Doris系列
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天和大家分享一下Doris系列之导入Kafka数据操作
#博学谷IT学习技术支持#
前言

接着上次的Doris系列继续和大家分享,上次讲了Doris 建表操作,和从Broker Load导入hdfs数据操作,今天和大家分享从Routine Load导入kafka数据操作。
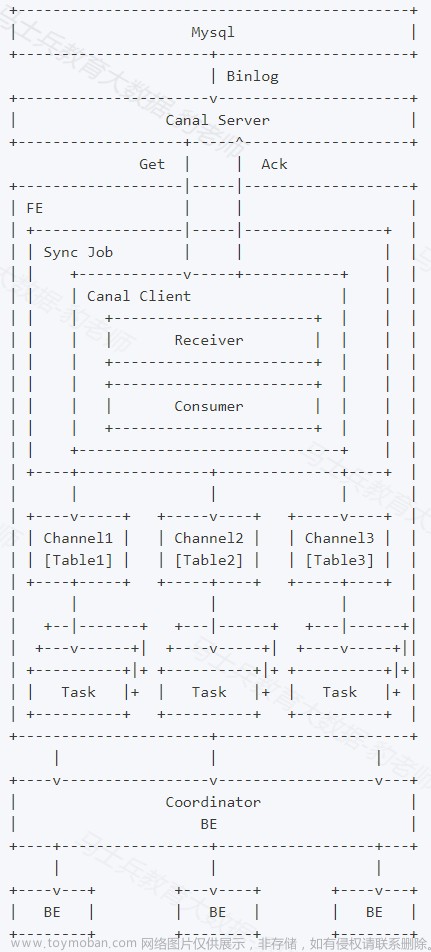
如上图,Client 向 FE 提交一个例行导入作业。
FE 通过 JobScheduler 将一个导入作业拆分成若干个 Task。每个 Task 负责导入指定的一部分数据。Task 被 TaskScheduler 分配到指定的 BE 上执行。
在 BE 上,一个 Task 被视为一个普通的导入任务,通过 Stream Load 的导入机制进行导入。导入完成后,向 FE 汇报。
FE 中的 JobScheduler 根据汇报结果,继续生成后续新的 Task,或者对失败的 Task 进行重试。
整个例行导入作业通过不断的产生新的 Task,来完成数据不间断的导入。
一、Kafka集群使用步骤

Kafka也是Doris一个非常重要的数据来源。
1.启动kafka集群环境
这里根据自己的路径启动kafka集群环境
cd /export/servers/kafka_2.12-2.4.1
nohup bin/kafka-server-start.sh config/server.properties 2>&1 &
2.创建kafka的topic主题
这里创建一个topic名字是test的kafka消息队列,设置1个partitions ,并且只备份1份数据。
bin/kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --replication-factor 1 \
--partitions 1 \
--topic test
如果Topic已经存在,则可以删除
bin/kafka-topics.sh --delete --zookeeper node01:2181 --topic test
3.往kafka中插入一批测试数据
这里简单做个小案例,插入2条数据。
bin/kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic test
{"id":1,"name":"zhangsan","age":20}
{"id":2,"name":"lisi","age":30}
二、Doris使用步骤
1.创建对应表
这里根据自己kafka生成的数据创建对应字段和格式的表格
create table student_kafka2
(
id int,
name varchar(50),
age int
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 10;
2.创建导入作业
- student_kafka2为第一步创建的表格名称
- desired_concurrent_number是并行度相关的参数
- strict_mode是否采用严格模式
- format为导入的格式,这里是json
CREATE ROUTINE LOAD test_db.kafka_job_new on student_kafka2
PROPERTIES
(
"desired_concurrent_number"="1",
"strict_mode"="false",
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list"= "node01:9092,node02:9092,node03:9092",
"kafka_topic" = "test",
"property.group.id" = "test_group_1",
"property.kafka_default_offsets" = "OFFSET_BEGINNING",
"property.enable.auto.commit" = "false"
);
select * from student_kafka2;

三、Doris常用的参数
设置删除时是否允许不分区直接删除
- SET delete_without_partition = true;
设置最大内存限制
- SET exec_mem_limit = 8589934592;
- SHOW VARIABLES LIKE “%mem_limit%”;
设置最长查询时间限制
- SET query_timeout = 600;
- SHOW VARIABLES LIKE “%query_timeout%”;
添加新的含预聚合的列
- ALTER TABLE table1 ADD COLUMN uv BIGINT SUM DEFAULT ‘0’ after pv;
Broadcast/Shuffle Join 操作,默认为Broadcast文章来源:https://www.toymoban.com/news/detail-475446.html
- select sum(table1.pv) from table1 join [broadcast] table2 where
table1.siteid = 12; - select sum(table1.pv) from table1 join [shuffle] table2 where
table1.siteid = 12;
总结
今天主要和大家分享了Doris系列之导入Kafka数据操作,如果大家实际工作中需要用到Kafka结合Doris操作,可以参考一下使用步骤。文章来源地址https://www.toymoban.com/news/detail-475446.html
到了这里,关于Doris系列之导入Kafka数据操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!