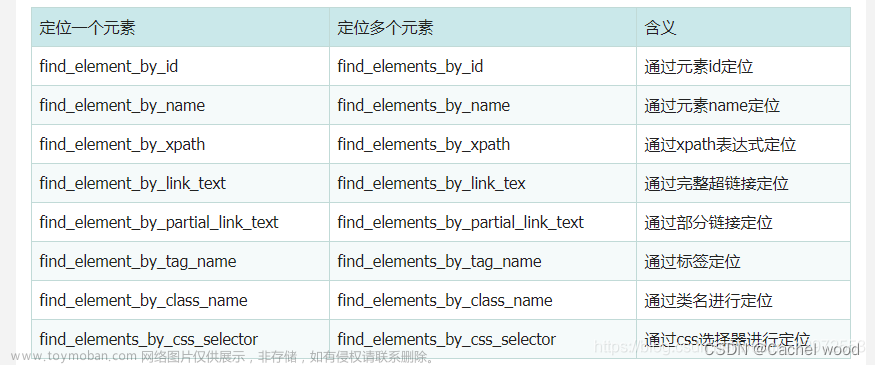
一、无可视化浏览器操作
1、导入需要的函数,固定写法,并设置相关浏览器参数
from selenium.webdriver.chrome.options import Options
浏览器设置=Options()
浏览器设置.add_argument("--headless")
浏览器设置.add_argument("--disable-gpu")2、请求的时候加上参数设置
浏览器=webdriver.Chrome(r'./chromedriver',options=浏览器设置)
目标网址=浏览器.get('https://www.XXX.com/')3、通过截图证明确实被打开了
浏览器.save_screenshot("百度.png")二、有些网站通过判断window.navigator.webdriver属性值来判断是否有爬虫行为
1、正常访问浏览器,该属性值为false

2、通过webdriver访问浏览器,该属性值为true

三、修改window.navigator.webdriver属性值
1、添加先关的参数,固定写法
浏览器设置=Options()
浏览器设置.add_argument("--disable-blink-features=AutomationControlled")
浏览器设置.add_argument(
'user-agent=Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')2、访问时添加上浏览器设置的参数
浏览器 = webdriver.Chrome('./chromedriver', options=浏览器设置)3、通过执行JS代码绕过检测机制文章来源:https://www.toymoban.com/news/detail-475481.html
with open('绕过.js') as f:
js = f.read()
浏览器.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
浏览器.get('https://www.bXXXu.com')4、此时检测该属性值为undefined文章来源地址https://www.toymoban.com/news/detail-475481.html

到了这里,关于2023爬虫学习笔记 -- selenium反爬虫操作(window.navigator.webdriver属性值)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!