前言
本项目旨在开发一套完整高效的图像搜索引擎,为用户提供更加便捷的图片搜索体验。为了实现这一目标,我们采用了 CBIR(Content-based image retrieval)技术,这是目前主流的图像搜索方法之一。CBIR 技术基于图像内容的相似性来检索相似的图像,相比于传统的图像搜索方法,CBIR 技术具有更高的准确性和可靠性。
在项目中,我们基于 OpenCV 图像处理库实现了一个高效的图像搜索引擎。OpenCV 是一个广泛使用的开源计算机视觉库,提供了丰富的图像处理函数和算法,具有高效、稳定的特点。我们的搜索引擎利用 OpenCV 的图像处理功能实现了图像的特征提取、匹配和实际检测三个部分,从而有效地提高了图像搜索的精度和效率。
总之,本项目提供了一套完整的图像搜索引擎解决方案,采用 CBIR 技术、OpenCV 图像处理库和构图空间特征评价指标等技术手段,旨在提高图像搜索的精度和效率,为用户提供更加优质的图像搜索服务。
总体设计
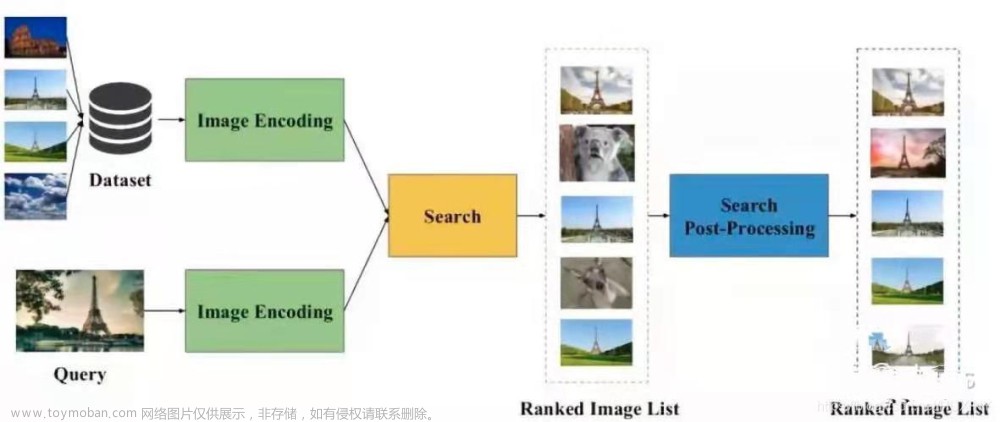
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。

系统流程图
系统流程如图所示。

运行环境
需要 Python 3.6 及以上配置,在 Windows 环境下推荐下载 Anaconda 完成 Python 所需的配置,下载地址:https://www.anaconda.com/。
Numpy:科学计算和矩阵运算工具,OpenCV 引用 Numpy 模块,安装 OpenCV 之前必须安装 Numpy 库。Numpy 下载地址: https://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy
OpenCV:Intel 开源计算机视觉库。由一系列 C 函数和少量 C++类构成,实现图像处理。和计算机视觉方面的通用算法。OpenCV 下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv
模块实现
本项目包括 5 个模块:数据预处理、定义图像描述符、索引化数据集、设计搜索引擎内核和执行搜索,下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
本项目采用 INRIA Holidays 数据集。包含个人假日照片、各种场景类型(自然、山、水和风景等),图像具有高分辨率。包含 500 个图像组,每组代表不同的场景或对象。第一幅图像是查询图像,正确的检索结果是该组的其他图像。
该数据集提供了未经处理的图像以及按不同方法提取的图像特征,本项目采用未经处理的数据集,下载网址:http://lear.inrialpes.fr/~jegou/data.php。也可以从我的资源库里面下载。
2. 定义图像描述符
本项目采用颜色空间描述符和构图空间描述符。
1) 定义颜色空间描述符
类成员 bins:记录 HSV 色彩空间生成的色相、饱和度及明度分布直方图的最佳 bins 分配。bins 分配过多则导致程序效率低下,匹配难度和匹配要求过分苛严;过少则导致匹配精度不足,不能表证图像特征。
成员函数 getHistogram(self, image, mask, isCenter):生成图像的色彩特征分布直方图。
Image:待处理图像,mask:图像处理区域的掩模,isCenter:判断是否为图像中心,从而有效地对色彩特征向量做加权处理。权重 weight 取 5.0。采用 OpenCV 的 calcHist()方法获得直方图,normalize()方法归一化。
# 颜色空间特征提取器
import cv2
import numpy
class ColorDescriptor:
__slot__ = ["bins"]
def __init__(self, bins):
self.bins = bins
# 得到图片的色彩直方图,mask为图像处理区域的掩模
def getHistogram(self, image, mask, isCenter):
# 利用OpenCV中的calcHist得到图片的直方图
imageHistogram = cv2.calcHist([image], [0, 1, 2], mask, self.bins, [0, 180, 0, 256, 0, 256])
# 标准化(归一化)直方图normalize
imageHistogram = cv2.normalize(imageHistogram, imageHistogram).flatten()
# isCenter判断是否为中间点,对色彩特征向量进行加权处理
if isCenter:
weight = 5.0 # 权重记为0.5
for index in range(len(imageHistogram)):
imageHistogram[index] *= weight
return imageHistogram
# 将图像从BGR色彩空间转换为HSV色彩空间
def describe(self, image):
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
features = []
# 获取图片的中心点和图片的大小
height, width = image.shape[0], image.shape[1]
centerX, centerY = int(width * 0.5), int(height * 0.5)
# initialize mask dimension
# 生成左上、右上、左下、右下、中心部分的掩模。
# 中心部分掩模的形状为椭圆形。这样能够有效区分中心部分和边缘部分,从而在getHistogram()方法中对不同部位的色彩特征做加权处理。
segments = [(0, centerX, 0, centerY), (0, centerX, centerY, height), (centerX, width, 0, centerY),
(centerX, width, centerY, height)]
# 初始化中心部分
axesX, axesY = int(width * 0.75) / 2, int(height * 0.75) / 2
ellipseMask = numpy.zeros([height, width], dtype="uint8")
cv2.ellipse(ellipseMask, (int(centerX), int(centerY)), (int(axesX), int(axesY)), 0, 0, 360, 255, -1)
# cv2.ellipse(ellipMask, (int(cX), int(cY)), (int(axesX), int(axesY)), 0, 0, 360, 255, -1)
# 初始化边缘部分
for startX, endX, startY, endY in segments:
cornerMask = numpy.zeros([height, width], dtype="uint8")
cv2.rectangle(cornerMask, (startX, startY), (endX, endY), 255, -1)
cornerMask = cv2.subtract(cornerMask, ellipseMask)
# 得到边缘部分的直方图
imageHistogram = self.getHistogram(image, cornerMask, False)
features.append(imageHistogram)
# 得到中心部分的椭圆直方图
imageHistogram = self.getHistogram(image, ellipseMask, True)
features.append(imageHistogram)
# 得到最终的特征值
return features
2) 定义构图空间描述符
类成员 dimension:将所有图片归一化(降低采样)为 dimension 所规定的尺寸。由此才能够用于统一的匹配和构图空间特征的生成。
# 构图空间提取器
import cv2
# 将图片进行归一化处理,返回HSV色彩空间矩阵
class StructureDescriptor:
__slot__ = ["dimension"]
def __init__(self, dimension):
self.dimension = dimension
def describe(self, image):
image = cv2.resize(image, self.dimension, interpolation=cv2.INTER_CUBIC)
# 将图片转化为BGR图片转化为HSV格式
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# print(image)
return image
3. 索引化数据集
对数据集中的每幅图像提取特征(HSV),并将保存在.csv 文件中,只需搜索其特征向量即可。本项目提取两个特征,分别保存在两个.csv 文件中:color_index.csv 为色彩空间特征,structure_index.csv 为构图空间特征。
#索引化数据集
import color_descriptor
import structure_descriptor
import glob
import argparse
import cv2
# 创建解析函数
searchArgParser = argparse.ArgumentParser()
searchArgParser.add_argument("-d", "--dataset", required=True,
help="Path to the directory that contains the images to be indexed")
searchArgParser.add_argument("-c", "--colorindex", required=True,
help="Path to where the computed color index will be stored")
searchArgParser.add_argument("-s", "--structureindex", required=True,
help="Path to where the computed structure index will be stored")
arguments = vars(searchArgParser.parse_args())
idealBins = (8, 12, 3)
colorDesriptor = color_descriptor.ColorDescriptor(idealBins)
output = open(arguments["colorindex"], "w")
# 色彩空间的特征存储
for imagePath in glob.glob(arguments["dataset"] + "/*.png"):
imageName = imagePath[imagePath.rfind("\\") + 1:] # 这里也是需要修改的
image = cv2.imread(imagePath)
features = colorDesriptor.describe(image)
# 将色彩空间的特征写入到csv文件中去
features = [str(feature).replace("\n", "") for feature in features]
output.write("%s,%s\n" % (imageName, ",".join(features)))
# close index file
output.close()
idealDimension = (16, 16)
structureDescriptor = structure_descriptor.StructureDescriptor(idealDimension)
output = open(arguments["structureindex"], "w")
# 构图空间的色彩特征存储
for imagePath in glob.glob("dataset" + "/*.png"):
imageName = imagePath[imagePath.rfind("\\") + 1:]
image = cv2.imread(imagePath)
structures = structureDescriptor.describe(image)
# 将构图空间的色彩特征写入到文件中去
structures = [str(structure).replace("\n", "") for structure in structures]
output.write("%s,%s\n" % (imageName, ",".join(structures)))
# close index file
output.close()
4. 设计搜索引擎内核
类成员 colorIndexPath 和 structureIndexPath:记录色彩空间特征索引表路径和结构特征索引表路径。
成员函数 solveColorDistance(self,features,queryFeatures,eps = 1e-5):求 features和queryFeatures 特征向量的二范数,eps 是为避免除零错误。
成员函数 solveStructureDistance(self,structures,queryStructures,eps = 1e-5):同样是求特征向量的二范数。需作统一化处理,color 和 structure 特征向量距离相对比例适中,不可过分偏颇。
成员函数 searchByColor(self,queryFeatures)。使用 csv 模块的 reader 方法读入索引表数据:采用 re 的 split 方法解析数据格式。用字典 searchResults 存储 query 图像与库中图像的距离,键为图库内图像名 imageName,值为距离 distance。
成员函数 transformRawQuery(self,rawQueryStructures):将未处理的 query 图像矩阵转为用于匹配的特征向量形式。
成员函数 search(self, queryFeatures,rawQueryStructures,limit = 3):将searchByColor方法和 searchByStructure 的结果汇总,获得总匹配分值,分值越低代表综合距离越小,匹配程度越高,返回前 limit 个最佳匹配图像。
# 图片搜索内核
import numpy
import csv
import re
class Searcher:
# colorIndexPath色彩空间特征索引表路径,structureIndexPath结构特征索引表路径
__slot__ = ["colorIndexPath", "structureIndexPath"]
def __init__(self, colorIndexPath, structureIndexPath):
self.colorIndexPath, self.structureIndexPath = colorIndexPath, structureIndexPath
# 计算色彩空间的距离,卡方相似度计算
def solveColorDistance(self, features, queryFeatures, eps=1e-5):
distance = 0.5 * numpy.sum([((a - b) ** 2) / (a + b + eps) for a, b in zip(features, queryFeatures)])
return distance
# 计算构图空间的距离
def solveStructureDistance(self, structures, queryStructures, eps=1e-5):
distance = 0
normalizeRatio = 5e3
for index in range(len(queryStructures)):
for subIndex in range(len(queryStructures[index])):
a = structures[index][subIndex]
b = queryStructures[index][subIndex]
distance += (a - b) ** 2 / (a + b + eps)
return distance / normalizeRatio
def searchByColor(self, queryFeatures):
searchResults = {}
with open(self.colorIndexPath) as indexFile:
reader = csv.reader(indexFile)
for line in reader:
features = []
for feature in line[1:]:
feature = feature.replace("[", "").replace("]", "")
findStartPosition = 0
feature = re.split("\s+", feature)
rmlist = []
for index, strValue in enumerate(feature):
if strValue == "":
rmlist.append(index)
for _ in range(len(rmlist)):
currentIndex = rmlist[-1]
rmlist.pop()
del feature[currentIndex]
feature = [float(eachValue) for eachValue in feature]
features.append(feature)
distance = self.solveColorDistance(features, queryFeatures)
searchResults[line[0]] = distance
indexFile.close()
# print "feature", sorted(searchResults.iteritems(), key = lambda item: item[1], reverse = False)
return searchResults
def transformRawQuery(self, rawQueryStructures):
queryStructures = []
for substructure in rawQueryStructures:
structure = []
for line in substructure:
for tripleColor in line:
structure.append(float(tripleColor))
queryStructures.append(structure)
return queryStructures
def searchByStructure(self, rawQueryStructures):
searchResults = {}
queryStructures = self.transformRawQuery(rawQueryStructures)
with open(self.structureIndexPath) as indexFile:
reader = csv.reader(indexFile)
for line in reader:
structures = []
for structure in line[1:]:
structure = structure.replace("[", "").replace("]", "")
structure = re.split("\s+", structure)
if structure[0] == "":
structure = structure[1:]
structure = [float(eachValue) for eachValue in structure]
structures.append(structure)
distance = self.solveStructureDistance(structures, queryStructures)
searchResults[line[0]] = distance
indexFile.close()
# print "structure", sorted(searchResults.iteritems(), key = lambda item: item[1], reverse = False)
return searchResults
def search(self, queryFeatures, rawQueryStructures, limit=10):
featureResults = self.searchByColor(queryFeatures)
structureResults = self.searchByStructure(rawQueryStructures)
results = {}
#for key, value in featureResults.items():
# results[key] = value + structureResults[key]
for key, value in structureResults.items():
results[key] = value + featureResults[key]
results = sorted(results.items(), key=lambda item: item[1], reverse=False)
return results[: limit]
5. 执行搜索
引入 color_descriptor 和 structure_descriptor。用于解析待匹配(搜索)的图像,获得色彩空间特征向量和构图空间特征向量。用 argparse 设置命令行参数。参数包括图片库路径、色彩空间特征索引表路径、构图空间特征索引表路径、待搜索图片路径,成索引表文本并写入.csv 文件。
# 执行搜索
import color_descriptor
import structure_descriptor
import searcher
import argparse
import cv2
# 构造解析函数
searchArgParser = argparse.ArgumentParser()
searchArgParser.add_argument("-c", "--colorindex", required=True,
help="Path to where the computed color index will be stored")
searchArgParser.add_argument("-s", "--structureindex", required=True,
help="Path to where the computed structure index will be stored")
searchArgParser.add_argument("-q", "--query", required=True, help="Path to the query image")
searchArgParser.add_argument("-r", "--resultpath", required=True, help="Path to the result path")
searchArguments = vars(searchArgParser.parse_args())
idealBins = (8, 12, 3)
idealDimension = (16, 16)
# 传入色彩空间的bins
colorDescriptor = color_descriptor.ColorDescriptor(idealBins)
# 传入构图空间的bins
structureDescriptor = structure_descriptor.StructureDescriptor(idealDimension)
queryImage = cv2.imread(searchArguments["query"])
colorIndexPath = searchArguments["colorindex"]
structureIndexPath = searchArguments["structureindex"]
resultPath = searchArguments["resultpath"]
queryFeatures = colorDescriptor.describe(queryImage)
queryStructures = structureDescriptor.describe(queryImage)
imageSearcher = searcher.Searcher(colorIndexPath, structureIndexPath)
searchResults = imageSearcher.search(queryFeatures, queryStructures)
cv2.imshow("Query", queryImage)
cv2.waitKey(0)
# 对搜索到的图片进行展示
for imageName, score in searchResults:
queryResult = cv2.imread(resultPath + "/" + imageName)
cv2.imshow("Result Score: " + str(100-int(score)), queryResult)#转换评分
cv2.waitKey(0)
系统测试
本部分包括处理数据集和执行搜索。
1. 处理数据集
对 INRIA Holidays 数据集进行处理,分别提取色彩空间特征和构图空间特征,得到两个CSV 文件,如图 1和图 2所示。这里给出示例图像 100002.png,如图3所示,色彩空间特征如图 4 所示。在终端输入以下指令:
python index.py --dataset dataset --colorindex color_index.csv --structure structure_index.csv
dataset 为图片库路径,color_index.csv 为色彩空间特征索引表路径,structure_index.csv为构图空间特征索引表路径。




2. 执行搜索
给定待搜索图像,搜索机制对其进行特征提取、比对,匹配后输出结果并评分,同时可调节输出结果的个数。待搜索如图5所示、搜索结果原图最优如图6所示。
在终端输入以下命令:
python searchEngine.py -c color_index.csv -s structure_index.csv -r dataset -q query/pyramid.jpg
dataset 为图片库路径,color_index.csv 为色彩空间特征索引表路径。structure_index.csv为构图空间特征索引表路径,query/pyramid.jpg 为待搜索图片路径。这里给出示例图像100002.png 的搜索结果,输出结果个数为 3。


工程源代码下载
详见资源下载文章来源:https://www.toymoban.com/news/detail-476111.html
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。文章来源地址https://www.toymoban.com/news/detail-476111.html
到了这里,关于基于Python+OpenCV的图像搜索引擎(CBIR+深度学习+机器视觉)含全部工程源码及图片数据库下载资源的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!