一、前言
1 微服务架构简介
微服务架构是一种软件设计模式,它将单个应用程序拆分成一组更小、更独立的服务。每个服务在自己的进程中运行,并使用轻量级通信机制进行通信。由于每个服务都是独立的,因此可以独立部署、扩展和更新,从而使开发和运维更加容易。
2 Kubernetes 简介
Kubernetes 是一个开源的容器编排和管理系统,它提供了高度可靠的基础设施,使得应用程序可以在多个节点上运行,从而提高可用性和性能。Kubernetes 还包含一组核心概念,例如 Pod、服务、部署和副本集等,它们可以帮助您更好地管理和编排容器化应用程序。
3 Kubernetes 与微服务
Kubernetes 与微服务是相互关联的。它提供了高效、可扩展的容器管理工具和服务,让微服务的部署、升级和扩容变得非常简单。
二、准备工作
1 安装 Kubernetes
1.1 搭建 Kubernetes 集群
要部署 Kubernetes 集群需要至少三个计算机实例。其中一个实例(即 Master 节点)将充当集群的控制中心,调度和管理容器的生命周期,另外两个实例将作为 Worker 节点负责运行和管理容器实例。
搭建 Kubernetes 集群有很多方式这里将使用 kubeadm 工具完成。请先确保每个计算机实例上都已安装了 Docker 引擎和 kubeadm 工具。
在 Master 节点上运行以下命令,初始化 Kubernetes 集群:
$ sudo kubeadm init --pod-network-cidr=10.244.0.0/16
注:pod-network-cidr 参数(10.244.0.0/16)用于设置 Calico 网络插件的 IP 地址范围。必须指定此参数才能成功安装 Calico 网络插件。
初始化成功后,应该能够看到类似下面的输出信息:
Your Kubernetes control-plane has initialized successfully!
根据输出信息在 Master 节点上运行以下命令,安装网络插件(这里我们将使用 Calico 网络插件):
$ kubectl apply -f https://docs.projectcalico.org/v3.16/manifests/calico.yaml
运行以下命令查看节点状态:
$ kubectl get nodes
应该能够看到类似下面的输出信息:
NAME STATUS AGE VERSION
k8s-master Ready 3m36s v1.19.0
k8s-worker1 Ready 12s v1.19.0
k8s-worker2 Ready 3s v1.19.0
至此已成功地搭建了 Kubernetes 集群!
1.2 安装 kubectl 工具
kubectl 是 Kubernetes 的命令行工具。它可用于与 Kubernetes 集群进行交互,例如通过 kubectl 创建、更新和删除 Kubernetes 对象,以及查看集群状态和日志等。
在每个节点上安装 kubectl 工具:
$ sudo apt-get update && sudo apt-get install -y apt-transport-https
$ curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
$ cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
$ sudo apt-get update
$ sudo apt-get install -y kubectl
2 准备 Docker 镜像
2.1 编写 Dockerfile 文件
在使用 Kubernetes 部署应用程序之前需要将应用程序打包成一个 Docker 镜像。下面是一个简单的 Node.js 应用程序的 Dockerfile 文件:
FROM node:12
WORKDIR /app
COPY package*.json ./
RUN npm install
COPY . .
EXPOSE 3000
CMD ["npm", "start"]
这个 Dockerfile 文件指定了 Node.js 的 12.x 版本作为基础镜像,并将工作目录设置为 /app。然后,它复制了 package.json 和 package-lock.json 文件到 /app 目录中,并运行 npm install 命令安装所需的 Node.js 模块。接下来它复制了所有项目文件到 Docker 镜像中,并暴露端口号 3000。最后它在容器启动时运行 npm start 命令来启动应用程序。
2.2 构建 Docker 镜像
在 Dockerfile 文件所在的目录中,使用以下命令构建 Docker 镜像:
$ docker build -t mynodeapp:1.0 .
这个命令将使用当前目录下的 Dockerfile 文件,并将构建出的 Docker 镜像标记为 mynodeapp:1.0。
2.3 将 Docker 镜像上传到容器仓库
要在 Kubernetes 中部署应用程序需要将 Docker 镜像上传到容器仓库中。下面是一个例子,展示如何将 Docker 镜像上传到 Docker Hub:
- 先行创建一个 Docker Hub 账户。
- 在本地终端中登录到 Docker Hub:
$ docker login
- 将先前构建的 Docker 镜像标记并上传到 Docker Hub:
$ docker tag mynodeapp:1.0 myhubuser/mynodeapp:1.0
$ docker push myhubuser/mynodeapp:1.0
现在,我们已经准备好在 Kubernetes 中部署我们的应用程序了!
三、部署微服务
在 Kubernetes 中部署和管理微服务非常简单。以下是如何使用 Deployment、Service 和 Ingress 对象来部署和管理微服务的详细步骤。
1 使用 Deployment 部署微服务
1.1 创建 Deployment 对象
Deployment 对象是 Kubernetes 中一种用于自动部署和更新应用程序的对象。它会自动创建和管理 Pod 对象,并根据应用程序的副本数和更新策略,自动扩展或缩小每个 Pod 副本的数量。
要创建一个 Deployment 对象,您需要创建一个简单的 YAML 文件例如:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mynodeapp-deployment
labels:
app: mynodeapp
spec:
replicas: 3
selector:
matchLabels:
app: mynodeapp
template:
metadata:
labels:
app: mynodeapp
spec:
containers:
- name: mynodeapp
image: myhubusername/mynodeapp:1.0
ports:
- containerPort: 3000
上述 YAML 文件定义了一个名为 mynodeapp-deployment 的 Deployment 对象。这个 Deployment 会创建 3 个 Pod 副本,每个 Pod 副本包含一个名为 mynodeapp 的容器。每个容器都会使用 Docker Hub 中的 myhubusername/mynodeapp:1.0 镜像并在容器内打开 3000 端口。
要使用这个 YAML 文件创建 Deployment 对象,请在 Kubernetes 集群中运行以下命令:
$ kubectl apply -f mynodeapp-deployment.yaml
如果一切顺利应该能够看到类似下面的输出信息:
deployment.apps/mynodeapp-deployment created
1.2 查看 Deployment 状态
要查看部署的状态,请运行以下命令:
$ kubectl get deployments
您应该能够看到类似下面的输出信息:
NAME READY UP-TO-DATE AVAILABLE AGE
mynodeapp-deployment 3/3 3 3 1m
此命令将显示您创建的 mynodeapp-deployment Deployment 中的 Pod 副本的状态。
1.3 手动扩展/缩小副本数
要手动扩展/缩小 Deployment 中的 Pod 副本数可以使用以下命令:
$ kubectl scale deployment mynodeapp-deployment --replicas=5
上述命令将把 mynodeapp-deployment Deployment 中的 Pod 副本数扩展到 5,您可以将 5 更改为您需要的任何数字。
每当您需要缩小 Pod 副本数时,您也可以使用类似的命令,如:
$ kubectl scale deployment mynodeapp-deployment --replicas=3
以上命令将把 mynodeapp-deployment Deployment 中的 Pod 副本数缩小到 3。请注意此操作可能会导致您的部署中断因此请小心使用。
2 使用 Service 暴露微服务
2.1 创建 Service 对象
Service 对象是 Kubernetes 中用于公开和暴露微服务的对象。它使用标签选择器来选择相应的 Pod,并创建一个稳定的 IP 地址和 DNS 名称,以便其他微服务可以通过它来访问您的微服务。
要创建一个 Service 对象,请创建一个新的 YAML 文件例如:
apiVersion: v1
kind: Service
metadata:
name: mynodeapp-service
labels:
app: mynodeapp
spec:
type: LoadBalancer
selector:
app: mynodeapp
ports:
- port: 80
targetPort: 3000
上述 YAML 文件定义了一个名为 mynodeapp-service 的 Service 对象。这个 Service 对象使用标签选择器来选择名称为 mynodeapp 的 Pod,并创建了一个稳定的 80 端口。
要使用这个 YAML 文件创建 Service 对象,请在 Kubernetes 集群中运行以下命令:
$ kubectl apply -f mynodeapp-service.yaml
如果一切顺利应该能够看到类似下面的输出信息:
service/mynodeapp-service created
2.2 通过 Service 访问微服务
要访问微服务可以使用在 Service 中创建的 IP 地址和端口号。要查找 Service 的 IP 地址,请运行以下命令:
$ kubectl get services
您应该能够看到类似下面的输出信息:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 8h
mynodeapp-service LoadBalancer 10.105.13.218 35.227.28.137 80:31524/TCP 1m
此命令将显示您创建的 mynodeapp-service Service 的 IP 地址和端口号。在上面的示例中,IP 地址为 10.105.13.218,端口号为 80。
现在可以使用在 Service 中创建的 IP 地址和端口号,访问您的微服务。例如,如果您的微服务是一个 Node.js Web 应用程序,您可以使用以下命令在 Web 浏览器中访问它:
$ xdg-open http://10.105.13.218
3 使用 Ingress 管理多个微服务
如果你正在运行多个微服务,您可以使用 Ingress 对象管理它们。Ingress 对象是 Kubernetes 中的一种对象,它允许您通过创建和配置 Ingress 控制器,将多个微服务公开到同一 IP 地址和端口上。
3.1 安装 Ingress 控制器
要使用 Ingress 对象管理多个微服务,请先安装 Ingress 控制器。这里我们将使用官方提供的 Nginx Ingress 控制器。
要安装 Nginx Ingress 控制器,请在 Kubernetes 集群上运行以下命令:
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.41.2/deploy/static/provider/cloud/deploy.yaml
3.2 创建 Ingress 对象
要创建一个 Ingress 对象,您需要创建一个新的 YAML 文件,例如:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: my-ingress
spec:
rules:
- http:
paths:
- path: /mynodeapp
backend:
serviceName: mynodeapp-service
servicePort: 80
- path: /myredisapp
backend:
serviceName: myredisapp-service
servicePort: 80
上述 YAML 文件定义了一个名为 my-ingress 的 Ingress 对象。这个 Ingress 对象定义了两个微服务的路径和后端:
- 路径为 /mynodeapp,使用 mynodeapp-service 作为后端。
- 路径为 /myredisapp,使用 myredisapp-service 作为后端。
与 Service 对象类似,您可以根据需要创建一个或多个 Ingress 对象来管理多个微服务。
要使用这个 YAML 文件创建 Ingress 对象,请在 Kubernetes 集群中运行以下命令:
$ kubectl apply -f my-ingress.yaml
如果一切顺利,您应该能够看到类似下面的输出信息:
ingress.extensions/my-ingress created
现在,您可以在 Web 浏览器中使用 my-node.com/mynodeapp 和 my-node.com/myredisapp 访问两个微服务。请注意,您需要在 DNS 服务器或本地 hosts 文件中将 my-node.com 映射到 Ingress 控制器的 IP 地址。
四、微服务的监控与日志
监控和日志管理是微服务架构中必不可少的两个方面。在 Kubernetes 集群中,我们可以使用不同的工具来完成这两个任务。本文将介绍如何使用 Prometheus 和 Grafana 监控 Kubernetes 中的微服务,并使用 ELK Stack 进行微服务的日志管理。
1 Kubernetes 的监控
Kubernetes 提供了一些内置的监控和诊断工具,例如 kubectl top 命令可对 Kubernetes 中的 Pod 和节点进行监控。但是,如果您需要进行更细粒度的监控,并且需要可视化和警报功能,则可以使用第三方工具,例如 Prometheus 和 Grafana。
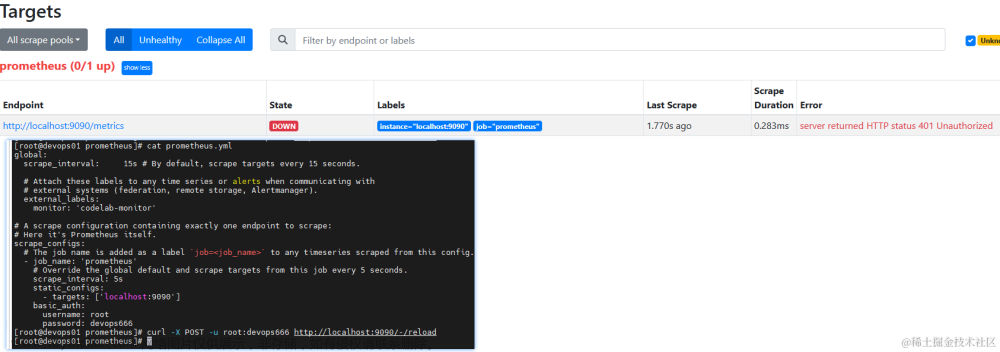
1.1 Prometheus 监控
Prometheus 是一种流行的开源监控工具,它可以收集多个数据源的指标,并允许我们与 Grafana 等工具一起使用,以实现更好的可视化和警报功能。
要在 Kubernetes 中使用 Prometheus,我们可以使用一个叫做 Prometheus Operator 的工具来管理 Prometheus 实例并配置规则。
以下是如何使用 Prometheus Operator 在 Kubernetes 中设置 Prometheus 监控的详细步骤:
步骤 1. 安装 Prometheus Operator CRD
首先需要通过运行以下命令来安装 Prometheus Operator CRD:
$ kubectl apply -f https://raw.githubusercontent.com/coreos/prometheus-operator/master/bundle.yaml
步骤 2. 安装 Prometheus Operator
然后需要安装 Prometheus Operator。有两种方法可以安装 Prometheus Operator:使用 Operator 部署程序或者使用 Helm Chart。
1 使用 Operator 部署程序
要使用 Operator 部署程序安装 Prometheus Operator,请按照以下步骤操作:
- 下载 kustomize 工具:
$ curl -Lo kustomize https://github.com/kubernetes-sigs/kustomize/releases/download/kustomize%2Fv3.5.4/kustomize_v3.5.4_darwin_amd64
$ chmod +x kustomize
$ sudo mv kustomize /usr/local/bin/
- 下载 Prometheus Operator:
$ git clone https://github.com/coreos/kube-prometheus.git
- 部署 Prometheus Operator:
$ cd kube-prometheus
$ kustomize build manifests/prometheus-operator | kubectl apply -f -
完成后应该能够看到一个名为 prometheus-operator 的 Deployment,它正在运行 Prometheus Operator。
2 使用 Helm Chart
要使用 Helm Chart 安装 Prometheus Operator,请按照以下步骤操作:
- 启用 Helm 仓库:
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
- 安装 Prometheus Operator:
$ helm install prometheus-operator prometheus-community/kube-prometheus-stack
完成后应该能够看到一个名为 prometheus-operator 的 Deployment,它正在运行 Prometheus Operator。
步骤 3. 安装 Prometheus 实例
有了 Prometheus Operator 后,我们就可以使用 Prometheus CRD 并安装一个新的 Prometheus 实例,以便开始监控 Kubernetes。
以下是如何安装 Prometheus 实例的示例 YAML 文件(prometheus.yaml):
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: my-prometheus
spec:
replicas: 1
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
release: prometheus-operator
ruleSelector:
matchLabels:
prometheus: my-prometheus
alerting:
alertmanagers:
- namespace: monitoring
name: alertmanager-main
port: web
image:
repository: prom/prometheus
tag: v2.25.0
sha: 70eaa1c84f09a57f7430afeb229f15c28efcd1cb09c74bb2318917bde3fcb3eb
retention:
size: 1Gi
period: 10d
上述 YAML 文件创建了一个名为 my-prometheus 的 Prometheus 实例,并包括以下各项:
- 1 个副本。
- 使用 prometheus 服务账户。
- 使用 Kubernetes ServiceMonitors 对象进行选择。
- 使用 PrometheusRule 对象进行选择,并配置警报规则。
- 配置警报管理器,可与 Alertmanager 一起使用。
- Prometheus 镜像版本为 v2.25.0,并已验证 SHA 校验和。
- 配置数据保留策略。
要使用以上 YAML 文件创建 Prometheus 实例,请使用以下命令:
$ kubectl apply -f prometheus.yaml
完成后应该能够看到一个名为 my-prometheus 的 StatefulSet 和 Service 对象,它们正用于运行 Prometheus 实例。
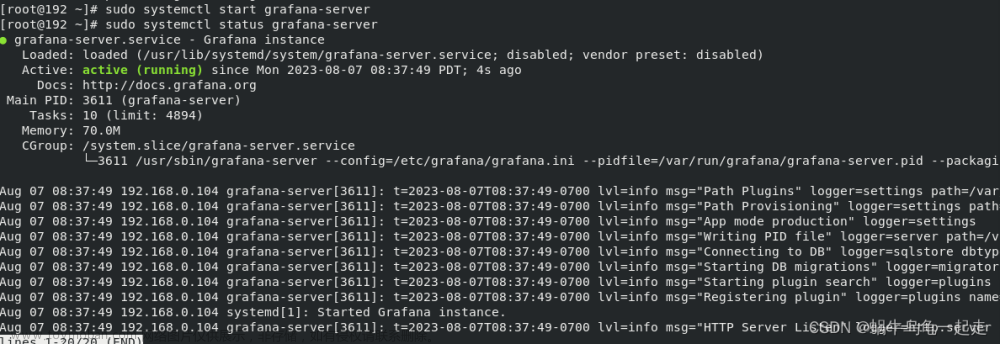
1.2 Grafana 可视化
Grafana 是一种流行的开源可视化工具,它可以与 Prometheus 及其他数据源配合使用,并提供丰富的数据可视化和警报功能。
要在 Kubernetes 中使用 Grafana,我们可以使用一个叫做 Grafana Operator 的工具来管理 Grafana 实例,并配置相应的数据源和面板。
以下是如何使用 Grafana Operator 在 Kubernetes 中设置 Grafana 可视化的详细步骤:
步骤 1. 安装 Grafana Operator
要安装 Grafana Operator 需要首先安装 Operator 部署程序,然后再使用 Operator 创建新的 Grafana 实例。
以下是如何使用 Operator 部署程序安装 Grafana Operator 的步骤:
- 下载 kube-prometheus-stack:
$ git clone https://github.com/prometheus-operator/kube-prometheus.git
- 部署 Grafana Operator:
$ kubectl apply -f kube-prometheus/manifests/grafana-operator
完成后应该能够看到一个名为 grafana-operator 的 Deployment。
步骤 2. 安装 Grafana 实例
有了 Grafana Operator 后,我们就可以使用新的 Grafana CRD 并安装一个新的 Grafana 实例,以便开始可视化 Prometheus 的数据。
以下是如何安装 Grafana 实例的示例 YAML 文件(grafana.yaml):
apiVersion: integreatly.org/v1alpha1
kind: Grafana
metadata:
name: my-grafana
spec:
plugins:
- name: grafana-clock-panel
version: 1.0.3
- name: grafana-piechart-panel
version: 1.4.0
config:
auth.anonymous:
enabled: true
org_role: Admin
dashboardLabelSelector: {}
上述 YAML 文件创建了一个名为 my-grafana 的 Grafana 实例,并包括以下各项:
- 配置了两个插件:grafana-clock-panel 和 grafana-piechart-panel。
- 可以启用匿名访问,访客可以使用 Admin 权限登录。
- 没有选择特定的面板。
要使用以上 YAML 文件创建 Grafana 实例,请使用以下命令:
$ kubectl apply -f grafana.yaml
完成后,您应该能够看到一个名为 my-grafana 的 Deployment 和 Service,它们正用于运行 Grafana 实例。
步骤 3. 创建数据源和面板
有了 Grafana 实例后就可以开始创建数据源和面板,以便可视化 Prometheus 中收集的数据。
以下是如何在 Grafana 中创建 Prometheus 数据源的详细步骤:
-
登录 Grafana 界面。默认情况下,您可以通过浏览器访问 Grafana 在 Kubernetes 中暴露的服务(如 http://:3000)。
-
在 Grafana 中创建一个数据源。单击左侧菜单中的 “Configuration” 选项卡,在下拉菜单中选择 “Data Sources” 。
-
点击 “Add data source” 创建一个新的数据源。在弹出的数据源配置界面中,选择 Prometheus,并输入正确的 Prometheus URL (如 http://:9090)。
-
配置完毕后,单击 “Save & Test” 按钮验证 Prometheus 数据源是否连接正常。
现在,我们已经成功配置了 Prometheus 和 Grafana,如果您需要进一步了解如何使用 Grafana 来可视化 Prometheus 中的监控数据,可以考虑参考 Grafana 的官方文档和相关教程。
2 微服务的日志管理
日志管理是微服务架构中另一个关键方面,通过合理的日志管理,我们可以更好地理解微服务各个组件之间的通信、出现的失败或故障等。在 Kubernetes 中,我们可以使用 ELK Stack 来进行微服务的日志管理。
2.1 ELK Stack
ELK Stack 是指 Elasticsearch、Logstash 和 Kibana 三个开源软件的组合,用于实现日志管理和分析。以下是每个组件的简单介绍:
-
Elasticsearch:一种基于 Lucene 的全文搜索引
擎,用于存储和搜索各种类型的数据,包括日志数据。 -
Logstash:一个用于收集、分析、过滤和转换日志数据
的开源工具,支持多种输入和输出格式,例如:
syslog、Beats、TCP/UDP、Kafka、Elasticsearch 等。 -
Kibana:一个用于可视化和分析 Elasticsearch 数据的可
视化工具,提供各种仪表板和图表。
2.2 在 Kubernetes 中使用 ELK Stack
以下是如何在 Kubernetes 中使用 ELK Stack 进行微服务的日志管理的详细步骤:
步骤 1. 安装 Elasticsearch
要在 Kubernetes 中使用 Elasticsearch,我们可以使用官方提供的 Elasticsearch Operator。
以下是如何使用 Elasticsearch Operator 安装 Elasticsearch 的详细步骤:
- 下载 Elasticsearch Operator.yaml 文件:
$ curl https://download.elastic.co/downloads/eck/1.0.1/all-in-one.yaml -O
- 执行以下命令开始安装 Elasticsearch Operator:
$ kubectl apply -f all-in-one.yaml
- 创建一个名为 elasticsearch 的 Elasticsearch 资源对象,以便开始使用 Elasticsearch:
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: elasticsearch
spec:
version: 7.14.0
nodeSets:
- count: 1
name: default
podTemplate:
spec:
containers:
- name: elasticsearch
env:
- name: "cluster.name"
value: "es-cluster"
- name: "node.name"
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: "discovery.seed_hosts"
value: "elasticsearch-discovery.elasticsearch.svc.cluster.local"
- name: "cluster.initial_master_nodes"
value: "elasticsearch-0"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
image: "docker.elastic.co/elasticsearch/elasticsearch:7.14.0"
volumeMounts:
- name: elasticsearch-data
mountPath: /usr/share/elasticsearch/data
volumes:
- name: elasticsearch-data
persistentVolumeClaim:
claimName: elasticsearch-data
上述 YAML 文件创建了一个名为 elasticsearch 的 Elasticsearch 资源,并包括以下各项:
- 配置了 Elasticsearch 版本为 7.14.0。
- 配置每个节点的数量为 1 个。
- 配置节点名称、群集名称和群集的主节点。
- 配置每个 Elasticsearch 节点的 JVM 内存大小为 512 MB。
要使用以上 YAM 。
L 文件创建 Elasticsearch 实例,请使用以下命令:
$ kubectl apply -f elasticsearch.yaml
完成后应该能够看到一个名为 elasticsearch 的 StatefulSet 和 Service,它们正用于运行 Elasticsearch 实例。
步骤 2. 安装 Logstash
要在 Kubernetes 中使用 Logstash,我们可以使用官方提供的 Logstash Docker 映像。
以下是如何使用 Logstash Docker 映像在 Kubernetes 中安装 Logstash 的详细步骤:
- 下载 Logstash 配置文件(logstash.conf):
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
}
}
- 创建一个名为 logstash 的 ConfigMap,并将 logstash.conf 文件添加到其中:
$ kubectl create configmap logstash-config --from-file=logstash.conf
- 创建一个名为 logstash 的 Deployment,以便开始使用 Logstash:
apiVersion: apps/v1
kind: Deployment
metadata:
name: logstash
spec:
selector:
matchLabels:
app: logstash
replicas: 1
template:
metadata:
labels:
app: logstash
spec:
containers:
- name: logstash
image: docker.elastic.co/logstash/logstash:7.14.0
resources:
limits:
memory: 512Mi
volumeMounts:
- name: logstash-config
mountPath: /usr/share/logstash/pipeline/
- name: logstash-input
mountPath: /usr/share/logstash/input/
- name: logstash-logs
mountPath: /usr/share/logstash/logs/
volumes:
- name: logstash-config
configMap:
name: logstash-config
- name: logstash-input
emptyDir: {}
- name: logstash-logs
emptyDir: {}
上述 YAML 文件创建了一个名为 logstash 的 Deployment,并包括以下各项:
- 配置了 Logstash 处理 Beats 输入和 Elasticsearch 输出。
- 配置了 Logstash 版本为 7.14.0。
- 配置了每个 Pod 的 JVM 内存大小为 512 MB。
要使用以上 YAML 文件创建 Logstash 实例,请使用以下命令:
$ kubectl apply -f logstash.yaml
完成后应该能够看到一个名为 logstash 的 Deployment,它正在运行 Logstash 实例。
步骤 3. 安装 Kibana
要在 Kubernetes 中使用 Kibana 可以使用官方提供的 Kibana Docker 映像。
以下是如何使用 Kibana Docker 映像在 Kubernetes 中安装 Kibana 的详细步骤:
- 创建一个名为 kibana 的 Deployment,以便开始使用 Kibana:
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
spec:
selector:
matchLabels:
app: kibana
replicas: 1
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.14.0
ports:
- containerPort: 5601
readinessProbe:
httpGet:
path: /api/status
port: 5601
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
livenessProbe:
httpGet:
path: /api/status
port: 5601
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
env:
- name: "ELASTICSEARCH_HOSTS"
value: "http://elasticsearch:9200"
上述 YAML 文件创建了一个名为 kibana 的 Deployment,并包括以下各项:
- 配置了 Kibana 版本为 7.14.0。
- 配置了一个名为 kibana 的容器,该容器运行 Kibana。
- 配置了 Kibana 连接到 Elasticsearch 的 URL。
- 配置了 Kibana 容器的 readinessProbe 和 livenessProbe。
要使用以上 YAML 文件创建 Kibana 实例,请使用以下命令:
$ kubectl apply -f kibana.yaml
完成后应该能够看到一个名为 kibana 的 Deployment,它正在运行 Kibana 实例。
步骤 4. 在 Kibana 中查看日志
现在我们已经成功地在 Kubernetes 中安装了 Elasticsearch、Logstash 和 Kibana,接下来我们可以使用 Kibana 查看微服务的日志了。以下是如何在 Kibana 中查看日志的详细步骤:
-
登录 Kibana 界面。默认情况下,您可以通过浏览器访问 Kibana 在 Kubernetes 中暴露的服务(如 http://:5601)。
-
单击左侧菜单中的 “Discover” 选项卡。该选项卡可让您查看 Logstash 收集的日志。
-
选择 “Create index pattern” 创建一个新的索引模式。在下拉菜单中选择 Logstash 中的索引。根据您的需要设置索引模式的名称,并按需调整其他配置选项。
-
索引模式设置完毕后,您应该能够在 Discover 选项卡中看到 Logstash 收集的日志。
至此,我们已经成功地在 Kubernetes 中安装和使用了 ELK Stack,实现了微服务的日志管理和分析。如果您需要针对特定的业务场景进行更深入的日志分析,可以考虑使用更多的 ELK Stack 组件或扩展工具。
五、微服务的自动扩展
在面对高并发、大流量的业务场景时,我们往往需要对微服务进行自动扩展,以保证系统的稳定性、可靠性和可用性。在 Kubernetes 中,我们可以使用自动扩展组件(如 Horizontal Pod Autoscaler 和 Cluster Autoscaler)来实现微服务的自动扩展。本文将对 Kubernetes 中应用水平扩展和集群节点自动扩展做详细介绍。
1 应用水平扩展
应用水平扩展是指根据应用的负载情况,自动添加或删除 Pod 实例。当应用的负载增加时,自动添加 Pod 实例以分担流量,当负载下降时,自动删除 Pod 实例以释放资源。
1.1 应用负载指标监控
应用负载指标监控是应用水平扩展的前提。在 Kubernetes 中,我们可以使用 Prometheus 和 Grafana 等工具来监控应用的负载指标,如 CPU 使用率、内存使用率、请求吞吐量、错误率等。
以下是一个示例应用的指标监控配置:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: my-app
spec:
selector:
app: my-app
endpoints:
- port: web
interval: 10s
path: /metrics
上述配置创建了一个名为 my-app 的 ServiceMonitor,它会针对 Label 为 app=my-app 的应用 Pod 监控 /metrics 端点(即应用的指标信息)。并且每 10 秒刷新一次监控数据。
1.2 创建 Horizontal Pod Autoscaler 对象
创建 Horizontal Pod Autoscaler 对象是应用水平扩展的关键。它可以根据应用的负载情况自动添加或删除 Pod 实例。
以下是一个示例的 Horizontal Pod Autoscaler 配置文件:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
上述配置创建了一个名为 my-app-hpa 的 Horizontal Pod Autoscaler,它会自动扩展应用 my-app 的 Pod 实例数以满足 CPU 利用率 50% 的条件。当 CPU 利用率高于目标值时,它就会自动添加 Pod 实例,当低于目标值时,它就会自动删除 Pod 实例。同时,它还设置了最小可用 Pod 数为 2,最大可用 Pod 数为 10。
2 集群节点的自动扩展
集群节点的自动扩展是指根据资源利用率和节点负载情况,自动添加或删除集群节点。当节点负载高或资源利用率高时,自动添加节点以满足负载和资源的需求,当负载和资源需求降低时,自动删除节点以节省资源和成本。
2.1 使用 Cluster Autoscaler 进行节点扩展
在 Kubernetes 中,我们可以使用 Cluster Autoscaler 来自动扩展集群节点。它可以根据节点上 Pod 的资源需求和其他因素,自动添加、删除集群节点。
以下是一个示例 Cluster Autoscaler 的部署文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: cluster-autoscaler
spec:
replicas: 1
selector:
matchLabels:
app: cluster-autoscaler
template:
metadata:
labels:
app: cluster-autoscaler
spec:
serviceAccountName: cluster-autoscaler
containers:
- image: k8s.gcr.io/autoscaling/cluster-autoscaler:v1.22.2
name: cluster-autoscaler
command:
- ./cluster-autoscaler
- --cloud-provider=aws
- --namespace=default
- --node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/{{ .NodePoolName }}
- --balance-similar-node-groups
- --skip-nodes-with-system-pods=false
tolerations:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
上述部署文件创建了一个名为 cluster-autoscaler 的 Deployment,它会自动扩展集群节点并确保 Pod 能够正确地调度和运行。需要针对不同云厂商或基础设施提供相应的参数,如上例中使用 --cloud-provider=aws 表明是在 AWS 云上运行。根据不同的部署环境,您需要进行相应的参数配置。
六、微服务的高可用保证
在微服务架构中,保证服务的高可用性是至关重要的。本文将介绍微服务中节点的健康检查以及节点故障自动处理方案。
1 节点的健康检查
节点的健康检查是指通过特定的检查方式,判断该节点的应用是否正常运行。如果节点的应用由于某些原因发生异常,就需要将该节点从负载均衡中剔除,避免影响到系统整体的稳定性和可靠性。常见的节点健康检查有两种方式:Liveness Probe 和 Readiness Probe。
1.1 使用 Liveness Probe 进行节点健康检查
Liveness Probe 是指 Kubernetes 通过定期向容器进程发送 HTTP 请求、TCP 检查等方式,检查容器进程是否存活。如果检查失败,则 Kubernetes 将自动重启该容器。
以下是一个示例的 Deployment 文件,该文件配置了一个 Liveness Probe:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: my-image:v1
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /healthz
port: 80
initialDelaySeconds: 5
periodSeconds: 5
上述部署文件中,Liveness Probe 处理的路径为 /healthz,端口为 80。并且设置了容器启动 5 秒后进行第一次检查,之后每 5 秒检查一次。
1.2 使用 Readiness Probe 进行节点就绪状态检查
Readiness Probe 是指 Kubernetes 在容器启动后,通过向容器进程发送 HTTP 请求、TCP 检查等方式,检查容器是否已经可用。如果检查失败,则 Kubernetes 将不会将该容器加入负载均衡器的后端。
以下是一个示例的 Deployment 文件,该文件配置了一个 Readiness Probe:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: my-image:v1
ports:
- containerPort: 80
readinessProbe:
httpGet:
path: /healthz
port: 80
initialDelaySeconds: 10
periodSeconds: 5
上述部署文件中,Readiness Probe 处理的路径为 /healthz,端口为 80。并且设置了容器启动 10 秒后进行第一次检查,之后每 5 秒检查一次。
2 节点故障自动处理
节点故障自动处理是指 Kubernetes 在检测到某个节点或 Pod 出现故障时,自动将该节点或 Pod 从负载均衡中剔除,并尝试使用其他节点或 Pod 来提供服务。常见的节点故障自动处理方式有两种方式:使用 Kubernetes 自带的故障转移机制和使用 Helm 的 Chart 进行微服务的快速恢复。
2.1 使用 Kubernetes 自带的故障转移机制
在 Kubernetes 中,使用 ReplicationController 或 Deployment 来管理 Pod 时,会自动进行故障转移,使得系统可以自动补偿故障节点的宕机,确保服务的高可用性。
例如,假设我们部署了一个名为 my-app 的 Deployment,并设置了副本数为 3:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: my-image:v1
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /healthz
port: 80
initialDelaySeconds: 5
periodSeconds: 5
readinessProbe:
httpGet:
path: /healthz
port: 80
initialDelaySeconds: 10
periodSeconds: 5
如果其中的一个 Pod 因为某些原因无法正常工作,Kubernetes 会自动将该 Pod 删除,并自动创建一个新的 Pod 以确保副本数符合期望。
2.2 使用 Helm 的 Chart 进行微服务的快速恢复
当微服务出现故障时,我们需要快速恢复该服务,使得业务能够正常运行。在 Kubernetes 中,我们可以使用 Helm 的 Chart 来实现快速的微服务恢复。
例如,我们可以使用以下命令创建一个基于 Nginx 的 Helm Chart:
$ helm create my-nginx
然后,在 Chart.yaml 文件中添加依赖信息:
apiVersion: v2
name: my-nginx
description: A Helm chart for Kubernetes
version: 0.1.0
dependencies:
- name: nginx
version: 1.0.0
repository: https://example.com/charts
最后,使用以下命令安装该 Chart:
$ helm install my-nginx ./my-nginx
当微服务出现故障时可以使用以下命令将其删除:
$ helm delete my-nginx
然后再重新部署该服务:文章来源:https://www.toymoban.com/news/detail-476039.html
$ helm install my-nginx ./my-nginx
以上就是微服务高可用保证方面的内容,希望能对您理解 Kubernetes 中的高可用性能力有所帮助。文章来源地址https://www.toymoban.com/news/detail-476039.html
到了这里,关于搭建微服务架构:Kubernetes Prometheus ELK Stack的组合的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![【图文详解】Docker搭建 ELK Stack (elk) [使用es-logstash-filebeat-kibana]](https://imgs.yssmx.com/Uploads/2024/01/405080-1.png)

![[ELK] ELK+Filebeat变成ELK stack](https://imgs.yssmx.com/Uploads/2024/01/807924-1.png)