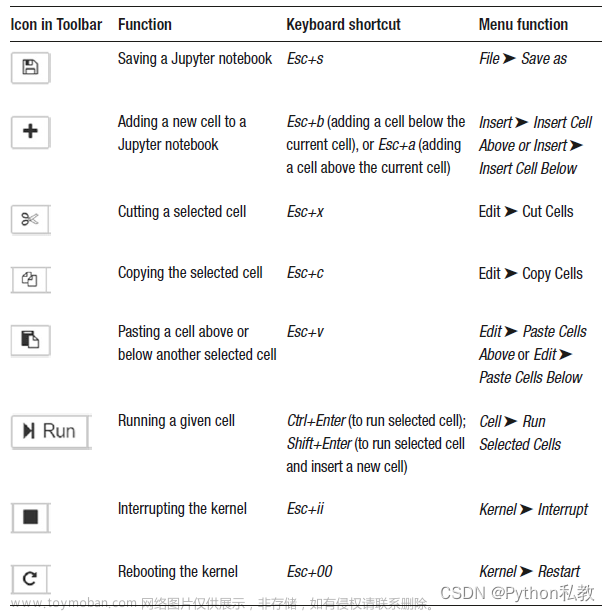
更多信息请关注WX搜索GZH:XiaoBaiGPT
Python数据分析简介
本教程将介绍如何使用Python进行大数据分析。Python是一种功能强大且易于使用的编程语言,具备丰富的数据分析库和工具。在本教程中,我们将涵盖以下主题:
-
数据分析准备工作 -
导入数据 -
数据清洗和预处理 -
数据探索与可视化 -
数据分析与建模
1. 数据分析准备工作
在开始数据分析之前,我们需要确保正确安装了所需的Python库。以下是一些常用的库:
-
Pandas:用于数据处理和分析的核心库。 -
NumPy:提供高性能的数值计算功能。 -
Matplotlib:用于数据可视化和绘图的库。 -
Seaborn:基于Matplotlib的高级数据可视化库。 -
Scikit-learn:用于机器学习和建模的库。
确保已经安装了这些库,并准备好开始数据分析。
2. 导入数据
首先,我们需要导入数据以进行分析。Python支持多种数据格式,包括CSV、Excel、JSON等。下面是导入CSV文件的示例:
import pandas as pd
# 读取CSV文件
data = pd.read_csv('data.csv')
上述代码使用pandas库中的read_csv()函数从名为data.csv的文件中读取数据。请确保将文件路径替换为您的实际文件路径。
3. 数据清洗和预处理
在数据分析之前,通常需要进行数据清洗和预处理。这包括处理缺失值、处理异常值、标准化数据等。以下是一些常见的数据清洗和预处理操作的示例:
3.1 处理缺失值
缺失值是数据中的空值或未定义值。我们可以使用pandas库来处理缺失值。以下代码演示了如何处理缺失值:
# 检查缺失值
data.isnull().sum()
# 填充缺失值
data.fillna(0, inplace=True)
上述代码中,isnull().sum()函数用于计算每列的缺失值数量。fillna()函数用于填充缺失值,这里将缺失值替换为0。根据实际情况,您可以选择其他方法来处理缺失值。
3.2 处理异常值
异常值是与其他值相比明显不同的值。我们可以使用统计学或可视化方法来检测和处理异常值。以下是一些示例代码:
# 检测异常值
import seaborn as sns
sns.boxplot(x=data['column_name'])
# 处理异常值
data = data[data['column_name'] < 100]
上述代码中,sns.boxplot()函数用
于绘制箱线图以检测异常值。然后,我们可以根据需要对异常值进行处理。在这个示例中,我们删除了大于100的异常值。
3.3 标准化数据
标准化是将数据转换为具有零均值和单位方差的标准分布。这在许多数据分析和建模技术中是很重要的。以下是标准化数据的示例:
from sklearn.preprocessing import StandardScaler
# 创建标准化器
scaler = StandardScaler()
# 标准化数据
data['column_name'] = scaler.fit_transform(data['column_name'].values.reshape(-1, 1))
上述代码中,我们使用StandardScaler()类创建一个标准化器,并使用fit_transform()函数将数据标准化。请将column_name替换为您要标准化的实际列名。
4. 数据探索与可视化
在数据分析中,数据探索和可视化是非常重要的步骤。这有助于我们了解数据的分布、关系和趋势。以下是一些常见的数据探索和可视化技巧的示例:
4.1 描述统计信息
描述统计信息提供了关于数据分布和摘要的概览。以下是描述统计信息的示例:
# 计算描述统计信息
data.describe()
上述代码中,describe()函数用于计算数据的描述统计信息,包括计数、均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。
4.2 数据可视化
数据可视化可以帮助我们更好地理解数据。以下是一些常见的数据可视化方法的示例:
import matplotlib.pyplot as plt
# 绘制直方图
plt.hist(data['column_name'])
# 绘制散点图
plt.scatter(data['column_name1'], data['column_name2'])
# 绘制箱线图
sns.boxplot(x=data['column_name'])
上述代码中,我们使用matplotlib库和seaborn库来绘制直方图、散点图和箱线图。请将column_name替换为您要绘制的实际列名。
5. 数据分析与建模
一旦我们完成了数据清洗、预处理、探索和可视化,我们可以进行数据分析和建模。以下是一些示例代码:
5.1 相关性分析
相关性分析用于确定变量之间的关系。以下是相关性分析的示例:
# 计算相关系数
correlation = data.corr()
# 可视化相关系数矩阵
sns.heatmap(correlation, annot=True, cmap='coolwarm')
上述代码中,corr()函数用于计算数据的相关系数矩阵,heatmap()函数用于可视化
相关系数矩阵。
5.2 建立模型
使用scikit-learn库,我们可以建立各种机器学习模型。以下是一个线性回归模型的示例:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 准备特征和目标变量
X = data[['feature1', 'feature2']]
y = data['target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 拟合模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
上述代码中,我们使用LinearRegression()类创建一个线性回归模型,并使用fit()函数拟合模型。然后,我们使用模型对测试集进行预测。
这只是大数据分析的一个简单示例,实际应用中可能涉及更复杂的数据分析和建模技术。但是,这个教程希望能够帮助您入门并理解使用Python进行大数据分析的基本概念和操作。文章来源:https://www.toymoban.com/news/detail-476000.html
本文由 mdnice 多平台发布文章来源地址https://www.toymoban.com/news/detail-476000.html
到了这里,关于大数据教程【05.01】--Python 数据分析简介的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!