在《如何计算一个实例占用多少内存?》中我们知道一个值类型或者引用类型的实例在内存中占多少字节。如果我们知道这段连续的字节序列的初始地址,我们就能够将代表该实例的字节内容读取出来。在接下来的内容中,我们将利用一个简单的方法输出指定实例的字节序列,并此次分析值类型和引用类型实例在内存的布局。
一、读取实例在内存中的字节
二、查看值类型和引用类型实例的内存字节
三、存储方法表地址
四、Object Header的内存布局
五、存储“瘦锁”
六、存储哈希码
七、存储SyncBlock Index
一、读取实例在内存中的字节
如下所示的PrintBytes<T>会将指定实例在内存中的字节输出到控制台上。如代码片段所示,我们先调用《如何计算一个实例占用多少内存?》中定义了SizeCalculator将承载实例内容的字节数计算出来,并创建对应长度的字节数组来存放读取的字节。如果指定的变量value是一个结构体(值类型),意味着变量会直接指向结构体的首字节。在这种情况下,我们只需要将该变量的引用转换成指针(void*),然后将其转换成IntPtr对象,并作为起始地址调用Marshal的Copy方法将指定数量的字节拷贝到创建的字节数组就可以了。
public static class BytesPrinter { public unsafe static void PrintBytes<T>(T value) { var size = SizeCalculator.Instance.SizeOf(() => value); var bytes = new byte[size]; var pointer = Unsafe.AsPointer(ref value); IntPtr head = typeof(T).IsValueType ? new IntPtr(pointer) : *(IntPtr*)pointer - IntPtr.Size; Marshal.Copy(head, bytes, 0, size); Console.WriteLine($"[{size}]{BitConverter.ToString(bytes)}"); } public static string AsString(this IntPtr ptr) => BitConverter.ToString(BitConverter.GetBytes(ptr.ToInt64())); }
对于引用类型,整个过程就要复杂一些。此时指定的变量value指向的是目标对象的地址,所以在将此变量引用转换成void*指针后,还需要将其转换成IntPtr*指针,并最终将指针的内容(也就是目标对象的地址)解析出来。由于变量指向的地址并非目标实例映射内存字节的首地址,仅仅是存储方法表地址的地方,所以还需要向前移动一个身位(IntPtr.Size)才是实例所在内存片段的首地址。在将所需字节拷贝到创建的字节数组之后,我们将其格式化成字符串输出到控制台上。另一个AsString扩展方法会将指定IntPtr对象表示的内存地址输出到控制台上,我们会在后续的演示中使用到它。顺便把《如何计算一个实例占用多少内存?》中介绍的SizeCalculator类型定义给出来。
public class SizeCalculator { private static readonly ConcurrentDictionary<Type, int> _sizes = new(); private static readonly MethodInfo _getDefaultMethod = typeof(SizeCalculator).GetMethod(nameof(GetDefault), BindingFlags.Static | BindingFlags.NonPublic)!; public static readonly SizeCalculator Instance = new(); public int SizeOf(Type type, Func<object?>? instanceAccessor = null) { if (_sizes.TryGetValue(type, out var size)) return size; if (type.IsValueType) return _sizes.GetOrAdd(type, CalculateValueTypeInstance); object? instance; try { instance = instanceAccessor?.Invoke() ?? Activator.CreateInstance(type); } catch { throw new InvalidOperationException("The delegate to get instance must be specified."); } return _sizes.GetOrAdd(type, type => CalculateReferenceTypeInstance(type, instance)); } public int SizeOf<T>(Func<T>? instanceAccessor = null) { if (instanceAccessor is null) return SizeOf(typeof(T)); Func<object?> accessor = () => instanceAccessor(); return SizeOf(typeof(T), accessor); } public int CalculateValueTypeInstance(Type type) { var instance = GetDefaultAsObject(type); var fields = type.GetFields(BindingFlags.DeclaredOnly | BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic) .Where(it => !it.IsStatic) .ToArray(); if (fields.Length == 0) return 0; var tupleType = typeof(ValueTuple<,>).MakeGenericType(type, type); var tupple = tupleType.GetConstructors()[0].Invoke(new object?[] { instance, instance }); var addresses = GenerateFieldAddressAccessor(tupleType.GetFields()).Invoke(tupple).OrderBy(it => it).ToArray(); return (int)(addresses[2] - addresses[0]); } public int CalculateReferenceTypeInstance(Type type, object? instance) { var fields = GetBaseTypesAndThis(type) .SelectMany(type => type.GetFields(BindingFlags.DeclaredOnly | BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic)) .Where(it => !it.IsStatic).ToArray(); if (fields.Length == 0) return type.IsValueType ? 0 : 3 * IntPtr.Size; var addresses = GenerateFieldAddressAccessor(fields).Invoke(instance); var list = new List<FieldInfo>(fields); list.Insert(0, null!); fields = list.ToArray(); Array.Sort(addresses, fields); var lastFieldOffset = (int)(addresses.Last() - addresses.First()); var lastField = fields.Last(); var lastFieldSize = lastField.FieldType.IsValueType ? CalculateValueTypeInstance(lastField.FieldType) : IntPtr.Size; var size = lastFieldOffset + lastFieldSize; // Round up to IntPtr.Size int round = IntPtr.Size - 1; return ((size + round) & (~round)) + IntPtr.Size; static IEnumerable<Type> GetBaseTypesAndThis(Type? type) { while (type is not null) { yield return type; type = type.BaseType; } } } private static Func<object?, long[]> GenerateFieldAddressAccessor(FieldInfo[] fields) { var method = new DynamicMethod( name: "GetFieldAddresses", returnType: typeof(long[]), parameterTypes: new[] { typeof(object) }, m: typeof(SizeCalculator).Module, skipVisibility: true); var ilGen = method.GetILGenerator(); // var addresses = new long[fields.Length + 1]; ilGen.DeclareLocal(typeof(long[])); ilGen.Emit(OpCodes.Ldc_I4, fields.Length + 1); ilGen.Emit(OpCodes.Newarr, typeof(long)); ilGen.Emit(OpCodes.Stloc_0); // addresses[0] = address of instace; ilGen.Emit(OpCodes.Ldloc_0); ilGen.Emit(OpCodes.Ldc_I4, 0); ilGen.Emit(OpCodes.Ldarg_0); ilGen.Emit(OpCodes.Conv_I8); ilGen.Emit(OpCodes.Stelem_I8); // addresses[index] = address of field[index + 1]; for (int index = 0; index < fields.Length; index++) { ilGen.Emit(OpCodes.Ldloc_0); ilGen.Emit(OpCodes.Ldc_I4, index + 1); ilGen.Emit(OpCodes.Ldarg_0); ilGen.Emit(OpCodes.Ldflda, fields[index]); ilGen.Emit(OpCodes.Conv_I8); ilGen.Emit(OpCodes.Stelem_I8); } ilGen.Emit(OpCodes.Ldloc_0); ilGen.Emit(OpCodes.Ret); return (Func<object?, long[]>)method.CreateDelegate(typeof(Func<object, long[]>)); } private static T GetDefault<T>() where T : struct => default!; private static object? GetDefaultAsObject(Type type) => _getDefaultMethod.MakeGenericMethod(type).Invoke(null, Array.Empty<object>()); }
二、查看值类型和引用类型实例的内存字节
在如下的代码片段中,我们定义的结构体FoobarStructure和类FoobarClass具有两个字段Foo和Bar,对应类型分别是Byte和Int32。我们分别创建了它们的实例,并将这两个字段设置成255(0xFF)和65535(0xFFFF)。我们将它们作为参数调用了上面定义的PrintBytes方法。
BytesPrinter.PrintBytes(new FoobarStructure(255, 65535)); BytesPrinter.PrintBytes(new FoobarClass(255, 65535)); public struct FoobarStructure { public byte Foo; public int Bar; public FoobarStructure(byte foo, int bar) { Foo = foo; Bar = bar; } } public class FoobarClass { public byte Foo; public int Bar; public FoobarClass(byte foo, int bar) { Foo = foo; Bar = bar; } }
程序执行后会将指定的FoobarStructure和FoobarClass实际对应的字节输出控制台上。为了更好地理解该字节序列每一部分的内容,我特意按照如下的方式添加了方括号对它们进行了分割。从下面的内容可以看出,虽然Byte和Int32对应的字节数分别为1和4,但是FoobarStructure这个结构体的字节数却是8,三个空白字节(红色标记)是为了内存对齐额外添加的“留白(Padding,红色标注)”。从字节的内容还可以看出,内存中体现的字段顺序默认与它们在结构体中定义的顺序是一致的(Foo:FF;Bar:FF-FF-00-00)。顺便提一下,基元类型在内存中是按照“小端序”存储的。
[8][FF-00-00-00]-[FF-FF-00-00]
[24][00-00-00-00-00-00-00-00]-[38-39-78-B3-FD-7F-00-00]-[FF-FF-00-00-FF-00-00-00]
FoobarClass实例在内存中的字节数要多很多,变成了24。第一组8字节是代表ObjectHeader(包含4字节用于内存对齐的空字节),第2组8字节代表FoobarClass类型的方法表的内存地址。两个字段的内容体现在最后一组8字节中,可以看出它们内容与FoobarStructure不一样,这是因为在默认的情况下,结构体采用Sequential(与定义一致),而类则采用Auto,其目的是为了满足内存对其规则的情况下对字段进行重新排序,以节省内存空间。在这里Bar字段(FF-FF-00-00)被放在Foo字段(FF)的前面。由于24是引用类型实例在内存中的最小字节数(针对x64架构),字段重排针对内存的“压缩”没有体现出来。
三、存储方法表地址
.NET运行时中针对“类型”的描述信息几乎都来自于方法表这个内部的数据结构。引用类型实例在内存中的第二部分内容(ObjectHeader之后)存放的就是对应方法表的地址,实例和类型就是通过这种方式关联起来的。在C#中,我们也可以利用表示“类型句柄(Type Handle)”的RuntimeTypeHandle对象得到对应类型方法表的地址。在如下所示的代码片段中,我们在输出FoobarClass对象的内存字节序列后,我们进一步获得了FoobarClass类型的TypeHandle对象,该对象的Value属性返回的就是方法表地址。我们调用上面定义的AsString扩展方法将其转换成格式化字符串后输出到控制台上。
BytesPrinter.PrintBytes(new FoobarClass(255, 65535)); Console.WriteLine("[TypeHandle]{0}",typeof(FoobarClass).TypeHandle.Value.AsString());
从如下所示的输出结果可以看出,实例内存字节承载的和TypeHandle提供的方法表地址是一致的。
[24]00-00-00-00-00-00-00-00-38-37-78-B3-FD-7F-00-00-FF-FF-00-00-FF-00-00-00
[TypeHandle]38-37-78-B3-FD-7F-00-00
四、Object Header的内存布局
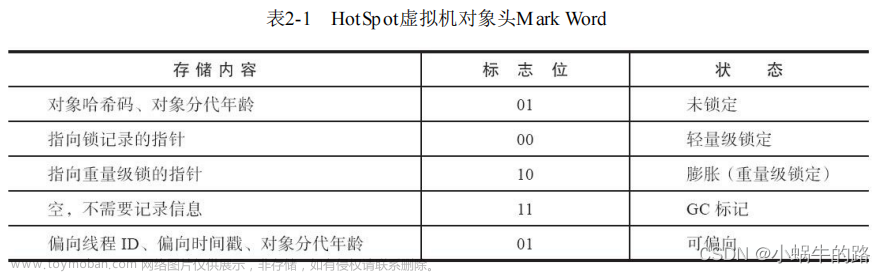
我看到一些文档将Object Header命名为SyncBlock Index/Number,这种命名不能算错,但至少没有完整地体现Object Header的作用以及存储方式。当我们对某个对象加锁的时候,系统会使用一个名为SyncBlock的内部数据结果与之关联,SyncBlock中会包含当前线程ID和递归等级等信息。这样的SyncBlock被保存在一个SyncBlock Table中,它在这个表中的索引会存储在Object Header。

实际上SyncBlock Index只体现了Object Header只体现了Object Header的一种使用场景而已。这种将SyncBlock Index存储在Object Header中实现的锁被称为 “胖锁(Fat Lock)” ,既然有胖锁,自然就有瘦锁(Thin Lock),瘦锁直接将同步信息存储在Object Header中。由于不需要访问SyncBlock Table,瘦锁的性能要高很多。除了用于存储同步信息,Object Header还可以用来缓存对象的Hash码。上图体现了Object Header典型的三种存储场景:
- 瘦锁:使用Object Header的低27位存储当前AppDomain索引(16-26)、锁的递归等级(10-15)和线程ID(0-9);
- 哈希码:使用Object Header的低26位存储对象的哈希码;
- SyncBlock Index: 使用Object Header的低26位存储关联的SyncBlock 在SyncBlock Table的索引。
为了确定Object Header存储的内容,它的高5位被预留了下来,它们分别表示:
- 27-BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX:确定存储的内容是否是哈希或者SyncBlock Index;
- 28-BIT_SBLK_SPIN_LOCK:CLR使用它以原子操作的方式修改Object Header的内容;
- 29- BIT_SBLK_GC_RESERVE :GC在执行过程中用于标记对象是否被固定(pined)
- 30- BIT_SBLK_FINALIZER_RUN:GC用于确定对象的析构函数是否被调用;
- 31- BIT_SBLK_AGILE_IN_PROGRESS:在debug build下被用来确定两个跨AppDomain应用的对象之间是否存在死循环。
对于上图中的第2/3中存储场景下,由于BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX只能确定承载的内容是否是哈希码还是SyncBlock Index,我们还得使用第26位(0-base)作进一步区分。这个比特被称为BIT_SBLK_IS_HASHCODE,顾名思义,它表示承载得内容是否是对象得哈希码。
五、存储“瘦锁”
在了解了Object Header的字节布局后,我们利用我们定义的方法将对象的Object Header的内容读取出来,看看它的内容是否与描述的一致。我们先来看看基于“瘦锁”的存储方式。
await Task.Yield(); PrintThreadId(); var foobar = new Foobar(); lock (foobar) { BytesPrinter.PrintBytes(foobar); lock (foobar) { BytesPrinter.PrintBytes(foobar); lock (foobar) { BytesPrinter.PrintBytes(foobar); Debugger.Break(); } } } static void PrintThreadId() { var bytes = BitConverter.GetBytes(Environment.CurrentManagedThreadId); Console.WriteLine($"Thread Id: {BitConverter.ToString(bytes)}"); } public class Foobar{}
在如上所示的演示程序中,我们定义了一个“空”的类Foobar。await Task.Yield()之后的操作将以异步的方式执行,为了确定Object Header中是否包含当前线程的ID,我们将线程ID以16进制的形式输出到控制台上。然后我们创建了一个Foobar对象,然后嵌套的方式锁定它,并在锁定上下文中将改对象的内存字节输出来。
Thread Id: 06-00-00-00
[24]00-00-00-00-06-00-00-00-10-02-66-4C-FA-7F-00-00-00-00-00-00-00-00-00-00
[24]00-00-00-00-06-04-00-00-10-02-66-4C-FA-7F-00-00-00-00-00-00-00-00-00-00
[24]00-00-00-00-06-08-00-00-10-02-66-4C-FA-7F-00-00-00-00-00-00-00-00-00-00
如上所示的程序运行后在控制台上的输出,我们可以看到当前线程ID是6(采用小端字节序)。按照我们上面介绍的内存布局,0-9这10位用来表示线程,由于三次输出都是在同一个线程中进行的,所以这10位比特(红色)是一致的(0000000110),对应的值位6,刚好是当前线程ID。10-15这6位(紫色)表示递归等级,解析出来值分别是0,1和2,与我们的程序正好吻合。
[0000 0][000 0000 0000] [0000 00][00 0000 0110]
[0000 0][000 0000 0000] [0000 01][00 0000 0110]
[0000 0][000 0000 0000] [0000 10][00 0000 0110]
我们在最里层的lock语句中调用了Debugger的Break方法,所以程序会在这里停下来。如果此时我们将当前进程的Dump抓下来,通过执行dumpheap -thinlock命令会将所有“瘦锁”列出来,从输出的嵌套等级(2)和dumpobj的显式结果可以看出这个瘦锁就是Foobar对象。

六、存储哈希码
我们接下来采用类似的方式演示Object Header针对哈希码的缓存。如下面的代码片段所示,我们创建了上面定义的Foobar对象,在将其内存字节打印出来之前,我们先将其GetHashCode方法返回的哈希码打印来。
var foobar = new Foobar(); var hashCode = foobar.GetHashCode(); PrintHashCode(hashCode); BytesPrinter.PrintBytes(foobar); static void PrintHashCode(int hashCode) { var bytes = BitConverter.GetBytes(hashCode); Console.WriteLine($"Hash Code: {BitConverter.ToString(bytes)}"); }
从下面的输出可以看出整个Object Header的内容应该和哈希码是有关系,因为至少可以看到前面3个字节内容(9D-0D-3C)的完全一致的,但是为什么最后一个字节不同呢?
Hash Code: 9D-0D-3C-03
[24]00-00-00-00-9D-0D-3C-0F-10-86-78-E0-FA-7F-00-00-00-00-00-00-00-00-00-00
再次回到上面的描述,在第二种用于存储哈希码的场景中,Object Header利用低26位来存储哈希,所以我们按照如下的方式将其低26位提取出来后就会发现对应的值就是哈希码。在看前面的6位,BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX和BIT_SBLK_IS_HASHCODE位均为1,这样就可以确定后26位存储的就是哈希码了。
0F 3C 0D 9D
00001111 00111100 00001101 10011101
00000011 00111100 00001101 10011101
03 3C 0D 9D
由于Object类型的GetHashCode方法的返回类型为Int32,如果我们重写了这个方法,就可能导致ObjectHeader无法使用26位来存放哈希值。比如我们将重写了演示实例所用的Foobar类型,让重写的GetHashCode返回Int32.MaxValue。
public class Foobar { public override int GetHashCode() => int.MaxValue; }
很显然Foobar对象的哈希码就无法存储在Object Header中,如下的输出体现了这一点。其实不管计算出来的哈希码能否使用26个比特来表示,只要类型重写了GetHashCode方法且没有直接返回base.GetHashCode(),使用Object Header来缓存哈希码的策略就会失效。这一点告诉我们:当我们需要试图去重写某个类的GetHashCode方法,先考虑一下这个类型是否应该定义成结构体。
Hash Code: FF-FF-FF-7F
[24]00-00-00-00-00-00-00-00-70-27-7A-E0-FA-7F-00-00-00-00-00-00-00-00-00-00
七、存储SyncBlock Index
我们使用如下的代码来演示Object Header针对SyncBlock Index的存储。在将Foobar对象创建出来后,我们先调用其GetHashCode方法,并在针对该对象的lock上下文中完成针对内存字节的输出。
var foobar = new Foobar(); foobar.GetHashCode(); lock (foobar) { BytesPrinter.PrintBytes(foobar); Debugger.Break(); } public class Foobar{}
如下所示的是程序运行后的输出结果,红色标注的正是存储SyncBlock Index的Object Header的内容。
[24]00-00-00-00-0F-00-00-08-20-BD-87-E0-FA-7F-00-00-00-00-00-00-00-00-00-00
我们按照与上面一样的方式将这4个字节转换成二进制,可以确定BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX和BIT_SBLK_IS_HASHCODE位分别为1和0,所以可以确定低26位存储的就是SyncBlock Index,对应的值位15(0b111)。
08 00 00 0F
00001000 00000000 00000000 00001111
我们在lock上下文中同样调用了Debugger的Break方法,所以程序会在这里停下来。如果此时我们将当前进程的Dump抓下来,通过执行syncblk将正在被使用的SyncBlock显式出来,唯一的那个的Index正是15。文章来源:https://www.toymoban.com/news/detail-475380.html
 文章来源地址https://www.toymoban.com/news/detail-475380.html
文章来源地址https://www.toymoban.com/news/detail-475380.html
到了这里,关于通过读取字节内容分析对象在内存中的布局的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!