Python如何抓取数据
介绍
Python是一种功能强大的编程语言,它被广泛使用于网络抓取和数据分析。无论您是想要从网站上抓取数据,还是使用API抓取数据,Python都是一种非常适合的工具。在本文中,我们将介绍Python如何抓取数据,以及一些有用的技巧和工具。
网络抓取
网络抓取是指从Internet上获取数据的过程。Python可以使用很多不同的库和工具来进行网络抓取。以下是一些最常用的工具:
Requests
Requests是Python中最受欢迎的HTTP库之一。它能够让您轻松地向Web服务器发送请求,并处理来自服务器的响应。Requests还具有友好的API和丰富的文档,是Python许多开发人员的首选。
以下是一个快速的示例,演示如何使用requests库获取一个网页的内容:
import requests
response = requests.get('https://www.example.com')
print(response.text)
Beautiful Soup
Beautiful Soup是一个流行的Python库,用于HTML和XML解析。它使您能够轻松处理和搜索HTML及XML文档中的数据。以下是一个示例,演示如何使用Beautiful Soup从HTML文档中获取所有的a标签:
from bs4 import BeautifulSoup
import requests
response = requests.get('https://www.example.com')
soup = BeautifulSoup(response.text, 'html.parser')
for link in soup.find_all('a'):
print(link.get('href'))
Scrapy
Scrapy是一个开源的Web爬虫框架,使用Python编写。它具有非常强大的功能,能够执行高效的异步网络抓取。Scrapy还有许多扩展功能,可以使用CSS选择器和XPath语法进行数据提取,并使用Item Pipelines和Middleware来处理数据。以下是一个快速的示例,演示如何使用Scrapy抓取一个网站:
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example_spider'
start_urls = ['http://www.example.com/']
def parse(self, response):
for sel in response.xpath('//a'):
title = sel.xpath('text()').extract_first()
link = sel.xpath('@href').extract_first()
yield {'title': title, 'link': link}
使用API获取数据
许多Web应用程序都提供API接口,允许开发人员通过API获取数据。Python中有许多库可以使用,用于使用API获取数据。以下是一些最常用的库:
Requests
Requests库不仅可以从Web服务器获取数据,还可以使用API进行数据获取。大多数API接口都使用HTTP协议,这是Requests库非常擅长的。
以下是一个示例,演示如何使用Requests库获取GitHub上的公共API数据:
import requests
response = requests.get('https://api.github.com/user', auth=('user', 'pass'))
json_data = response.json()
PyPI
PyPI是Python Package Index的缩写,是Python应用程序和库的中央存储库。PyPI上的大多数包都具有API接口,可以使用Python库进行访问。以下是一个示例,演示如何使用PyPI API获取Pillow库的最新版本:
import requests
response = requests.get('https://pypi.python.org/pypi/Pillow/json')
json_data = response.json()
latest_version = json_data['info']['version']
Tweepy
Tweepy是一个使用Twitter API进行OAuth身份验证的Python库。Tweepy使您能够轻松地从Twitter获取数据,并使用其中的功能。以下是一个示例,演示如何使用Tweepy获取Twitter用户的最近10条推文:
import tweepy
auth = tweepy.OAuthHandler("consumer_key", "consumer_secret")
auth.set_access_token("access_token", "access_token_secret")
api = tweepy.API(auth)
tweets = api.user_timeline(count=10)
for tweet in tweets:
print(tweet.text)
结论
在本文中,我们介绍了Python如何抓取数据。我们讨论了使用Python进行网络抓取和使用API获取数据。使用Python进行数据抓取非常有用,因为Python具有丰富的库和工具,使数据抓取变得更加容易。如果您需要从Web或API获取数据,那么Python是您的明智选择。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。文章来源:https://www.toymoban.com/news/detail-475186.html
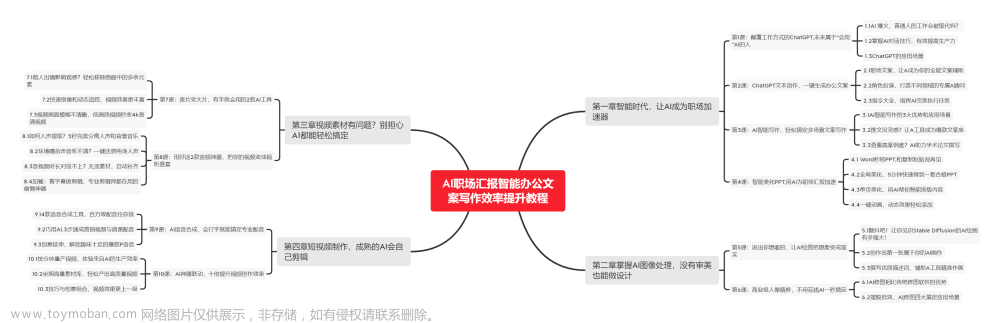
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具 文章来源地址https://www.toymoban.com/news/detail-475186.html
文章来源地址https://www.toymoban.com/news/detail-475186.html
🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
到了这里,关于chatgpt赋能python:Python如何抓取数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!