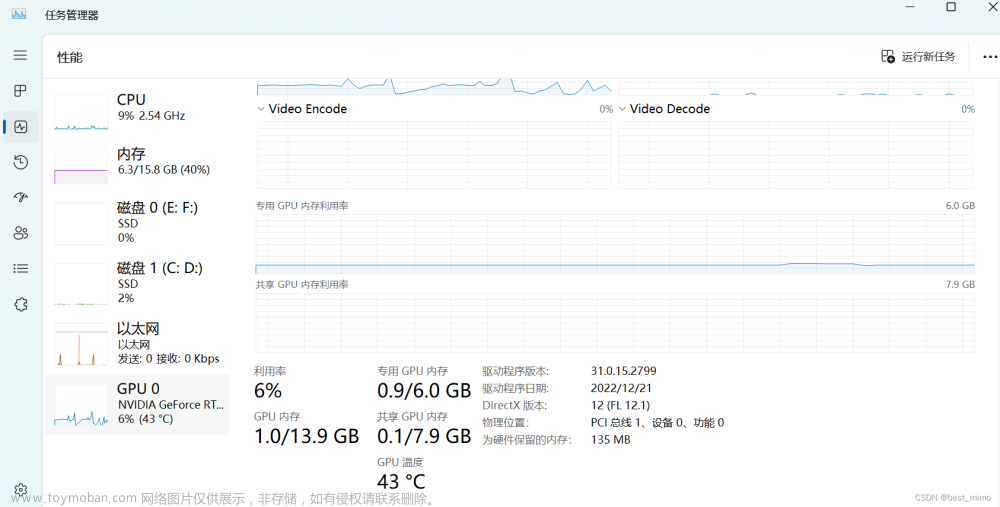
本机硬件:Win11 系统 + GeForce RTX 3070Ti 8GB 显存 + 16G内存
3、环境准备
3.1 安装Python
到Python官网下载https://www.python.org/getit/指定版本:Python 3.10.0
安装这边就不多说了。
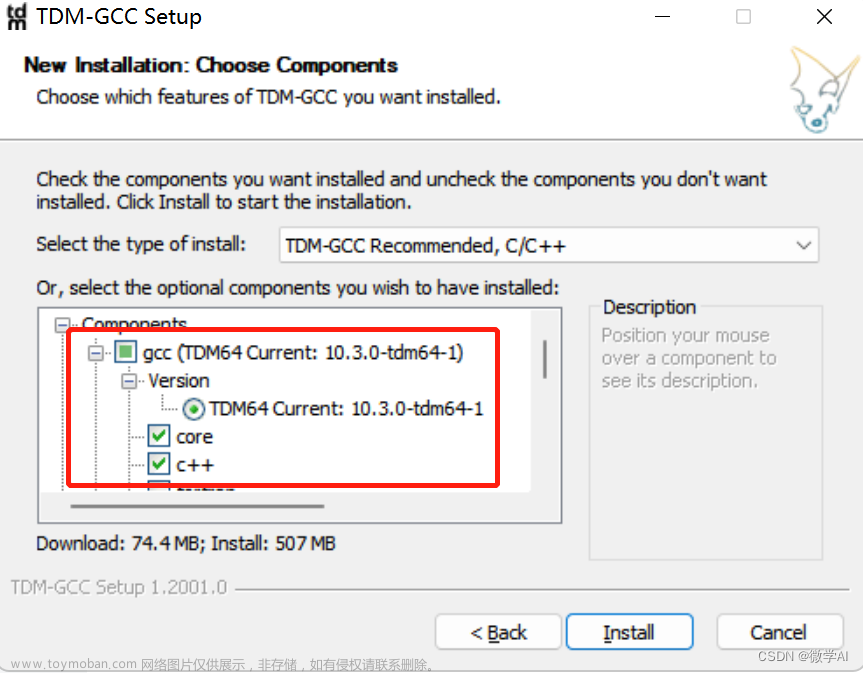
3.2 安装TDM-GCC
如果需要在 cpu 上运行量化后的模型, 还需要安装 gcc 与 openmp。多数 Linux 发行版默认已安装。对于 Windows ,可在安装 TDM-GCC 时勾选 openmp。Windows 测试环境 gcc 版本为 TDM-GCC 10.3.0, Linux 为 gcc 11.3.0。
官网地址:https://jmeubank.github.io/tdm-gcc/

3.3 安装插件
进入当前从https://github.com/THUDM/ChatGLM-6B下载的目录下CMD:
使用 pip 安装依赖:
pip install gradio
pip install -r requirements.txt
遇到问题:
AssertionError: Torch not compiled with CUDA enabled
出现以上问题是因为pytorch版本和CUDA版本不一致导致的。
解决方法:
A、通过nvidia-smi查看当前显存CUDA的版本号,从以下版本我们可以看出CUDA版本11.6
B、然后我们去pytorch查找CUDA版本11.6对应的版本
pytorch官网:https://pytorch.org/get-started/previous-versions/
找到Wheel pip安装模式CUDA11.6版本对应的指令
在当前ChatGLM-6B目录下,执行匹配的指令:
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
3.4、模型加载
以上代码会由 transformers 自动下载模型实现和参数。完整的模型实现可以在 Hugging Face Hub。如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。
从 Hugging Face Hub 下载模型需要先安装Git LFS,然后运行
git clone https://huggingface.co/THUDM/chatglm-6b
如果你从 Hugging Face Hub 上下载 checkpoint 的速度较慢,可以只下载模型实现
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm-6b
然后从这里手动下载模型参数文件,并将下载的文件替换到本地的 chatglm-6b 目录下。
将模型下载到本地之后,将以上代码中的 THUDM/chatglm-6b 替换为你本地的 chatglm-6b 文件夹的路径,即可从本地加载模型。
因本机显存只有8G,顾采用4-bit来搭建本地放模型,直接从服务器下载4-bit资源到本地,服务器地址:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm-6b-int4
下载完成直接存放到chatglm-6b-int4目录底下。
4、低成本部署
因网络下载模型缓慢,所以采用本地加载的方式来加载模型,顾需要调整当前web_demo.py等启动UI脚本,统一将THUDM/chatglm-6b-int4调整本地目录。
tokenizer = AutoTokenizer.from_pretrained("chatglm-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm-6b-int4", trust_remote_code=True).half().cuda()
4.1 模型量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
model=AutoModel.from_pretrained("chatglm6b",trust_remote_code=True).quantize(4).half().cuda()
进行 2 至 3 轮对话后,8-bit 量化下 GPU 显存占用约为 10GB,4-bit 量化下仅需 6GB 占用。随着对话轮数的增多,对应消耗显存也随之增长,由于采用了相对位置编码,理论上 ChatGLM-6B 支持无限长的 context-length,但总长度超过 2048(训练长度)后性能会逐渐下降。
量化过程需要在内存中首先加载 FP16 格式的模型,消耗大概 13GB 的内存。如果你的内存不足的话,可以直接加载量化后的模型,仅需大概 5.2GB 的内存:
model = AutoModel.from_pretrained("chatglm-6b-int4", trust_remote_code=True).half().cuda()
4.2 CPU 部署
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("chatglm-6b", trust_remote_code=True).float()
如果你的内存不足,可以直接加载量化后的模型:
model = AutoModel.from_pretrained("chatglm-6b-int4",trust_remote_code=True).float()
4.3 启动UI
4.3.1 网页版 Demo
首先安装 Gradio:pip install gradio,然后运行仓库中的 web_demo.py:
python web_demo.py

4.3.2 命令行 Demo
运行仓库中 cli_demo.py:
python cli_demo.py
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。
4.3.3 API请求
首先需要安装额外的依赖 pip install fastapi uvicorn,然后运行仓库中的 api.py:
python api.py
默认部署在本地的 8000 端口,通过 POST 方法进行调用文章来源:https://www.toymoban.com/news/detail-475071.html
curl -X POST "http://127.0.0.1:8000" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
得到的返回值为文章来源地址https://www.toymoban.com/news/detail-475071.html
{
"response":"你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。",
"history":[["你好","你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。"]],
"status":200,
"time":"2023-03-23 21:38:40"
}
到了这里,关于Python:清华ChatGLM-6B中文对话模型部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!